给初学者的Dezgo公司AI绘画API接口使用入门指南
文章目录
Dezgo是一个由人工智能驱动的在线图像生成器,该产品内核由 Stable Diffusion XL Lightning AI (CreativeML Open RAIL-M) 提供支持。Dezgo AI绘画API允许您从任意文本描述中生成图像。您可以使用它为您的网站、社交媒体或业务生成图像,例如产品图像、书籍插图或营销材料。幂简集成API平台已将该API接口整理到API Hub,方便广大开发者搜索、试用、集成。
Dezgo的产品与最流行的人工智能模型Stable Diffusion类似,但提Dezgo的AI绘画API供了稳定扩散的几种变体,这些变体经过调整以生成不同风格的图像。这是一种复杂的技术,使用人工神经网络(由数百万个神经元和突触组成),能够学习高级概念并自行改进。
Dezgo有一个免费版本的Dezgo,可以用于体验,先看看一个生成效果“苏轼是一位男性书生,穿着长衫,腰挎长剑,站在长江边上,看着晚霞西去”。
Su Shi, a male scholar, dressed in a long robe, with a long sword hanging from his waist, stands on the banks of the Yangtze River, watching the sunset in the west.
什么是Dezgo AI绘画API接口?
由Dezgo公司提供的通过‘文字生成图片’功能的在线API接口,企业可以通过集成AI绘画API接口实现自有产品的图片能力增强。
例如在企业内部发布系统的文章首图,可以通过文章的摘要,生成特定风格、尺寸的图片。
第一步:创建Dezgo帐户
1、您可以在这里创建账号:https://dezgo.com/account
2、创建秘钥
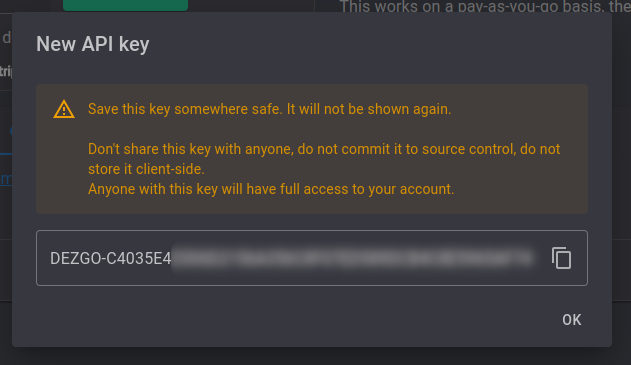
3、复制秘钥
第二步:使用curl调用text2image接口
text2image是一个文字生成图片的接口,URL地址:https://api.dezgo.com/text2image,文档地址:https://dev.dezgo.com/API/
curl -X 'POST' \
'https://api.dezgo.com/text2image' \
-H 'accept: */*' \
-H 'Content-Type: multipart/form-data' \
-F 'lora2_strength=.7' \
-F 'lora2=' \
-F 'lora1_strength=.7' \
-F 'prompt=Su Shi, a male scholar, dressed in a long robe, with a long sword hanging from his waist, stands on the banks of the Yangtze River, watching the sunset in the west。' \
-F 'width=' \
-F 'height=' \
-F 'steps=30' \
-F 'sampler=dpmpp_2m_karras' \
-F 'model=realdream_12' \
-F 'negative_prompt=ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, blurry, bad anatomy, blurred, watermark, grainy, signature, cut off, draft' \
-F 'upscale=1' \
-F 'seed=' \
-F 'format=png' \
-F 'guidance=7' \
-F 'lora1='重点参数说明:
- width,height:图像的宽度和高度,数值范围 [3
20,1024] - prompt:提示词,最大1000个字符
- negative_prompt:描述你不希望在生成的图像中出现的内容,最大1000个字符
- model:用于生成图像的人工智能
- sampler:定义用于生成图像的采样方法。对于低步数来说最好的采样器往往是
dpmpp_2m_karras - lora1:指定要使用的 LoRA 模型(最大 160MB)。如果未指定,则不会加载 LoRA,否则必须是 CivitAI 上可用模型的 SHA256 哈希,LoRA 模型将被下载并即时缓存。
- lora1_strength:指定 LoRA 模型对结果的影响强度。范围通常为 0.0(无效果)至 1.0(完全效果)。但是,如果您想进行实验,可以超出这些限制:从 -2.0 到 +2.0。负值将反转效果。超过 1.0 的值将放大效果。
model属性枚举值,代表了不同的AI生成风格,用于生成特定的图像(每个值的背后可能对应一个预训练的神经网络模型,专门用于某种艺术风格或图像处理技术):
0001softrealistic_v187:可能是一种以超现实主义风格生成柔和、逼真图像的模型版本187。
absolute_reality_1、absolute_reality_1_6、absolute_reality_1_8_1:这些可能是以绝对现实主义风格生成图像的不同版本或迭代。
abyss_orange_mix_2:可能是一种混合了橙色调的深渊风格模型。
analog_diffusion:可能是一种模拟胶片颗粒感的图像扩散模型。
anylora、dreamshaper、dreamshaper_5 等:这些可能是具有不同风格或特性的图像生成模型。
art_universe_v8:可能是一种用于生成艺术作品的宇宙风格模型版本8。
basil_mix、blood_orange_mix:这些可能是混合了特定色彩或风格的模型。
cyberrealistic_1_3、cyberrealistic_3_1、cyberrealistic_3_3:可能是以赛博现实主义风格生成图像的模型。
dark_sushi_mix_v2_25d:可能是一种混合了暗色调和寿司风格的模型。
deliberate、deliberate_2:可能是用于生成具有特定意图或效果的图像的模型。
dh_classicanime:可能是用于生成经典动漫风格的模型。
double_exposure_diffusion:可能是用于生成双重曝光效果的图像的模型。
eimis_anime_diffusion_1:可能是用于生成动漫风格图像的模型。
emoji_diffusion:可能是将图像转化为表情符号风格的模型。
epic_diffusion_1、epic_diffusion_1_1:可能是用于生成史诗级别效果的图像的模型。
foto_assisted_diffusion:可能是辅助摄影风格的图像扩散模型。
furrytoonmix:可能是混合了毛茸茸特征和卡通风格的模型。
ghostmix_v2:可能是以幽灵风格生成图像的模型。
hasdx、icbinp、icbinp_seco:这些可能是具有特定艺术效果的模型。
inkpunk_diffusion:可能是以墨水朋克风格生成图像的模型。
juggernaut_reborn:可能是具有强大影响力的图像生成模型。
lowpoly_world:可能是以低多边形风格生成图像的模型。
nightmareshaper:可能是以噩梦风格生成图像的模型。
openjourney、openjourney_2:可能是开放旅程风格的图像生成模型。
paint_journey_2_768px:可能是以绘画旅程风格生成特定分辨率图像的模型。
pastel_mix:可能是以粉彩风格混合生成图像的模型。
portrait_plus:可能是用于生成高级肖像的模型。
realcartoon3d_13、realcartoonanime_10:可能是将图像转化为3D卡通或动漫风格的模型。
redshift_diffusion:可能是以红移效果生成图像的模型。
rpg_5:可能是用于生成角色扮演游戏风格的模型。
stable_diffusion_fluidart、stable_diffusion_papercut、stable_diffusion_voxelart:这些可能是Stable Diffusion模型的不同艺术风格变体。
steampunk_diffusion:可能是以蒸汽朋克风格生成图像的模型。
synthwavepunk_v2:可能是结合了合成波和朋克风格的模型。
toonify_2:可能是将图像转化为卡通风格的模型。
trinart_2_0:可能是Trinart模型的2.0版本。
vectorartz_diffusion:可能是以矢量艺术风格生成图像的模型。
vintedois_diffusion_v0_1:可能是以复古动漫风格生成图像的模型。
waifudiffusion_1_3、waifudiffusion_1_4:可能是用于生成动漫角色风格的模型。
yesmix_4:可能是某种混合风格生成图像的模型。sampler 常量代表用于生成图像的不同采样方法,主要用于基于扩散模型的图像生成技术中,枚举值说明:
ddim: 代表"Denoising Diffusion Implicit"(去噪扩散隐式)采样方法,这是一种基于扩散模型的图像生成方法,通过逐步引入噪声并在每个步骤中去除噪声来生成图像。
dpm: 代表"Denoising Diffusion Probabilistic"(去噪扩散概率)采样方法,它是另一种基于扩散模型的方法,侧重于概率性地去除噪声。
dpm_single: 这可能是"Denoising Diffusion Probabilistic Single"的缩写,指的是在单次迭代中应用去噪扩散概率方法,而不是多次迭代。
dpmpp_2m_karras: 这可能是一个特定实现或变体的去噪扩散模型,其中"2m"可能表示两次混合步骤,"karras"可能是实现该方法的研究人员或团队的名称。
euler: 代表"Euler"采样方法,以数学家欧拉命名,可能是一种基于欧拉方法的数值采样技术,用于简单有效的问题求解。
euler_a: 这可能是"Euler A"的缩写,表示一种改进的欧拉采样方法或特定的应用方式。
k_lms: 可能代表"Kalman Least Mean Squares"(卡尔曼最小二乘法)采样方法,这是一种利用卡尔曼滤波器进行参数估计和信号处理的技术。
pndm: 可能代表"Predictor-Corrector Noise Diffusion Model"(预测-校正噪声扩散模型)采样方法,这是一种结合预测和校正步骤的图像生成技术。第三步:使用Java编写客户端测试代码
Java客户端代码示例,在实际项目中,请把下面代码封装为一个工具类:
import java.io.*;
import java.net.*;
import java.util.Map;
import java.util.HashMap;
public class Main {
public static void main(String[] args) throws Exception {
String url = "https://api.dezgo.com/text2image";
String dezgoKey = "请注意替换";
HttpURLConnection con = (HttpURLConnection) new URL(url).openConnection();
con.setRequestMethod("POST");
con.setRequestProperty("accept", "application/octet-stream");
con.setRequestProperty("Content-Type", "multipart/form-data; boundary=----WebKitFormBoundary7ma42iwvjor0g3g4");
con.setRequestProperty("X-Dezgo-Key",dezgoKey);
// 创建数据
String boundary = "----WebKitFormBoundary7ma42iwvjor0g3g4";
StringBuilder sb = createMultipartBody(boundary,
// 添加你的参数
"prompt", "Su Shi, a male scholar, dressed in a long robe, with a long sword hanging from his waist, stands on the banks of the Yangtze River, watching the sunset in the west."
// 省略其他参数
);
byte[] bytes = sb.toString().getBytes("UTF-8");
con.setDoOutput(true);
try (DataOutputStream wr = new DataOutputStream(con.getOutputStream())) {
wr.write(bytes);
}
// 检查响应码
int status = con.getResponseCode();
if (status == HttpURLConnection.HTTP_OK) {
// 读取响应流
try (InputStream is = con.getInputStream();
FileOutputStream fileOutputStream = new FileOutputStream("output_image.png")) {
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = is.read(buffer)) != -1) {
fileOutputStream.write(buffer, 0, bytesRead);
}
System.out.println("Image saved successfully!");
}
} else {
System.out.println("Failed to get image: " + status);
}
}
public static StringBuilder createMultipartBody(String boundary, String... params) {
StringBuilder sb = new StringBuilder();
sb.append("--").append(boundary).append("\r\n");
for (int i = 0; i < params.length; i += 2) {
sb.append("Content-Disposition: form-data; name=\"").append(params[i]).append("\"\r\n\r\n")
.append(params[i + 1]).append("\r\n");
sb.append("--").append(boundary).append("\r\n");
}
sb.append("--").append(boundary).append("--\r\n");
return sb;
}
}第四步:异常处理
该接口常见的几个错误代码:
- 401,未设置X-Dezgo-Key,或者账号秘钥错误
- 402,余额不足,该充钱了
AI绘画的同类产品有哪些?
国内外提供API的AI绘画产品有很多,下面推荐几款幂简集成已经收集的AI绘画类型的API接口:
如何找到更多AI绘画API
幂简集成是国内领先的API集成管理平台,专注于为开发者提供全面、高效、易用的API集成解决方案。幂简API平台可以通过以下两种方式找到所需API:通过关键词搜索API(例如,输入’AI绘画‘ 这类品类词,更容易找到结果)、或者从API Hub分类页进入寻找。
此外,幂简集成博客会编写API入门指南、多语言API对接指南、API测评等维度的文章,让开发者快速使用目标API。