

增强API安全性:降低访问控制失效的风险

获取准确和及时的数据对于大多数项目至关重要无论是对于企业、研究人员,还是开发人员来说,获取准确和及时的数据都至关重要。使用 API 抓取网页是最流行的抓取网页的方法,能够快速和企业知识库系统、大模型训练系统、内容管理系统等进行API集成。 使用 网页抓取API 从网站收集数据,将规避 CAPTCHA验证、代理设置、IP池等难题,大幅度降低企业成本。
本文主要讲两家特色网页抓取服务商:Apify API、Crawlbase Scraper API。
网页抓取API是指由saas模式的网页抓取软件通过RESTful模式提供给互联网用户的开放API接口。
什么是API?API是一组协议和工具,允许不同的软件应用程序相互通信。API旨在提供一种结构化和标准化的方式与数据交互,使其成为数据检索的强大工具。
什么是网页抓取?又称为网页抓取器,是一类模拟人类浏览行为的工具,通过执行‘网站导航、点击链接、浏览网页’等行为,从HTML内容中提取信息,包括文本、图像和其他多媒体元素。
网页抓取API是否存在风险,关键点在于‘授权’、‘相关政策’、‘用途’。
网页抓取涉及使用自动化流程,包括用不同的编程语言或工具编写代码或脚本来模拟人类浏览行为、浏览网页并捕获特定信息。这些代码或脚本通常被称为网络爬虫、网络机器人或网络蜘蛛,是大规模数据获取的常见技术。
网页抓取大致可以分为以下几个步骤:
requests库来发送请求并获取服务器的响应。BeautifulSoup库来解析HTML并提取我们感兴趣的数据。为了有效地处理大量数据和自动化工作流程,Apify 是一个无服务器计算平台。 API 或 Web 界面可用于访问“参与者”(无服务器微服务)、队列、结果存储、代理和调度。
无需管理服务器,开发人员可以使用 Apify 在云端构建和运行应用程序。 Apify 等平台使应用程序能够根据机器资源分配进行扩展和缩减。 有一种具有挑战性的方法来移动无服务器功能,这些功能通常是为长时间运行的任务而设计的。 然而,Apify 已经克服了这个障碍。 脚本演员,或编码意义上的演员,使用容器来执行动作。 这些容器在分发过程中维护应用程序的一致性和环境之间的奇偶校验。 Apify 通过容器和 Apify 平台的组合,为网络抓取和自动化代理提供对数据存储、任务创建、调度、集成和 Apify API 的直接访问。
使用现成的抓取工具立即提取无限的结构化数据,快速、准确的结果。
利用灵活的自动化软件来扩展流程、自动化繁琐的任务并加快工作流程。 通过自动化减少您的工作量,让您比竞争对手更快、更智能地工作。
可以将 Apify 与您的 Zapier 或 Make 工作流以及任何其他提供 API 和 webhook 的网络应用程序无缝集成。
数据中心和住宅代理的智能轮换与浏览器指纹识别技术的结合使得 Apify 机器人几乎与人类无法区分。
不用担心供应商锁定 Apify,因为它是建立在开源工具上的。
使用数十种库、工具和服务可以从网站上抓取数据以产生相同的结果。 但是,Apify 网络抓取工具在三个关键方面不同于其他应用程序:
例如,Apify 允许您轻松设置一个任务,当您的竞争对手在 Amazon.com 上提高价格时,该任务会向您发送一封电子邮件。 当新客户访问您的餐厅时,您还可以收到 Google Places 评论。
如果您不需要开发人员或需要大型数据集,您还可以请求自定义 Apify 解决方案。
使用 API 抓取网站是最好的方法。正如他们所说,“通过简单的 API 调用即可抓取任何页面的工具”是 Crawlbase Scraper API,一个供开发人员构建网络抓取工具的工具。 Web 服务通过允许开发人员从任何网站获取原始 HTML 来处理代理、浏览器和验证码。
此外,该项目在功能性、可靠性和可用性之间找到了独特的平衡。 使用 Crawlbase,您将可以访问功能强大且功能强大的 API,该 API 允许您抓取 Web 内容。
您可以使用 Crawlbase Scraper API 来抓取网络,而无需担心解析器、代理或浏览器。 如果您的业务需要,您可以使用 Scraper API 来抓取数据。 通过 API Scraper,AI 提取数据并防止阻塞。
您可以使用 Crawlbase Scraper API 在几秒钟内从目标网站检索数据。 除了具有自动代理设置外,它还有大量 IP 地址。 雕刻数据的准确性很高。
当使用 Proxy Crawl 的 Scraper API 抓取网站时,它改变了游戏规则。 此 API 以自动化方式简化了抓取和解析 Web 数据的过程。
Scraper API 专为开发人员设计,您可以在不到五分钟的时间内将您的应用程序连接到 API。 24/7 全天候可用的专业团队为整个服务提供支持。 Scraper API 的实现可以在用 Curl、Ruby、Node、PHP、Python、Go 或任何其他语言编写的应用程序中实现。
任何爬行或抓取网站的机器人都面临着许多挑战,例如检测来自单个 IP 地址的请求的时间和数量、CAPTCHA、受密码保护的数据访问以及蜜罐陷阱。 Scraper API 解决了这个问题。
庞大的代理网络为 API 提供支持,使您能够访问抓取的数据而不会被捕获或禁止,以及非常智能和高效的机器学习算法,使您不仅可以绕过这些障碍,还可以处理需要 JavaScript 的动态网站启用浏览器而不会被禁止。 像 Scraper 这样的 API 允许你抓取 Amazon, Twitter, Instagram等等。
在下表中,已根据 Apify 替代品提供的功能对其进行了分析。 Crawlbase Scraper API 和 Apify scraper 具有独特性,使它们从竞争对手中脱颖而出。
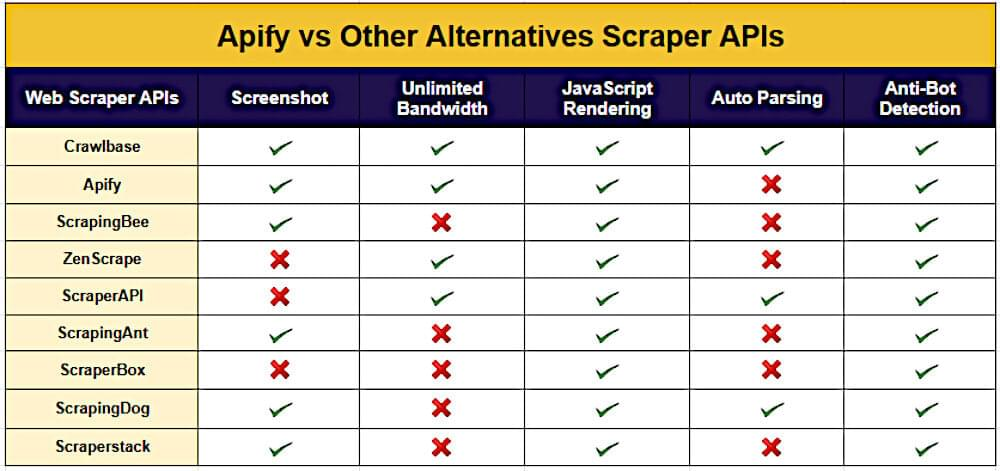
本文已经讨论了两个 API,即上面的 Apify API vs Crawlbase Scraper API,以便您可以轻松地选择最适合您的 API。如何找到更多网页抓取API?
用幂简API平台搜索API最方便:通过关键词搜索API、从API Hub分类浏览API、从开放平台分类浏览企业间接寻找API等。







