API集成模式
介绍
API 可以在任何环境中部署,从本地和 SaaS 应用程序到第三方。首先需要清晰了解将使用哪些 API,才能深入研究设计和使用模式。API 管理解决方案的部署架构也依赖于此。如果大多数交易在本地进行,则 API 管理必须在本地完成;如果交易发生在云端,同样适用。如果两者兼具,则可以选择云部署或云与本地的混合架构。
关于 API 集成
在 API 管理项目启动时,第三方 API 的机会并不总被充分考虑,这使得部署重点倾向于云端。然而,现有 API 的多样性非常广泛,能够为业务带来独特的功能。这些第三方 API 可以通过浏览器、公司网站或 API 管理解决方案(包括 API 组合)直接调用。特别是对于第三方 API,定价模型和服务级别协议 (SLA) 的考虑至关重要,因为如果期望 API 的 SLA 达到 99.9%,则不能依赖于 SLA 仅为 99.5% 的服务。
一旦确定了集成策略,便可以设计 API 集成,同时遵循应遵守的关键基础模式。
API 集成模式
连接到 API 很容易,但提供无缝、轻松且高性能的用户体验的安全集成却非常困难。每个 API 都独一无二;研究和构建集成需要剥离层层细微差别,包括 SOAP 与 REST、XML 与 JSON、不同的身份验证机制、迁移解决方案、Webhooks 与事件轮询、独特的错误代码及有限的搜索和发现等。此外,每个数据模型同样独特,开发人员需解决复杂的数据映射和转换问题。
考虑到这些挑战,接下来将回顾在构建和维护 API 集成时应遵循的关键模式。
错误代码
在创建集成时,了解可能从应用程序提供商获得的错误代码非常重要。当开始发送请求时,清楚何时操作有效,以及为何操作无效同样关键。通过集成,因无法访问大小限制而产生的错误代码可以帮助指导应用程序的业务逻辑。
模式:尊重 HTTP 错误代码
由于大多数 HTTP 错误代码都由 RFC 标准化,因此尊重这些代码并拥有一份详尽、准确的列表非常重要。下表描述了主要的 HTTP 错误代码,建议依赖完整且最新的列表,例如来自 Mozilla 的列表:Mozilla HTTP 状态列表。
表 1:错误代码和描述
| 状态码 | 描述 |
|---|---|
| 1xx | 信息性 |
| 200 | 执行 |
| 201 | 已创建 |
| 202 | 公认 |
| 204 | 没有内容 |
| 3xx | 重定向 |
| 301 | 永久搬迁 |
| 302 | 临时搬迁 |
| 307 | 临时重定向 |
| 304 | 未修改 |
| 4xx | 客户端错误 |
| 400 | 错误的请求 |
| 401 | 未经授权 |
| 403 | 禁止 |
| 404 | 未找到 |
| 405 | 不是方法 |
| 406 | 不接受 |
| 413 | 实体太大 |
| 414 | URI 太长 |
| 5xx | 服务器错误 |
| 500 | 内部错误 |
| 501 | 未实施 |
| 503 | 不可用 |
| 412 | 前提 |
| 415 | 无媒体类型 |
| 417 | 失败的 |
以上是主要的错误代码及其描述,供参考和使用。
掌握错误代码固然重要,但仅此并不足够。消费者不应猜测在 API 中实现的所有错误代码。建议直接在 Swagger 描述文件的定义中记录所实现的错误。以下是描述响应的示例,展示了如何记录错误代码:
responses:
'200':
description: OK.
'400':
description: Bad request. Parameter should be a string.
'401':
description: Authorization failed.
'404':
description: Not found.
'5XX':
description: Internal error.此外,至少出于调试原因,应该添加一个错误结构,即动态错误消息和代码包含在专用结构中:
responses:
'400':
description: Bad request
content:
application/json:
schema:
$ref: '#/components/schemas/Error'这样的记录方式能更清晰地帮助消费者理解可能出现的错误情况。
粒度和 KISS 原则
模式:保持 API 简单易读;以中粒度资源为目标
粒度和 KISS 原则相辅相成。KISS,代表“保持简单*!”将促使定义一种粒度策略,旨在为最终用户(开发人员)提供最简便的使用体验。以下是 KISS 下的设计范式:
- 设计 API 时要考虑客户和开发人员,避免复制/粘贴自己的数据模型(至少出于安全原因)。
- 首先设计主要用例,然后再考虑其他用例。
- 使用通用术语而非商业用语进行设计。
- 设计时应确保开发人员只有一种实现功能的方法。
在这种思维模式下,细粒度和粗粒度的 API 并不协调。细粒度 API 会增加额外的复杂性,而粗粒度 API 则可能导致混乱,因为同一级别的资源可能彼此无关。以下是宠物店的示例:
不建议:
// 细粒度
GET /animals/mammals/omnivores/cats
// 粗粒度
GET /cats
GET /payments应瞄准中等粒度的 API,通常结构应不超过两个级别的 API 资源,这是适合的粒度级别。
对于宠物店,可以执行以下操作:
GET /animals/cats或:
GET /animals/42
{
"id": "42",
"animalType": "cat",
"cat": {
"mustacheSize": "7",
"cuteness": "maximum"
}
}最终目标是让任何人都能使用 API,而无需参考文档。
网址
模式:使用名词而不是动词,建立层次结构,维护命名约定,包含版本,并使用正确的 HTTP 方法
单数和复数名词
与 SOAP 理念相反,REST 原则围绕资源设计,通常应使用名词。
示例:
做:
GET /orders不建议:
不:
GET /Getorders使用复数名词可同时处理资源集合和单个资源:
示例:
做:
GET /orders
GET /orders/042不建议:
不:
GET /Getorders这样可以保持一致且易于使用的结构。
层次结构
资源应有结构,使用 URL 路径获取详细信息。例如,客户由 ID、姓名和地址定义,可以将客户编号称为“id”,再使用“addresses”:
GET /customers/042/addresses一致性
必须定义命名约定,尤其是“大小写策略”,以确保资源中字母大小写的一致性。对于参数,常用 snake_case 和 camelCase。虽然没有绝对理由偏向某种方式,但开发人员通常更偏好驼峰命名法,因为它在 Java 中被广泛使用,而蛇命名法更易于非技术人员阅读。同时,URL 通常使用脊髓大小写,因为某些服务器不区分大小写。
以下是每种情况的示例:
- 驼峰命名法:
GET /customers?countryCode=US - 蛇命名法:
GET /customers?country_code=US - 脊髓大小写:
GET /vip-customers
版本控制
版本必须包含在 URL 中,以帮助开发人员轻松从一个版本迁移到另一个版本。这也能避免破坏客户端集成。版本控制至关重要,最简单的方法是将其包含在 URL 中。这样,API 调用会记录在服务器上,便于查看调用了哪个版本的 API。
应保持向后兼容性,支持至少两个以前的版本:
GET /v1/customers
GET /v2/customersHTTP 方法
必须将 HTTP 方法(动词)用于其指定目的。HTTP 设计初衷是围绕资源,描述 HTTP 方法以对资源执行特定操作。
- GET 检索资源数据:
- 对于集合:
GET /customers
200 OK
[{"id":"42", "name":"John Doe"}, {"id":"43", "name":"Elisa Re"}] - 对于单个实例:
GET /customers/42
200 OK
{"id":"42", "name":"John Doe"}
- 对于集合:
- POST 创建新资源:
- 对于集合:
POST /customers {"name":"John Doe", "countryCode":"US"}
201 Created
Location: https://myapi.com/customers/42
- 对于集合:
- PUT 替换或创建资源:
- 对于单个实例:
PUT /customers/42 {"name":"John Si", "countryCode":"US"}
200 OK
- 对于单个实例:
- PATCH 对资源进行部分更新:
- 对于单个实例:
PATCH /customers/42 {"countryCode":"UK"}
200 OK
- 对于单个实例:
- DELETE 删除现有资源:
- 对于单个实例:
DELETE /customers/42
204 OK
- 对于单个实例:
验证
对正确数据的正确访问是任何集成项目的基础,但身份验证可能是最困难的部分之一。身份验证的核心在于证明应用程序身份的能力。应用程序可以通过多种不同方式向开发人员授予访问权限以创建集成。
模式:根据业务需求遵循行业认可的身份验证和身份协议
API 密钥
API 密钥的使用仍然很普遍,并且对于 API 访问而言非常常见。这是一种快速、简单的帐户身份验证方法,且对于提供商来说开销相对较低,因为他们可以轻松创建和撤销 API 密钥。API 密钥是一组唯一生成的字符,有时是随机的,通常以一对形式发送,即用户和秘密。收到 API 密钥后,建议将其复制并存储在密码管理器中,并像对待其他密码一样谨慎处理。
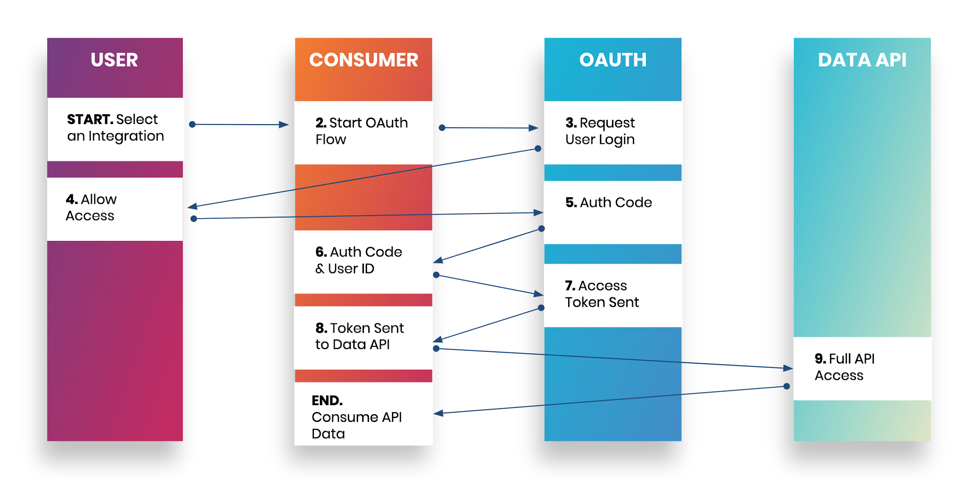
OAuth 2.0 和 OpenID Connect
OAuth 与 API 密钥有所不同,因为它是基于令牌的。OAuth 包含三个主要组件:用户、消费者(集成应用程序)以及服务提供者。在此过程中,用户在从 API 访问数据之前,通过 OAuth 端点交换令牌,从而授予消费者对服务提供商的访问权限。
OAuth 是首选的身份验证方法,因为它允许用户决定集成应用程序可以拥有的访问级别,并能设置基于时间的限制。一些 API 的时间限制较短,需要使用刷新令牌。OpenID Connect 是 OAuth 2.0 的标准化扩展,增加了一层标准化的第三方身份和用户身份验证。并非所有 API 提供商都要求使用 OpenID Connect,但如果需要细粒度的授权控制并管理多个身份提供商,则建议使用它。
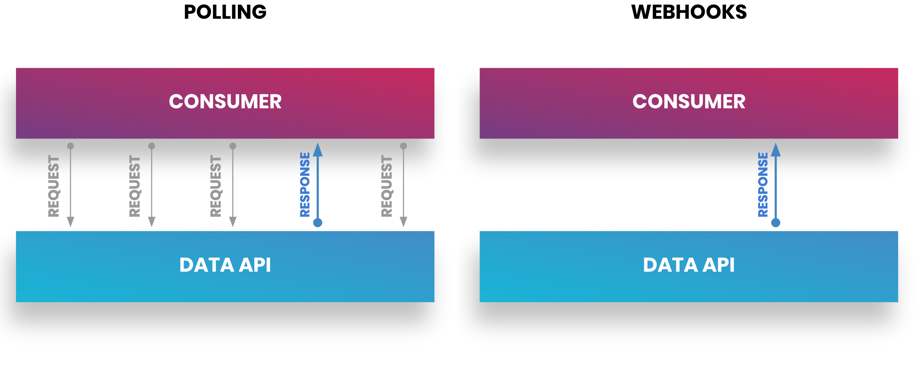
Webhook
Webhook 允许实时获取更新,因为它们是基于推送而非拉取的。在此方法中,当应用程序发生更新时,会将数据发送到为应用程序指定的 URL。这种基于推送的信息更新使应用程序能够实时更新,从而创建动态用户体验。此外,Webhook 是首选模式,因为实现只需一个 URL,而轮询则需要创建一个框架来管理所需信息的接收频率和范围。例如,Marketo 的轮询框架需要 239 行代码,而相应的 Webhook 实现仅需 5 行代码。
查询
模式:在参数中使用通用的关键字和字符来查询、搜索和分页
虽然数据移动已实现自动化,使集成实时流畅,但常常只需获取对应用程序操作有用的一小部分数据。因此,需要设置查询参数以过滤掉不必要的数据。
查询是 API 端点或路径的最后一部分,用于指示调用仅提取所需的数据:
GET /widgets?query_parameter_here搜索数据库和目标应用程序的能力至关重要,这使得可以测试和确认响应,并检查返回内容与文档数据结构之间的差异。查询允许修改请求的键值对。查询以问号(?)开头,并用与号(&)分隔。例如:
GET /widgets?type=best&date=yesterday要测试端点,常用的选项取决于所用语言,大多数 API 文档会引用 curl 命令。打开终端并复制/粘贴 curl 命令,以查看返回的响应。调整键值对以获取目标端点所需的信息时,记得在查询的问号前添加反斜杠(/),因为 ? 和 & 是特殊字符。
通过调整这些对,可以减少应用程序的预期大小和开销。可以增加数据量(尤其是在测试中)以查看潜在错误。
过滤器
使用 ? 来过滤资源,& 作为参数之间的分隔符:
GET /widgets?type=best&date=yesterday搜索
搜索资源的首选模式通常是使用关键字,如同 Google 搜索。例如,搜索特定资源时:
GET /customers/search?type=vip搜索多个资源时:
GET /search?q=customers+vip第一个、最后一个和计数关键字
使用 first、last 和 count 获取集合中的第一个项目、最后一个项目和项目数:
GET /customers/first
GET /customers/last
GET /customers/count排序和排序
获取所需信息的一部分是数据的呈现方式,这对于 UI 测试和数据展示尤其重要。许多 API 支持在 URL 中使用 sort、sort_by 或 order 参数,以更改数据的升序或降序。例如:
GET /widgets?sort_by=desc(created)分页
模式:对 Web 前端和移动应用使用分页方法
分页依赖于一个或多个字段的隐含顺序,如唯一 ID、创建日期和修改日期。可以实施几种不同类型的分页策略。
部分响应
在某些情况下,不需要获取定义对象的所有字段。部分响应在移动用例中特别有用,能优化带宽。使用 fields 关键字获取特定字段:
GET /customers/42?fields=name,status抵消
抵消分页是最常见的方法,使用 LIMIT 来指定要返回的行数,OFFSET 来指定结果的起点。例如:
GET /widgets?limit=10
GET /widgets?limit=10&offset=10但是,对于大型数据集,性能可能会降低,因为在返回请求的限制之前,系统需要跳过前面的行。
按键设置
键集分页使用最后一页结果的过滤器值作为下一页结果的起点,避免处理大量数据。例如,第一个调用可以是:
GET /widgets?limit=10第二个调用可能是:
GET /widgets?limit=10&created:lte:2019-09固定数据页
这种方法较为简单,通过添加查询参数指定返回的数据页。例如,返回第四页结果:
GET /widgets?page=4如果不确定第四页的内容,使用此方法可能会带来困惑。
灵活的数据页
与固定数据页类似,但可以指定页面大小:
GET /widgets?page=4&page_size=25这在构建 UI 时尤其有用,确保返回的结果符合一定大小的要求。
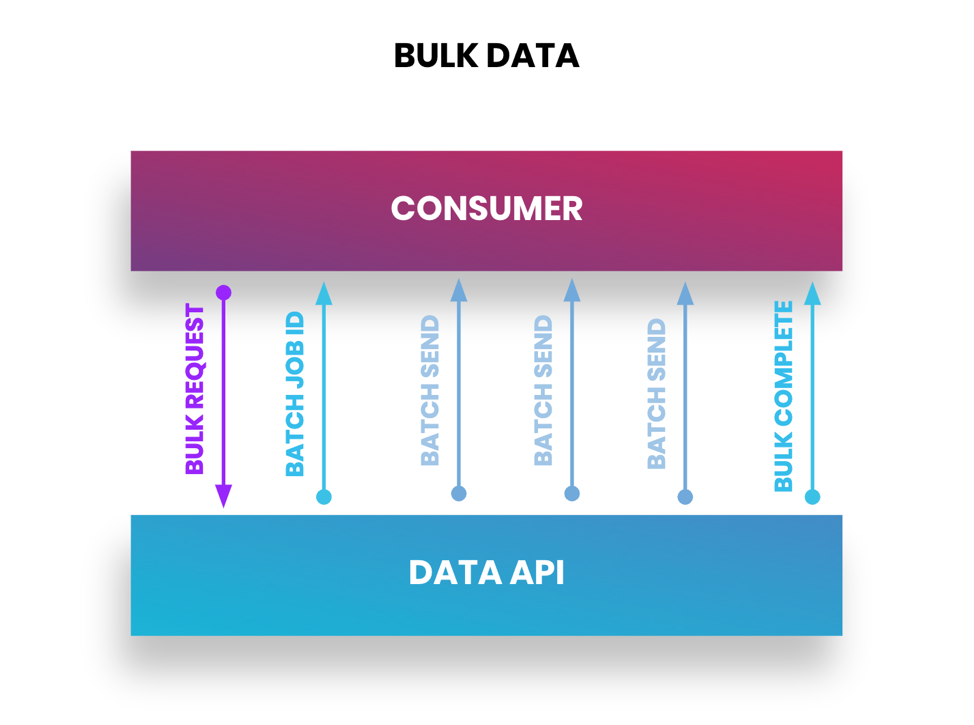
批量操作
到目前为止,API 集成主要关注特定的数据集,但是当您需要将大量数据从一个系统移动到另一个系统时会发生什么?一些应用程序通过批量 API 公开了此功能。批量 API 允许您一次更新、插入和删除大量记录。当将大型记录系统(例如,营销自动化、CRM、ERP)从一个提供商转移到另一提供商时,这一点尤其有用。
模式:对大量数据使用批量数据传输
当批量作业的请求发送到应用程序提供商时,批量操作会在多批数据集中进行操作。应用程序提供商将异步发送批次以完成作业。根据数据集的大小,作业还将向您发送一个唯一标识符,以检查作业状态并在完成后关闭作业。请务必仔细检查批量 API 将提供的文件类型 – CSV、JSON 或 XML。此外,如果您没有获取完整的数据集,请务必检查适用的任何 API 速率限制,因为大数据传输可能会超出这些限制。
软件开发工具包
许多 API 提供商提供 SDK 来帮助用户轻松集成它们,其中包括设置 API 的接口、方法、错误处理、访问安全性等。随着 API 的修改,用户必须管理代码的更改;因此,SDK 的更新速度必须与 API 本身相同,更不用说对版本升级、调试和开发人员错误的支持。
模式:提供一个 SDK 来帮助开发人员使用您的 API
SDK 还允许您加密数据并加强安全要求(例如,存储密码)。特别是对于医疗和金融领域,SDK 可以帮助强制用户遵守相关法规。以下是开发 SDK 的几种做法:
- 尽可能在同一个 HTTP 调用中以批量形式进行互操作,因为会话和连接的打开是非常耗时的。当不需要同时接收调用时,可以设置排队系统。
- 压缩有效负载;调用 API 时很容易忘记这一点,您最好不要在 SDK 中忽视它。
- 在 User-Agent 标头中填写 SDK 版本号和 SDK 语言,这将提供有关采用新版本 SDK 的信息。
- 设置 API 分析来衡量使用情况和性能,并查看可以对 SDK 进行哪些改进。
- 提供最流行的语言,尤其是 API 的目标开发人员最常使用的语言。
- 全面记录 SDK,包括完整的变更日志及其参数化。
结论
当组织实施本参考卡中的 API 集成模式时,管理健全的 API 管理原则是 API 旅程中的下一个成熟度级别。API 管理通常是现有 API 之上的一层,允许组织实施更深入的安全性和治理,从而更好地控制 API 的使用对象和方式。这些做法包括限制客户端在给定时间段内发出的 API 请求数量、通过修改请求或响应正文来允许流量整形、添加高级身份验证和授权、在开发人员门户中公开 API,以及通过可观察性和分析提供更高的透明度。