GraphRAG:基于PolarDB+通义千问api+LangChain的知识图谱定制实践

在当今这个数字化时代,大型语言模型(LLM)的发展突飞猛进,国内外涌现的大型语言模型(LLM)可谓是百花齐放,不管是开源还是闭源都出现了一些非常优秀的模型,然而在利用LLM进行应用开发的时候,会发现每个模型从部署、到训练、微调、API接口开发、Prompt提示词格式等方面都存在或多或少的差异,导致如果一个产品需要接入不同的LLM或者快速切换模型的时候变得更加复杂,使用没有那么方便,也不便于维护。然而,尽管 LLM 取得了巨大的进步,但面对如此多的LLM,给开发者带来了巨大的挑战,我们调用这些LLM模型时,需要查阅大量API接口文档和编写测试代码调试,而且还很容易错误地使用 API 调用。为了解决这一问题,Gorilla LLM 应运而生,它是一种基于 LLaMA 的微调模型,旨在将大型语言模型与各种通过 API 提供的服务和应用程序连接起来。Gorilla LLM 的出现弥补了传统方法的不足,它在编写 API 调用方面表现优于 GPT-4,并且能够适应测试时文档的变化,实现灵活的 API 更新和版本更改。此外,Gorilla 还有效地解决了直接提示 LLM 时常见的幻觉问题。通过引入 APIBench,一个由 HuggingFace、TorchHub 和 TensorHub API 组成的综合数据集,我们可以评估 Gorilla LLM 的性能。成功将检索系统与 Gorilla 集成后,LLM 可以更准确地使用工具,跟上频繁更新的文档,从而提高其输出的可靠性和适用性。
Gorilla LLM 是一种先进的大型语言模型(LLM),旨在通过解释自然语言查询来理解并准确调用1,600多个API。它通过使用自我指导和检索技术,选择和利用具有重叠和不断发展功能的工具。Gorilla使用全面的APIBench数据集进行评估,并在生成API调用方面超越了GPT-4的性能。Gorilla LLM是一个与API连接的大型语言模型(LLM)。它经过大量API文档的训练,可以根据给定的自然语言问题构建正确的API调用,包括正确的输入参数。相比之前的API调用技术,Gorilla更准确,并且不太可能产生错误的API调用幻觉。对于希望自动化操作或使用API构建应用程序的开发人员来说,Gorilla是一个有用的工具。同时,对于在自然语言处理中使用API感兴趣的研究人员也可以利用它。Gorilla LLM由加州大学伯克利分校和微软的研究人员开发。它专为API调用而设计,可以生成语义和语法正确的API调用来响应自然语言查询。例如,当您询问Gorilla“获取北京的天气”时,它将生成对OpenWeatherMap API的调用,以获取旧金山当前的天气状况。Gorilla LLM经过在Torch Hub、TensorFlow Hub和HuggingFace等大型机器学习中心数据集上的训练。目前正在快速添加新领域,包括Kubernetes、GCP、AWS、OpenAPI等。Gorilla的性能优于GPT-4、Chat-GPT和Claude,并且具有显著减少幻觉错误的可靠性。最后,Gorilla LLM采用Apache 2.0许可证,并在MPT和Falcon上进行微调,因此您可以在商业用途中使用Gorilla而无需承担任何义务。
Gorilla LLM具有以下主要特性:
Gorilla LLM通过准确调用API、减少幻觉错误、用户友好且可适应各种需求和工具、开源并通过社区贡献不断发展以及与其他工具的集成等特性,为开发人员提供了一个强大而灵活的API调用生成解决方案。
Gorilla可以应用于以下场景:
Gorilla可以在创建新的API、更新现有API以支持新功能以及调试无法正常工作的API调用等场景中发挥作用。它通过教导LLM正确的参数和上下文,帮助开发人员更高效地进行API集成和调试工作。
LLM的应用价值在于解决了与API集成和任务完成相关的挑战。传统的解决方案通常基于提示,无法处理规模庞大且不断变化的API。同时,找到适合特定任务的正确API和参数也是一个困难。这不仅限于专门的API,还包括常用服务如AWS、GCP和Azure等,每个服务都提供数千个API,每个API又有多个不同的输入参数。当前的解决方法要么依赖人类专家,要么需要耗时搜索API文档和在线资源,导致构建复杂应用程序的流程效率低下且难以管理。为了解决这个问题,Gorilla应运而生。我们相信,如果能够教会LLM如何使用正确的参数和上下文进行API调用,就可以轻松连接构建强大的LLM驱动应用程序所需的所有工具。Gorilla的目标是通过将LLM与各种工具集成,实现更高效和便捷的应用程序开发。Gorilla的应用价值体现在以下几个方面:
总而言之,Gorilla通过解决API集成和任务完成相关的挑战,提供了一种更高效、便捷的方式来构建强大的LLM驱动应用程序。同时,Gorilla 可用于执行多种任务,包括:创建文本、翻译语言、响应查询、创建多种类型的创意材料、访问和处理来自各种来源的信息。
Gorilla LLM相比早期传统的方法具有以下优势:
当与文档检索系统配合使用特定 API 的提示进行查询时,该模型比其他LLM表现更好,增强了其输出的可靠性和适用性。下图突出显示了这样的结果:
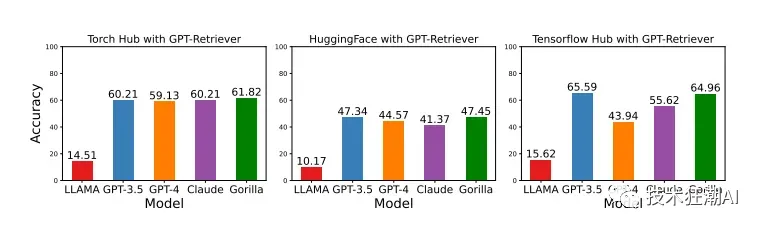
Gorilla LLM通过提高精度、减少幻觉错误、节省时间和工作量、增强可靠性以及处理有约束的API等方面的优势,为开发人员提供了更高效、准确和可靠的API调用生成能力。
目前来看,流行的开源模型非常多,Gorilla 为什么选择 LLaMA 而不是其他模型?是否对多个模型进行了微调和测试?之所以选择 LLaMA 作为起点,因为它被认为是开源LLM的主力。许多其他模型都是其针对特定应用的衍生模型。当然,Gorilla 也使用了 GPT-4、GPT-3.5 和 Claude-v1 对 Gorilla 进行了基准测试。因为考虑到开源模型可商用的情况,后续又发布了两款基于 MPT-7B 和 Falcon-7B 的 Gorilla 模型。现在 Gorilla 模型使用 Apache 2.0 许可证,这意味着 Gorilla 可以在没有任何约束的情况下用于商业用途!
训练 Gorilla 需要的硬件条件据官方介绍使用 8 个 A100 40GB GPU 节点来训练和评估所有模型。根据模型和 API 数据集的不同,所需时间差异很大。最短的运行总计大约 10 个 GPU 小时,而最长的运行大约 120 个 GPU 小时。同时训练过程也使用了所有最先进的计算技术(高效的注意力机制)和内存优化(分片、检查点和混合精度训练)。没有使用 LoRA,所有 Gorilla 模型都经过端到端微调。
Gorilla LLM 接受过海量 API 文档和代码数据集的培训。该数据集包括来自各种不同平台的 API 调用,例如 Google Cloud Platform、Amazon Web Services 和 Microsoft Azure。 Gorilla 使用此数据集来学习 API 调用的语法和语义。当你要求 Gorilla 生成 API 调用时,它会首先尝试在其数据集中查找匹配的 API 调用。如果它找到匹配的 API 调用,它将简单地返回该调用。如果它没有找到匹配的 API 调用,它将根据其对 API 语法和语义的了解生成新的 API 调用。以下是 Gorilla 连接 API 的过程涉及几个关键步骤:
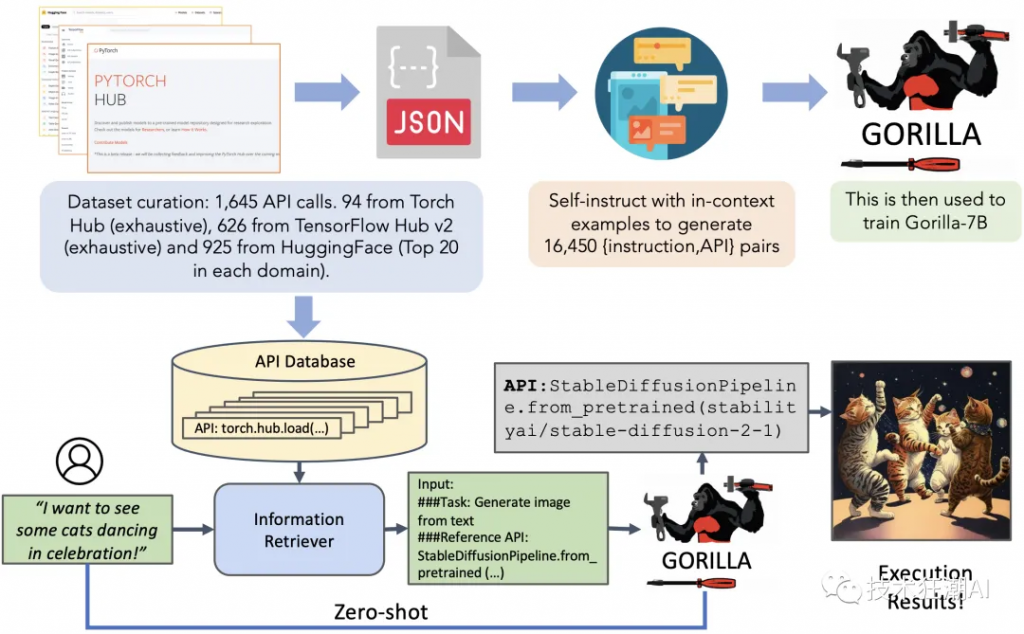
值得注意的是,Gorilla 具有很强的适应性,可以在零样本和检索模式下运行,使其能够适应 API 文档的变化并随着时间的推移保持准确性。第一个(也是最流行的)是零样本模式。在这种情况下,Gorilla 以自然语言接受用户的查询,并返回正确的 API 进行调用。现在,在很多场景中,您经常会看到 API 随着时间的推移而演变 – 这可能是版本控制,或者端点可能会发生变化,或者参数可能会被重新洗牌,或者其中一些可能会被弃用。为了使我们的系统对此具有鲁棒性,我们引入了第二种使用 Gorilla 的模式 – 检索器感知。在这种情况下,Gorilla 会选择最相关的 API,然后将其附加到用户的提示中。这使我们能够了解 API 的变化。
要使用 Gorilla LLM,必须安装 Python 3.10 或更高版本。早期版本的 Python 无法编译。
如果是全新的服务器,首次需要安装Conda,在终端中,使用以下命令下载Miniconda安装脚本:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh使用以下命令运行安装脚本:
bash Miniconda3-latest-Linux-x86_64.sh按照安装程序的提示进行安装。您可以选择安装位置和环境变量设置等选项。安装完成后,使用以下命令激活conda环境:
source ~/.bashrc使用以下命令检查conda是否成功安装:
conda --version如果conda成功安装,您将看到conda的版本号,我这里安装的是conda 23.5.2。
conda create -n gorilla python=3.10conda activate gorillapip install -r requirements.txthttps://huggingface.co/docs/transformers/main/model_doc/llama
https://huggingface.co/gorilla-llm/gorilla-7b-hf-delta-v1
将以下 Python 命令中的占位符替换为正确的文件路径:
python3 apply_delta.py
--base-model-path path/to/hf_llama/
--target-model-path path/to/gorilla-falcon-7b-hf-v0
--delta-path path/to/models--gorilla-llm--gorilla-7b-hf-delta-v1使用此命令将增量权重应用于您的 LLaMA 模型。
python3 serve/gorilla_falcon_cli.py --model-path path/to/gorilla-falcon-7b-hf-v0
# 如果您在使用 Apple 芯片(M1、M2 等)的 Mac 上运行,请添加 “--device mps”path/to/gorilla-7b-hf,th,tf-v0 应替换为 Gorilla 模型的真实路径。api 子目录中的每个文件代表一个 API,标题为 {api_name}_api.jsonl 。apibench 子文件夹包含 LLM 模型训练和评估数据集。它包含文件 {api_name}_train.jsonl 和 {api_name}_eval.jsonl 。apizoo 子目录中找到。README.md 文件包含有关评估过程的说明或数据。get_llm_responses.py 脚本。eval-scripts 包含每个 API 的评估脚本例如 ast_eval_{api_name}.py 。responses_{api_name}Gorilla_FT{eval_metric}.jsonl 和 responses_{api_name}Gorilla_RT{eval_metric} .jsonl 的文件。questions 子目录中,每个 API 文件夹都有标题为 questions_{api_name}_{eval_metric}.jsonl 的文件。questions 子文件夹中的问题文件按 API 名称和评估指标组织。responses 子文件夹中。README.md 文件很可能包含执行推理代码的指令。serve 子目录包含 Gorilla 命令行界面 (CLI) 脚本和聊天模板。train 文件夹标记为“即将推出!”并且很可能应该包含 Gorilla 模型训练代码。但是,该文件夹现在似乎不可用。您可以参考每个文件夹中的自述文件,以获取有关使用提供的代码和数据集的更具体说明和信息。
首先,使用pip安装OpenAI
pip install openai像这样配置 api_key 和 api_base
import openai
openai.api_key = "EMPTY" # key可以忽略
openai.api_base = "http://34.132.127.197:8000/v1" #http://zanino.millennium.berkeley.edu:8000/v1 使用 OpenAI 库创建获取 Gorilla 结果的函数
def get_gorilla_response(prompt="我想把英语翻译成中文。", model="gorilla-falcon-7b-hf-v0"):
completion = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
return completion.choices[0].message.content执行发送提示的函数和您想要使用的模型,在本例中为 gorilla-falcon-7b-hf-v0。
prompt = "我想从英语翻译成中文。"
print(get_gorilla_response(prompt, model="gorilla-falcon-7b-hf-v0" ))就是这样。然后,您将收到来自 Huggingface API 的完整信息以及有关如何执行该请求的说明。
<<<domain>>>: Natural Language Processing Translation
<<<api_call>>>: pipeline('translation_en_to_zh', model='Helsinki-NLP/opus-mt-en-zh') <<<api_provider>>>: Hugging Face Transformers
<<<explanation>>>:
1. Import the pipeline function from the transformers library provided by Hugging Face.
2. Use the pipeline function to create a translation model, specifying the model 'Helsinki-NLP/opus-mt-en-zh' to be loaded. This model is trained to translate text from English to Chinese.
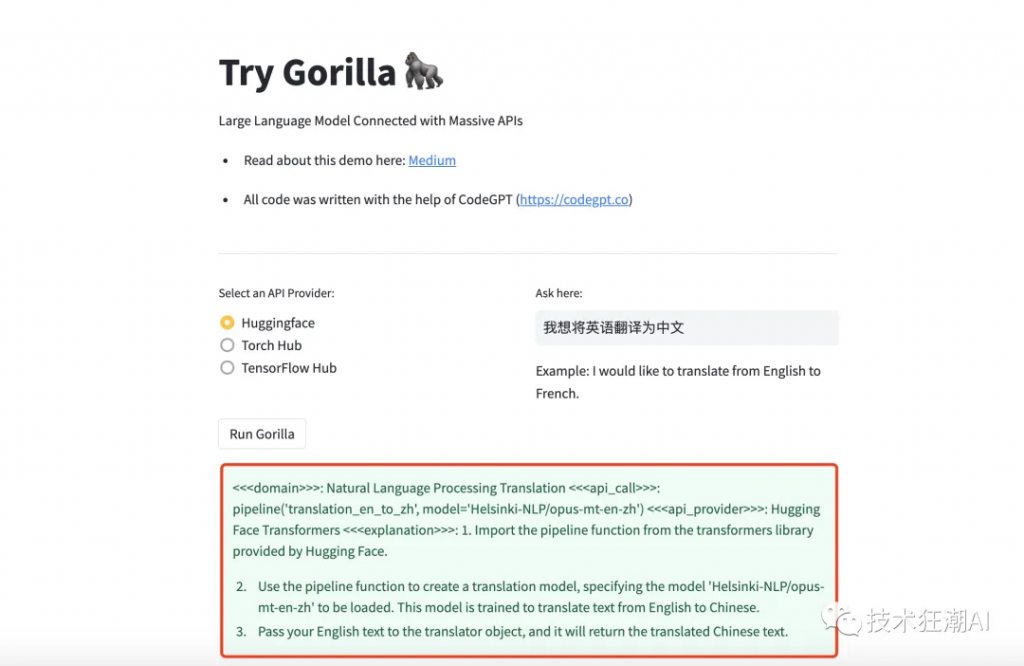
3. Pass your English text to the translator object, and it will return the translated Chinese text.Gorilla HuggingFace Demo:https://huggingface.co/spaces/davila7/try-gorilla?source=post_page
# 对象检测
prompt = "我想构建一个可以检测图像“cat.jpeg”中对象的机器人。输入:['cat.jpeg']"
print(get_gorilla_response(prompt, model="gorilla-falcon-7b-hf-v0"))输出结果:
<<<domain>>>: Computer Vision Object Detection
<<<api_call>>>: model = DetrForObjectDetection.from_pretrained('facebook/detr-resnet-101-dc5')
<<<api_provider>>>: Hugging Face Transformers
<<<explanation>>>: 1. Import the necessary components from the Hugging Face Transformers library, torch, and PIL (Python Imaging Library).
2. Open the image using PIL's Image.open() function with the provided image path.
3. Initialize the pretrained DETR (DEtection TRansformer) model and the image processor.
4. Generate inputs for the model using the image processor.
5. Pass the inputs to the model, which returns object detection results.
<<<code>>>:
from transformers import AutoFeatureExtractor, AutoModelForObjectDetection
from PIL import Image
import torch
def load_model():
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/detr-resnet-101-dc5')
model = AutoModelForObjectDetection.from_pretrained('facebook/detr-resnet-101-dc5')
return feature_extractor, model
def process_data(image_path, feature_extractor, model):
image = Image.open(image_path)
inputs = feature_extractor(images=image, return_tensors='pt')
outputs = model(**inputs)
results = feature_extractor.post_process(outputs, threshold=0.6)[0]
response = [model.config.id2label[label.item()] for label in results['labels']]
return response
image_path = 'cat.jpeg'
# Load the model and feature extractor
feature_extractor, model = load_model()
# Process the data
response = process_data(image_path, feature_extractor, model)
print(response)# Torch Hub 翻译
prompt = "我想把英语翻译成汉语。"
print(get_gorilla_response(prompt, model="gorilla-falcon-7b-hf-v0"))输出结果:
{'domain': 'Machine Translation', 'api_call': \"model = torch.hub.load('pytorch/fairseq在 Gorilla api 数据集上微调 ChatGPT-3.5 以尝试提高其性能,关于OpenAI ChatGPT-3.5 微调文档可以访问这里:
https://platform.openai.com/docs/guides/fine-tuning注意:这个微调脚本将在 OpenAI 上训练 720 万个 token,需要花费一定的费用,请在继续之前先考虑清楚是否愿意支付这笔费用。
pip install openai tiktokenimport re
import os
import json
import openai
from pprint import pprintopenai_api_key = "OPENAI API KEY"
openai.api_key = openai_api_key下载 Gorrilla Huggingface api 训练数据,可以在这里找到所有 Gorilla 训练数据:https://github.com/ShishirPatil/gorilla/tree/main/data/apibench
wget https://raw.githubusercontent.com/ShishirPatil/gorilla/cab053ba7fdf4a3286c0e75aa2bf7abc4053812f/data/apibench/huggingface_train.jsondata = []
with open("huggingface_train.json", "r") as file:
# data = json.load(file)
for line in file:
item = json.loads(line.strip())
data.append(item)
# 这是与训练有关的数据
data[0]["code"]解析训练数据指令
def parse_instructions_and_outputs(code_section):
sections = code_section.split('###')
for section in sections:
if "Instruction:" in section:
instruction = section.split("Instruction:", 1)[1].strip()
break
domain = re.search(r'<<<domain>>>(.*?)\n', code_section, re.IGNORECASE).group(1).lstrip(': ')
api_call = re.search(r'<<<api_call>>>(.*?)\n', code_section, re.IGNORECASE).group(1).lstrip(': ')
api_provider = re.search(r'<<<api_provider>>>(.*?)\n', code_section, re.IGNORECASE).group(1).lstrip(': ')
if "<<<explanation>>>" in code_section:
explanation_pattern = r'<<<explanation>>>(.*?)(?:\n<<<code>>>|```|$)'
explanation = re.search(explanation_pattern, code_section, re.DOTALL).group(1).lstrip(': ')
else:
explanation = None
# 考虑两种情况提取代码片段
code_pattern = r'(?:<<<code>>>|```) (.*)' # 匹配 <<<code>>> 或 ```
code_snippet_match = re.search(code_pattern, code_section, re.DOTALL)
code_snippet = code_snippet_match.group(1).lstrip(': ') if code_snippet_match else None
return instruction, domain, api_call, api_provider, explanation, code_snippetdef encode_train_sample(data, api_name):
"""将多个提示指令编码为单个字符串。"""
code_section = data['code']
if "<<<api_call>>>" in code_section:
instruction, domain, api_call, api_provider, explanation, code = parse_instructions_and_outputs(code_section)
prompts = []
#prompt = instruction + "\nWrite a python program in 1 to 2 lines to call API in " + api_name + ".\n\nThe answer should follow the format: <<<domain>>> $DOMAIN, <<<api_call>>>: $API_CALL, <<<api_provider>>>: $API_PROVIDER, <<<explanation>>>: $EXPLANATION, <<<code>>>: $CODE}. Here are the requirements:\n" + domains + "\n2. The $API_CALL should have only 1 line of code that calls api.\n3. The $API_PROVIDER should be the programming framework used.\n4. $EXPLANATION should be a step-by-step explanation.\n5. The $CODE is the python code.\n6. Do not repeat the format in your answer."
prompts.append({"role": "system", "content": "你是一个有厉害的API开发人员,可以根据需求编写API。"})
prompts.append({"role": "user", "content": instruction})
prompts.append({"role": "assistant", "content": f"<<<domain>>> {domain},\
<<<api_call>>>: {api_call}, <<<api_provider>>>: {api_provider}, <<<explanation>>>: {explanation}, <<<code>>>: {code}"})
return prompts
else:
return None使用正确的格式格式化训练样本以反映 Gorilla 论文
encoded_data = []
none_count = 0
for d in data:
res = encode_train_sample(d, "huggingface")
if res is not None:
encoded_data.append({"messages":res})
else:
none_count += 1
print(f"{none_count} samples out of {len(data)} ignored")打印将传递给 OpenAI 进行微调的样本
encoded_data[3]输出结果:
{'messages': [{'role': 'system',
'content': 'You are a helpful API writer who can write APIs based on requirements.'},
{'role': 'user',
'content': 'I run an online art store and I want to classify the art pieces uploaded by the users into different categories like abstract, landscape, portrait etc.'},
{'role': 'assistant',
'content': "<<<domain>>> Computer Vision Image Classification,<<<api_call>>>: ViTModel.from_pretrained('facebook/dino-vits8'), <<<api_provider>>>: Hugging Face Transformers, <<<explanation>>>: 1. We first import the necessary classes from the transformers and PIL packages. This includes ViTModel for the image classification model and Image for processing image data.\n2. We then use the from_pretrained method of the ViTModel class to load the pre-trained model 'facebook/dino-vits8'. This model has been trained using the DINO method which is particularly useful for getting good features for image classification tasks.\n3. We load the image data from an uploaded image file by the user.\n4. This model can then be used to classify the image into different art categories like 'abstract', 'landscape', 'portrait' etc., <<<code>>>: None"}]}# 我们从导入所需的包开始
import json
import os
import tiktoken
import numpy as np
from collections import defaultdict
# 接下来,我们指定数据通路并打开JSONL文件
data_path = encoded_file_path
# 加载数据集
with open(data_path) as f:
dataset = [json.loads(line) for line in f]
# 我们可以通过检查示例数量和第一项来快速检查数据
# 初始数据集统计信息
print("Num examples:", len(dataset))
print("First example:")
for message in dataset[0]["messages"]:
print(message)
# 现在我们对数据有了了解,我们需要遍历所有不同的示例并检查以确保格式正确并与Chat完成消息结构匹配
# 格式错误检查
format_errors = defaultdict(int)
for ex in dataset:
if not isinstance(ex, dict):
format_errors["data_type"] += 1
continue
messages = ex.get("messages", None)
if not messages:
format_errors["missing_messages_list"] += 1
continue
for message in messages:
if "role" not in message or "content" not in message:
format_errors["message_missing_key"] += 1
if any(k not in ("role", "content", "name") for k in message):
format_errors["message_unrecognized_key"] += 1
if message.get("role", None) not in ("system", "user", "assistant"):
format_errors["unrecognized_role"] += 1
content = message.get("content", None)
if not content or not isinstance(content, str):
format_errors["missing_content"] += 1
if not any(message.get("role", None) == "assistant" for message in messages):
format_errors["example_missing_assistant_message"] += 1
if format_errors:
print("Found errors:")
for k, v in format_errors.items():
print(f"{k}: {v}")
else:
print("No errors found")
# 除了消息的结构之外,我们还需要确保长度不超过4096令牌限制。
# Token 计数功能
encoding = tiktoken.get_encoding("cl100k_base")
def num_tokens_from_messages(messages, tokens_per_message=3, tokens_per_name=1):
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3
return num_tokens
def num_assistant_tokens_from_messages(messages):
num_tokens = 0
for message in messages:
if message["role"] == "assistant":
num_tokens += len(encoding.encode(message["content"]))
return num_tokens
def print_distribution(values, name):
print(f"\n#### Distribution of {name}:")
print(f"min / max: {min(values)}, {max(values)}")
print(f"mean / median: {np.mean(values)}, {np.median(values)}")
print(f"p5 / p95: {np.quantile(values, 0.1)}, {np.quantile(values, 0.9)}")
# 最后,在继续创建微调作业之前,我们可以查看不同格式化操作的结果:
# 警告和token计数
n_missing_system = 0
n_missing_user = 0
n_messages = []
convo_lens = []
assistant_message_lens = []
for ex in dataset:
messages = ex["messages"]
if not any(message["role"] == "system" for message in messages):
n_missing_system += 1
if not any(message["role"] == "user" for message in messages):
n_missing_user += 1
n_messages.append(len(messages))
convo_lens.append(num_tokens_from_messages(messages))
assistant_message_lens.append(num_assistant_tokens_from_messages(messages))
print("缺少系统消息的示例数:", n_missing_system)
print("缺少用户消息的数字示例:", n_missing_user)
print_distribution(n_messages, "num_messages_per_example")
print_distribution(convo_lens, "num_total_tokens_per_example")
print_distribution(assistant_message_lens, "num_assistant_tokens_per_example")
n_too_long = sum(l > 4096 for l in convo_lens)
print(f"\n{n_too_long} 示例可能超过4096令牌限制,它们将在微调期间被截断")
# 定价和违约n_epochs估计
MAX_TOKENS_PER_EXAMPLE = 4096
MIN_TARGET_EXAMPLES = 100
MAX_TARGET_EXAMPLES = 25000
TARGET_EPOCHS = 3
MIN_EPOCHS = 1
MAX_EPOCHS = 25
n_epochs = TARGET_EPOCHS
n_train_examples = len(dataset)
if n_train_examples * TARGET_EPOCHS < MIN_TARGET_EXAMPLES:
n_epochs = min(MAX_EPOCHS, MIN_TARGET_EXAMPLES // n_train_examples)
elif n_train_examples * TARGET_EPOCHS > MAX_TARGET_EXAMPLES:
n_epochs = max(MIN_EPOCHS, MAX_TARGET_EXAMPLES // n_train_examples)
n_billing_tokens_in_dataset = sum(min(MAX_TOKENS_PER_EXAMPLE, length) for length in convo_lens)
print(f"数据集有~{n_billing_tokens_in_dataset}个令牌,在训练期间将收取费用")
print(f"默认情况下,您将在此数据集上训练{n_epochs}个纪元")
print(f"默认情况下,您将收取~{n_epochs*n_billing_tokens_in_dataset}代币的费用")
print("请参阅定价页面以估算总成本")openai.File.create(
file=open(encoded_file_path, "rb"),
purpose='fine-tune'
)创建微调任务
openai.api_key = openai_api_key
openai.FineTuningJob.create(
training_file="file-OrxAP7HcvoSUmu9MtAbWo5s4",
model="gpt-3.5-turbo"
)# 列出 10 个微调任务
openai.FineTuningJob.list(limit=10)
# 查询微调的状态
state = openai.FineTuningJob.retrieve("ftjob-qhg4yswil15TCqD4SNHn0V1D")
state["status"], state["trained_tokens"], state["finished_at"]
# 列出微调作业中最多 10 个事件
openai.FineTuningJob.list_events(id="ftjob-qhg4yswil15TCqD4SNHn0V1D", limit=10)openai.api_key = openai_api_key
completion = openai.ChatCompletion.create(
model="ft:gpt-3.5-turbo:my-org:custom_suffix:id",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "How can i load a NER model?"}
]
)
print(completion.choices[0].message)
print(completion.choices[0].message["content"])输出结果:
('To load a Named Entity Recognition (NER) model in Python, you can use the '
"Hugging Face Transformers library. Here's a step-by-step guide to loading "
'and using a NER model:\n'
'\n'
'1. Install the required Hugging Face Transformers library using "pip install '
'transformers".\n'
'2. Import the AutoModelForTokenClassification class from the transformers '
'library.\n'
'3. Import the necessary tokenizer as well, which is AutoTokenizer in this '
'case.\n'
'4. Use the from_pretrained method to load the pre-trained model with its '
'respective model name or identifier.\n'
'5. Then, use the load_tokenizer method to load the tokenizer.\n'
'6. Encode your text using the loaded tokenizer, specifying the '
"'return_tensors' parameter as 'pt'.\n"
'7. Pass the input tensor to the model and it will return the predictions, '
'describing the Named Entities in the text.\n'
'\n'
'Please keep in mind that you should download the model first, replace '
"'YOUR_MODEL_NAME' with an appropriate model identifier, and make sure to "
'execute this code on a suitable device (e.g., CPU or GPU).\n'
'\n'
'Here is how the code looks:\n'
'```python\n'
'from transformers import AutoModelForTokenClassification, AutoTokenizer\n'
'import torch\n'
'\n'
"model = AutoModelForTokenClassification.from_pretrained('YOUR_MODEL_NAME')\n"
"tokenizer = AutoTokenizer.from_pretrained('YOUR_MODEL_NAME')\n"
'\n'
'# Encode your text using the loaded tokenizer\n'
"inputs = tokenizer(text, return_tensors='pt')\n"
'\n'
'# Pass the input tensor to the model and obtain NER predictions\n'
'predictions = model(**inputs)\n'
'```\n'
'\n'
"Remember to replace 'YOUR_MODEL_NAME' with an appropriate BERT NER-trained "
"model such as 'dslim/bert-base-NER'.")Gorilla LLM 是一个突破性的LLM,可以生成准确的 API 调用并适应文档的实时变化。该模型为未来的LLM在与工具和系统交互方面变得更加可靠和多功能铺平了道路。Gorilla LLM 是一款面向开发人员的强大新工具。它可以节省开发人员的时间和精力,并且可以帮助他们编写更可靠的代码。如果您是一名开发人员,建议你可以了解一下 Gorilla LLM。LLM未来的进步可以集中在进一步减少幻觉错误、提高对不同 API 的适应性以及扩展其处理复杂任务的能力。潜在的应用包括充当计算基础设施的主要接口、自动化度假预订等流程以及促进各种 Web API 之间的无缝通信。
https://shishirpatil.github.io/gorilla/
https://github.com/ShishirPatil/gorilla
https://arxiv.org/abs/2305.15334
文章转自微信公众号@技术狂潮AI