AI大模型选择的决策框架:比较GPT-3.5 和 GPT-4
自 2022 年春季以来,大型语言模型 (LLM) 大量涌入市场。OpenAI、Microsoft、Anthropic、Meta 、百度、阿里和 AI 21 Labs 等公司已发布了其专有 LLM 的多个版本,引发了技术范式转变,开发者和企业如何选择AI大模型来使用?与所有重大技术进步一样,在决定如何以及何时利用这项创新技术时,需要一套决策框架来帮助回答“我应该何时使用哪种模型?”的问题。本博客以GPT 模型为案例,揭示该决策框架的使用。
对于AI技术初学者,建议通过下述文章能建立对AI大模型的一个认知框架:
为了快速达到水平集,生成式预训练转换器 (GPT) 是专为自然语言处理而设计的机器学习模型。它们在 EB 级数据(例如书籍和网页)上进行训练,以生成与上下文相关且语义连贯的语言。换句话说,GPT 可以生成类似于人类书写的文本,而无需明确编程。这使得它们具有高度的通用性和适应性,可以完成自然语言处理任务,包括回答问题、翻译语言和总结文本。GPT 系列模型中功能最强大的是 GPT 3.5 和 GPT4。即使在这些模型版本中,也有几个版本具有细微但重要的差异。虽然这些模型可以用于类似的自然语言任务,但它们有各自的优点和缺点。为了帮助您做出决策,我将在比较这些模型时使用以下因素:
- 上下文窗口
- 训练数据集截止
- 成本
- 模型功能
- 精细可调性
- 潜伏
上下文窗口
上下文窗口是指人工智能模型在处理输入时能够考虑的最大标记数,这包括了系统的提示和用户的输入。这个特性对于AI应用的实用性至关重要,并且可能对整个应用的设计产生重大影响。例如,如果你正在开发一个使用大型语言模型(LLM)进行文本摘要的应用,你可能需要用户能够对长篇文章进行摘要。因此,你选择的模型应该能够处理并记忆大量的文本。目前,GPT-3.5模型的输入上下文窗口限制为16,000个标记,输出为4,000个标记。而GPT-4模型则将输入上下文窗口提升至128,000个标记,输出保持在4,000个标记。这相当于从能够处理16页文本到能够处理200多页文本的能力。虽然可以通过一些技术手段,如分块处理,来在较小的上下文窗口中处理大量文本,但这会增加应用的复杂度,需要更多的组件管理和解决更多的技术难题。
训练数据集截止
训练数据集的截止日期是指模型在训练过程中考虑的最新数据的日期。由于大型语言模型(LLM)本质上是复杂的机器学习模型,机器学习的许多原则对它们同样适用。其中之一就是需要精心策划和构建用于训练这些模型的数据集。虽然这些模型的训练数据包括一些历史信息,但大部分数据与时事紧密相关,比如当前的世界领袖或名人的去世等。
由于这些模型不是实时更新的,它们通常会有一个固定的训练数据截止日期,超过这个日期的信息模型就无法知晓。通常,较新的模型版本会使用更新的数据集进行训练。例如,GPT-3.5的训练数据截止于2021年9月,而GPT-4的不同版本则使用截至2023年12月的数据进行训练。
虽然这看似是一个限制,但有一些技术,如检索增强生成(RAG),可以通过提供最新信息来绕过这个截止日期的限制。然而,这引出了一个问题:“如果RAG可以提供最新信息,那么训练数据的截止日期还重要吗?”虽然RAG可以在提示中添加额外的信息,但这可能会导致响应时间延长和成本增加。使用包含最新、最相关数据的模型进行预训练可以减少在RAG实现中需要包含的信息量。
成本
在设计人工智能应用程序时,成本往往是一个关键的考量因素。在使用大型语言模型(LLM)时,成本通常与token的使用量相关。Token是模型用来解析自然语言的基本单位,可以是整个单词或单词的一部分。对于GPT-3.5和GPT-4模型,大约每4个字符构成一个token。
重要的是要区分两种类型的token:提示token和完成token。提示token是你发送给LLM的输入,包括系统消息、检索增强生成(RAG)上下文或用户的查询。这些token在使用LLM时可能会导致达到上下文窗口的限制。而完成token则是LLM生成的响应token,它们同样会影响token使用量的限制,但可以通过调整“max_tokens”参数来轻松控制。
不同token的定价可能会有所不同,因此建议查看Azure OpenAI Service的定价页面以获取最新的价格信息。截至本文撰写时,GPT-3.5的定价通常低于GPT-4。
功能
当评估GPT模型时,理解它们各自的特性至关重要。一个有用的方法是将GPT模型系列中的改进分为两种类型:渐进式和指数式。GPT-3.5和GPT-4各自拥有多个版本,如0301、0613、1106和0125,这些版本展示了逐步的改进,比如减少延迟、增加函数调用支持和修复小错误。例如,GPT-3.5的0613版本比0301版本快60%,并且支持函数调用。而1106版本在0613的基础上增加了并行函数调用和与Assistants API的兼容性,0125版本则修复了响应格式和文本编码的问题。
相比之下,GPT-3.5和GPT-4之间的比较则代表了一种指数级的提升。GPT-3.5是在大约1750亿个参数上训练的,而GPT-4可能在接近1万亿个参数上进行了训练。通过处理更多的数据,GPT-4在展示更高级的推理和格式化能力方面超越了GPT-3.5。因此,如果需要更复杂的推理能力,通常推荐使用GPT-4。虽然“复杂”的定义可能因人而异,但通常包括多智能体系统、图像和文本分析以及分类任务等。
值得注意的是,通过即时工程,GPT-3.5的能力可以在某些任务上与GPT-4相提并论。即时工程可能涉及使用更多token的技术,如链式思维(Chain of Thought)和小样本学习。尽管这种方法是可行的,但它通常需要更高级的技术来实现。
精细可调性
尽管在大多数通用人工智能(GenAI)应用中,通过结合检索增强生成(RAG)和即时工程可以解决大部分用例和功能,但在某些特定情况下,对大型语言模型(LLM)进行微调可能是更优的选择。微调是一个根据特定数据集定制模型的过程,它类似于即时工程中的“少量学习”概念,允许你提供多个示例,指导模型应该了解什么或如何响应。这些示例被用来调整模型权重,以便更好地适应特定的行业、公司或角色需求。
微调通常需要数千个示例才能对模型产生显著的影响,而“少量学习”则只需要提供几个示例(2-5个)。在微调LLM时,需要注意一种称为“灾难性遗忘”的现象,这可能导致模型性能下降而不是提升。
在考虑微调时,建议首先尝试使用较小的语言模型,如phi-2。这是因为小型语言模型(SLM)更容易调整权重,因此即使是较小的数据集(通常100条记录)也能显著提升其性能。尽管如此,Azure OpenAI服务也支持对GPT-3.5进行微调,这可以通过Azure AI Studio或Python SDK来实现。
潜伏
在大型语言模型(LLM)的应用中,延迟是指从提交请求到接收响应之间的时间间隔。在评估延迟时,有两个关键指标需要关注:第一个标记时间(TTFT)和端到端延迟(E2E)。TTFT指的是模型开始生成输出所需的时间,而E2E延迟则涵盖了从接收输入到返回完整响应的整个过程。
在比较GPT-3.5和GPT-4时,通常会发现GPT-3.5的所有版本在响应速度上普遍快于GPT-4。这可能是因为GPT-4的规模更大,据估计,GPT-4大约有1万亿个参数,这使得它在处理能力上远超GPT-3.5,但同时也意味着需要更多的计算资源。因此,像GPT-3.5这样的较小模型不仅成本较低,而且响应速度也更快。
如果您的应用场景需要同时满足复杂推理和低延迟的需求,可以采用一些技术来优化性能,例如快速压缩和语义缓存。这些技术可以帮助您在利用GPT-4的强大能力的同时,保持响应速度。
决策树
以下是一个决策框架,可以帮助您集中注意力。虽然这不是一份全面的指南,但它是引导讨论技术和业务需求的一个很好的起点。如上所述,“复杂”可能是主观的,但在这种情况下可以包括与多智能体系统、图像和文本分析以及分类相关的用例。
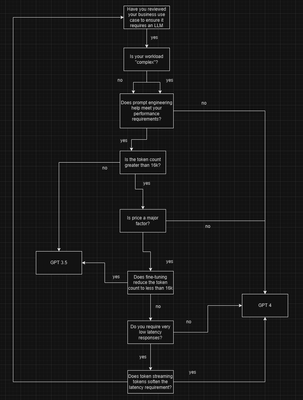
结论
在选择GPT-3.5和GPT-4时,重要的是要明确您的具体需求和约束条件。GPT-3.5因其成本效益和快速响应时间而受到青睐,尤其适合那些对这些特性有严格要求的应用场景。而GPT-4则因其更强的推理能力和更大的上下文窗口而脱颖而出,非常适合处理需要深层次理解和精细内容生成的复杂任务。
此外,您还可以采取一种“两全其美”的策略,使用大型语言模型(LLM)编排框架,将GPT-3.5作为默认选项,并在需要时灵活切换到GPT-4。这样的方法可以让您在保持成本效益的同时,也能在必要时利用GPT-4的高级功能。
最终的决策应该基于多个因素,包括技术方面的考量,如上下文窗口的大小、训练数据集的更新程度、延迟等,以及实际因素,如成本、微调的难易程度以及特定任务的要求。通过综合考虑这些方面,您可以最大限度地发挥GPT系列LLM的潜力,推动您的应用程序在创新和效率上取得进展。
请记住,LLM领域正在迅速发展,持续关注最新的进展将帮助您充分利用这些强大的工具。
本文转自《Comparing GPT-3.5 & GPT-4: A Thought Framework on When To Use Each Model》
参考资料
Awesome-LLMs-Evaluation-Papers
横向对比文心一言、百川、Minimax、通义千问、讯飞星火、ChatGPT
最新文章
- 小红书AI文章风格转换:违禁词替换与内容优化技巧指南
- REST API 设计:过滤、排序和分页
- 认证与授权API对比:OAuth vs JWT
- 如何获取 Coze开放平台 API 密钥(分步指南)
- 首次构建 API 时的 10 个错误状态代码以及如何修复它们
- 当中医遇上AI:贝业斯如何革新中医诊断
- 如何使用OAuth作用域为您的API添加细粒度权限
- LLM API:2025年的应用场景、工具与最佳实践 – Orq.ai
- API密钥——什么是API Key 密钥?
- 华为 UCM 推理技术加持:2025 工业设备秒级监控高并发 API 零门槛实战
- 使用JSON注入攻击API
- 思维链提示工程实战:如何通过API构建复杂推理的AI提示词系统