

文档提取与人工智能的完整指南
几年前,Andrej Karpathy 写了一篇关于训练神经网络的很棒的文章。以下是我在实施过程中遵循的一些额外事项,侧重于调试大型语言模型。
尽可能广泛地预先设置日志记录。我使用 wandb 进行实验报告。我发现它是目前市场上最好的实验跟踪选择,个人使用量几乎不受限制。
权重:记录训练过程的张量,尤其是层权重的更新。注意趋于零并停留在那里的梯度。有时这只是当前损失景观的副产品,但它通常表明网络已经饱和了它实际上可以进行的学习。
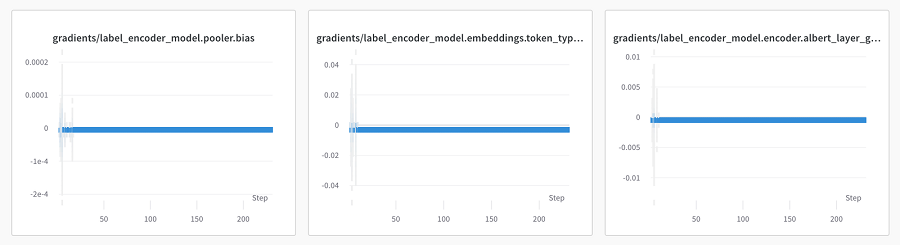
具体来说,
这两个分布日志都是通过 wandb 的内置监视实用程序处理的。
wandb.watch(model, log="all", log_freq=10)通过迭代当前模块参数,可以轻松完成矩阵范数。两者为你提供了对同一数据的略有不同的视图。
数据点:数据集示例随着时间的推移具有黄金价值。如果损失计算中存在错误,损失指标可能会成功下降,即使网络没有学到任何有价值的东西。错误更难隐藏在人类可理解的数据点中。
tokenizer.decode()。这通常是在输入(预嵌入)和输出(后线性投影到词汇空间)处,但也可以是额外的填充生成或掩码等地方。最终层 logits:在单标签、多类别问题中,你可能会使用 softmax 作为损失函数的一部分。由于 softmax 不是硬最大化算法,因此你可以鼓励模型在正确的类别上创建权重分布。如果你在图表上记录最终层 logits,你应该注意到大多数概率质量会随着时间的推移收敛到正确的值(尤其是在过度拟合运行期间)。在过度拟合过程中,你走得越远,这个最大值点应该越明显。但权重应该有一个明显的转变,从均匀分散到接近正确值。
这为过度拟合的进展提供了额外的健全性检查。它确保模型以你期望的方式在统计上发展,并且软最大化值平稳增加。通常,查看随时间的变化是分析训练的一种有用方法。
如有疑问,请始终记录。
大多数核心 ML 活动都有通用的抽象层。Transformers 可以用 RNN 代替,Resnet 可以代替 CNN。这些更简单的方法无法达到你想要的精度,但可能能够证明整体线束的梯度流是否存在问题。它们的训练速度也更快,如果你尝试对新的过度拟合管道进行快速健全性检查,这将非常有用。
我还注意到,较新的笔记本电脑在矩阵乘法方面变得出奇地快。当然还不足以训练整个网络,但我现在经常发现自己在本地进行初始原型设计。这项工作的重点是简单架构上的过度拟合、数据的健全性检查以及确保矢量化在逻辑上正确。
现代模型中内置了大量随机性。
正如预期的那样,这些技术有助于通过使网络难以过度拟合来推广模型。但在过度拟合期间,你确实希望它们过度拟合,理想情况下是积极地记住输入以测试模型容量和训练工具。如果输入、输出或损失具有随机性,则很难确定过度拟合期间是否存在问题。
我过去常常在过度拟合时手动禁用模型的所有随机元素:将 dropout 设置为零,禁用数据增强等。这种方法的缺点是有很多 if elif 语句,而且不一定能捕获导入的模块是否在其实现中嵌入了一些随机性。我没有采用这种方法,而是在每个训练和验证步骤中开始用固定种子为模型播种。在 Pytorch-Lightning 中,这看起来像:
CONSTANT_SEED = 60
class MySmartModule:
def training_step(self, batch):
if self.trainer.overfit_batches:
print("Will reset seed for reproducable overfitting")
pl.seed_everything(CONSTANT_SEED)
def validation_step(self, batch):
if self.trainer.overfit_batches:
print("Will reset seed for reproducable overfitting")
pl.seed_everything(CONSTANT_SEED)这不会直接消除随机性,但它应该使随机值在每个训练和验证步骤中保持一致,这实际上是同一件事。这应该允许模型过度拟合以及零随机性实现。通过日志进行双重检查以确认输入值确实相等。
任何足够大的网络都应该能够在少数数据点上达到 0 损失。我通常从一个示例(1 个批次,批次大小 1)开始。这应该是可以轻易学习的,因为甚至不需要创建判别输出空间。如果成功,则扩展到 2 个不同的示例,然后扩展到 5 个不同的示例。
这听起来有点矫枉过正,但它省去了很多麻烦。每当我做前馈传递值以外的任何事情时,我都会将张量转换重构为单独的函数。然后,我使用标准 for 循环和基于单个索引的张量重写此逻辑。然后运行几个示例并确保它们的值匹配。这是验证矢量广播和其他并行操作是否按预期工作的最简单方法。
具体来说,我将两个实现都包装在描述转换的类中。假设我们要编写一个掩盖特定值颜色的函数。我从 for 循环实现开始,逐个索引地进行。调用矢量化管道的尝试失败了。原始类结构如下所示:
class ColorMasking:
def __init__(self, vectorize):
self.vectorize = vectorize
def __call__(self, *args, **kwargs):
if self.vectorize:
return self.vectorized(*args, **kwargs)
else:
logging.warning("Using greedy implementation of ColorMasking")
return self.greedy(*args, **kwargs)
def greedy(self, img):
for y in range(img.shape[0]):
for x in range(img.shape[1]):
...
def vectorized(self, img):
raise NotImplementedError()这个类可让你轻松地在显式(速度慢但更可能正确)和矢量化(速度快但更可能引入错误)之间切换。它还内置了一个可单元测试的代码块,可以更轻松地检查一段时间内的实现问题。然后,你可以在神经网络模块内选择是否要全面切换到矢量化,或者使用手动矢量化对几个时期进行健全性检查。
class MySmartModule(torch.nn.Module):
def __init__(self):
self.vectorize = False
def forward(img):
mask = ColorMasking(vectorize=self.vectorize)(img)这也对实现过程进行了补充,到目前为止您可能只有一个明确的实现:
class MySmartModule(torch.nn.Module):
def __init__(self):
self.vectorize = False
def forward(img):
mask = ShapeMask(vectorize=self.vectorize)
mask = ColorMasking(vectorize=False)(img)有时我会直接用这个非向量化函数运行过度拟合作业,以检查它是否按照我的意愿运行。有时由于速度限制,我会直接编写向量化逻辑。
为向量化、数据加载器和训练管道添加重型单元测试组。
向量化:作为上一节的延续,验证向量化代码是否正常工作。通过几个手写示例定义预期的转换。尝试使用不同的张量大小并记录预期权重或一些预期的转换。
数据加载器:这也适用于数据加载器。如果可能,通过反向转换来保证转换符合预期。获取文本 logits 的 argmax 并检索文本,将图像像素转换为可以与静态工件进行比较的实际 PIL,等等。
训练管道:额外的集成测试可以验证训练管道的某些行为。最大的问题之一通常是梯度流 – 无法正确传播到网络中较早的张量的损失。在最好的情况下,你错过了可验证的学习 – 在最坏的情况下,较早的层将保持随机初始化,而网络的其余部分将猜测随机输入噪声。一种解决方法是进行测试,该测试传递一些合成数据并跨过梯度权重并断言每个范数都非零。网络的每一层都应该有一些学习。
我的训练管道倾向于通过 CLI 训练可执行文件启动。为了确保单元测试在每次训练运行中都令人满意,我在初始化线束之前向此实现添加了 pytest 运行命令。
@click.command()
def train():
pytest.main()
# Training block全局变量在常规软件工程中通常是一种不好的形式,在机器学习中也同样糟糕。Jupyter 非常适合原型设计,但当事物被定义为常规单元时,很容易出现错误。即使你将一些逻辑重构为函数,它们仍可能在全局状态下获取变量。
作为一般工作流程,我完全在全局空间中制作原型。传递变量并确保张量大小正确更容易。在这里我通常只处理一个批次。
在开始完整的训练运行之前,我会将所有单元重构为单独的函数。这确保没有全局变量泄漏。它之前已经捕获了一些微不足道的错误,即同一个值被无意中重复使用多次,而不是在更大的列表中进行迭代。
添加自定义数据集、自定义加载器和自定义整理函数时,批次可能会随时间发生细微偏差。当现场操作字典或聚合某些值时,这种情况尤其容易发生。我使用此代码片段来检查随时间推移的相等性。
毋庸置疑,如果你在数据加载器类中引入随机增强,这将不起作用。对于这些情况,我会暂时禁用转换,然后运行此验证。你还可以有选择地将应随时间保持不变的键列入白名单,同时允许随机转换中的键发生变化。
first_sample = next(iter(train_loader))
second_sample = next(iter(train_loader))
print("Will check equality...")
for key in first_sample.keys():
first_value = first_sample[key]
second_value = second_sample[key]
if isinstance(first_value, torch.Tensor):
if not torch.equal(first_value, second_value):
print(first_value)
print(second_value)
raise ValueError(f"Unequal iterations: {key} (torch tensor)")
else:
if first_value != second_value:
print(first_value)
print(second_value)
raise ValueError(f"Unequal iterations: {key}")
print("Success...")在较大的网络中,尤其是通过时间反向传播,梯度可能会在网络中较早消失。我发现一种调试这些问题的有用方法是合成生成不同大小的新数据点。
如果你的数据加载器最终接受磁盘上的文件,那么这是一种自然选择,这在我最终构建的大多数大型架构中都很常见。编写一个函数,以正确的格式将新数据集转储到磁盘。输出值在这里并不重要,因为网络应该只记住过度拟合期间的原始值。
tokenizer = Tokenizer()
labels = ["A", "B", "C"]
@contextmanager
def create_synthetic_datapoint(text_length):
random.sample(tokenizer.vocab, text_length)
random.choice(labels)
with tempfile.TemporaryDirectory() as directory:
yield directory
with create_synthetic_datapoint(50) as path:
train_dataset = MyDataset([path])
trainer.overfit(model, train_dataset)每当需要张量变换(查看、转置、堆叠等)时,我都会尝试将其放入 einop 中。它们通过引用字符串值来表示轴的含义,从而使这些操作更具描述性。它们还可以假设一些维度,否则你可能需要 .shape 算法。我尝试在这些字符串中使用完整的单词或变量名称,除非某些东西很明显,例如 b 表示批处理。
x = rearrange(x, "b height width embedding -> b (height width) embedding")我发现,当我离开某个功能几天后,这些 einops 使调试变得容易得多。
得益于出色的开源项目和与出版物一起发布代码的日益增长的趋势,成功训练的道路变得越来越容易。但是,当尝试一些新颖的东西(无论是在数据集上还是使用新的模型架构)时,成功之路仍然曲折。一个字符的索引错误可能会导致结果从 SOTA 变为勉强超过基线。
我有一位老同事说“软件中一切皆有可能,你只需要花足够的时间来构建它。” ML 的挑战在于有些事情是不可能的——至少在目前数据和架构的最新水平下是不可能的。 ML 研究是尽可能减少逻辑错误机会的过程。因为失败可能是因为某事根本不可能——或者因为它可能是一个错误。提前勤奋和防御是确保失败是前者而不是后者的最佳方式。对合理的失败感到坦然是让实验真正取得成功的最好方法。
幂简集成是国内领先的API集成管理平台,专注于为开发者提供全面、高效、易用的API集成解决方案。
幂简API平台提供了多种维度发现API的功能:通过关键词搜索API、从API Hub分类浏览API、从开放平台分类浏览企业间接寻找API等。
此外,幂简集成开发者社区会编写API入门指南、多语言API对接指南、API测评等维度的文章,让开发者选择符合自己需求的API。
原文链接:http://www.bimant.com/blog/debugging-tips-for-llms-training/













