

如何快速实现REST API集成以优化业务流程

扩散只是一种思想,扩散模型也并非固定的深度网络结构。除此之外,如果将扩散的思想融入其他领域,扩散模型同样可以发挥重要作用。
在实际应用中,扩散模型最常见、最成熟的应用就是完成图像生成任务,本书同样聚焦于此。不过即使如此,扩散模型在其他领域的应用仍不容忽视,可能在不远的将来,它们就会像在图像生成领域一样蓬勃发展,一鸣惊人。
本文将介绍扩散模型在如下领域的应用:
计算机视觉包括2D视觉和3D视觉两个方面,这里仅介绍扩散模型在2D图像领域的应用。
图像类的应用十分广泛,而且与人们的日常生活息息相关。在扩散模型出现之前,与图像处理相关的研究已经有很多了,而扩散模型在许多图像处理任务中都可以很好地发挥作用,具体如下。
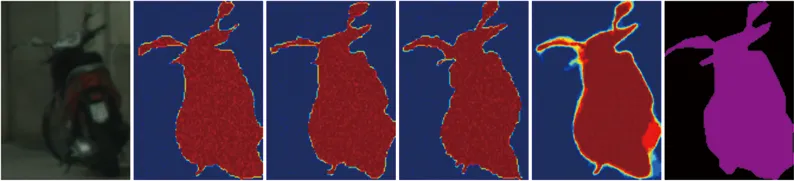
图3-1 SegDiff生成的分割Mask图

图3-2 DiffusionDet生成的检测框
图像超分钟率,图像超分钟率是一项能够将低分辨年图像重建为高分辨率图体,同时保证图像市药线贯的技术。CDM(Cascaded DiffusionModel,组联扩教模型)通过采用事联多个扩散模型的方式,分级式地逐步放大分钟率,实现了图像超分钟车,图3-3给出了一个使用CDM实现图像超分拼串的示例。

图3-3 使用CDM实现图像超分辨率


图3-4 使用Palette修复图像
时序数据预测旨在根据历史观测数据预测未来可能出现的数据,如空气温度预测、股票价格预测、销售与产能预测等。时序数据预测同样可以视为生成任务,即基于历史数据的基本条件来生成未来数据,因此扩散模型也能发挥作用。
TimeGrad是首个在多元概率时序数据预测任务中加入扩散思想的自回归模型。为了将扩散过程添加到历史数据中,TimeGrad首先使用RNN (Recurrent Neural Network,循环神经网络)处理历史数据并隐空间中,然后对历史数据添加噪声以实现扩散过程,由此处理数千维度的多元数据并完成预测任务。图3-5展示了TimeGrad在城市交通流量预测任务中的表现。
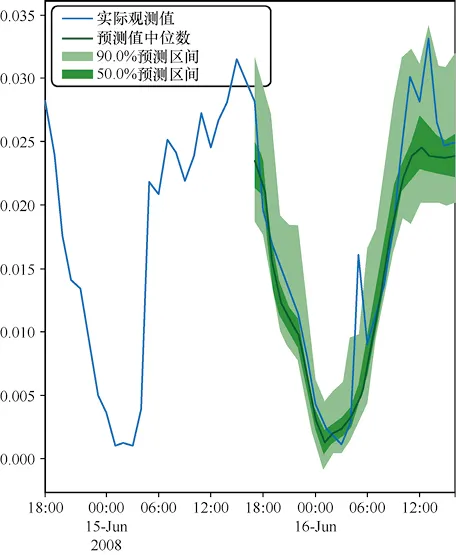
图3-5 TimeGrad在城市交通流量预测任务中的表现
时序数据预测在实际生活中的应用非常广泛。在过去,传统机器学习算法以及深度学习的RNN系列方法一直处于主导地位。如今,扩散模型以及表现出巨大的潜力,而这仅仅是个开始。
自然语言领域也是人工智能的一个重要发展方向,旨在研究人类语言与计算机通信的相关问题,最近”爆火”的ChatGPT就是一个自然语言生成问答模型。
实际上,扩散模型同样可以完成语言类的生成任务。只要将自然语言类的句子分调并转换为词向量之后,就可以通过扩散的方法来学习自然语言的语句生成,进而完成自然语言领域一些更复杂的任务,如语言翻译、问答对话、搜索补全、情感分析、文章续写等。
Diffusion-LM是首个将扩散模型应用到自然语言领域的扩散语言模型。该模型旨在解决如何将连续的扩散过程应用到离散的非连续化文本的问题,由此实现语言类的高细粒度可控生成。经过测试,Diffusion LM在6种可控文本生成任务中取得非常好的生成效果。
实际上,后续也有非常多的基于Diffusion-LM的应用。不过在自然语言领城,目前的主流模型仍然是GPT (Generative Pre-trained Transformer)。
多模态信息指的是多种数据类型的信息,包括文本、图像、音/视频、3D物体等、多模态信息的交互是人工智能领域的研究热点之一,对于AI理解人类世界、帮助人类处理多种事务具有重要意义。在诸如DALLE-2和StableDiffusion等图像生成扩散模型以及ChatGPT等语言模型出现之后,多模态开始逐渐演变为基于文本和其他模态的交互,如文本生成图像、文本生成视频、文本生成3D等。

图3-6 使用Imagen实现文字生成图像的几个示例

图3-7 Meta Al的Make-A-Video:一条身看超人外衣、肩披红色斗篷的狗在天空中翱翔
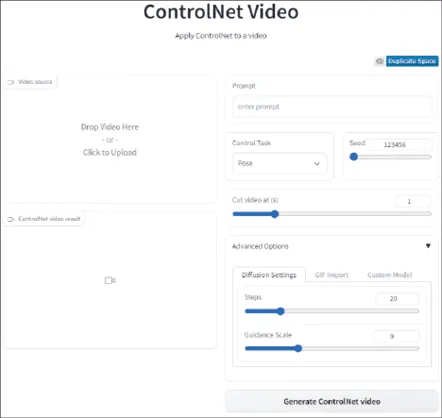
图3-8 Hugging Face上的ControlNet Video Space应用界面
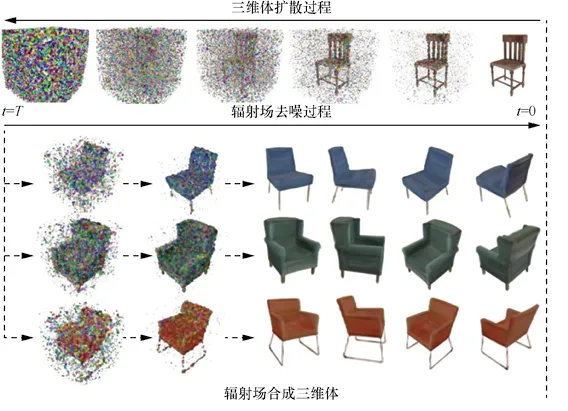
图3-9 使用DiffRF生成3D沙发
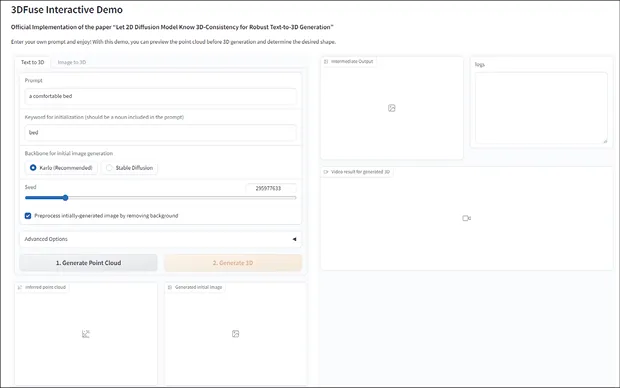
图3-10 Hugging Face上的3DFuse Space界面
Al基础科学又称Al for Science,它是人工智能领域具有广阔前景的分支之一,甚至能够发展为造福人类的技术。与AI基础科学相关的研究成果也不止一次荣登《自然》杂志。例如,2021年DeepMind研究的AlphaFold 2可以预测人类世界98.5%的蛋白质,2022年DeepMind用强化学习控制核聚变反应堆内过热的离子体等。
扩展模型对生成类的任务一直表现十分专业,AI基础科学中生成预测类的研究当然也少不了扩展模型的参与。SMCDIT创建了一种扩散模型,该扩散模型可以根据给定的模体结构生成多样化的支架蛋白质,如图3-11所示。CDVAE则提出了一种扩散晶体变分自编码器模型,旨在生成和优化具有固定周期性原子结构的材料,如图3-12所示。
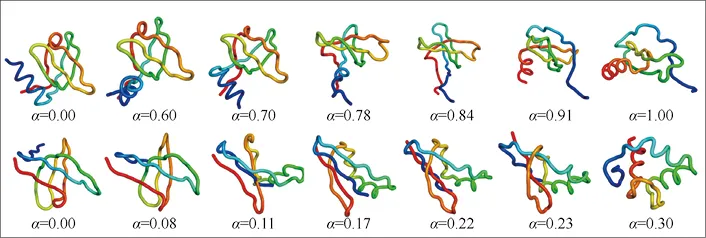
图3-11 SMCDIT生成的多样化的支架蛋白质
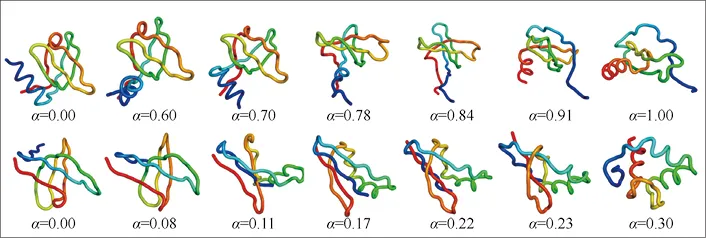
图3-12 CDVAE生成的遵循Langevin动力学的不同原子结构的材料
文章转自微信公众号@ArronAI






