AI、机器学习、深度学习与神经网络:有何区别?
文章目录
这些计算机科学术语经常被交替使用,但它们之间有什么区别,使得每种技术都独具特色?
技术正日益融入我们的日常生活。为了跟上消费者期望的步伐,公司越来越依赖机器学习算法来简化事情。你可以看到它在社交媒体(通过照片中的物体识别)或直接与设备对话(如 Alexa 或 Siri)中的应用。
虽然人工智能(AI)、机器学习(ML)、深度学习和神经网络是相关的技术,但这些术语经常被交替使用,这经常导致人们混淆它们之间的区别。本文将澄清一些模糊之处。
一、人工智能、机器学习、深度学习和神经网络之间有什么关系?
思考人工智能、机器学习、深度学习和神经网络的最简单方法是将它们视为一系列从大到小的人工智能系统,每个系统都包含下一个系统。
人工智能是总体系统。机器学习是人工智能的一个子集。深度学习是机器学习的一个子领域,神经网络是深度学习算法的支柱。单个神经网络与深度学习算法的区别在于神经网络的节点层数或深度,深度学习算法必须有三个以上的节点层。
二、什么是人工智能(AI)?
人工智能是三个术语中最宽泛的一个,用于对模仿人类智能和人类认知功能(如解决问题和学习)的机器进行分类。人工智能利用预测和自动化来优化和解决人类历来要完成的复杂任务,如面部和语音识别、决策和翻译。
1、人工智能的类别
人工智能的三大类别是:
人工狭义智能(ANI)
人工通用智能(AGI)
人工超级智能(ASI)
ANI 被认为是 "弱 "人工智能,而其他两类则被归为 "强 "人工智能。我们根据人工智能完成特定任务的能力来定义弱人工智能,例如赢得一盘国际象棋或在一系列照片中识别出特定的个人。聊天机器人和虚拟助手提供支持,它们就是 ANI 的例子。计算机视觉是开发自动驾驶汽车的一个因素。
更强的人工智能形式,如 AGI 和 ASI,更突出地融入了人类行为,如解读语气和情感的能力。强人工智能是根据其与人类相比的能力来定义的。人工通用智能(AGI)的表现将与人类相当,而人工超级智能(ASI)–也被称为超级智能–将超越人类的智力和能力。这两种形式的强人工智能都还不存在,但这一领域的研究仍在进行中。
2、将人工智能用于商业
越来越多的企业(全球约 35%)正在使用人工智能,另有 42% 的企业正在探索这项技术。生成式人工智能使用强大的基础模型,在大量无标记数据上进行训练,可适应新的使用案例,并带来灵活性和可扩展性,这可能会大大加快人工智能的应用。在早期测试中,IBM 发现生成式人工智能的价值实现时间比传统人工智能快达 70%。
无论您使用基于 ML 或基础模型的人工智能应用,人工智能都能为您的企业带来竞争优势。将定制的人工智能模型集成到您的工作流程和系统中,并实现客户服务、供应链管理和网络安全等功能的自动化,可以帮助企业满足客户的期望,无论是现在还是将来。
关键是从一开始就确定正确的数据集,以帮助确保您使用高质量的数据来实现最实质性的竞争优势。您还需要创建一个混合的、人工智能就绪的架构,无论数据存在于主机、数据中心、私有云、公有云还是边缘,都能成功使用。
您的人工智能必须值得信赖,因为任何不值得信赖的东西都意味着公司声誉受损和监管罚款的风险。误导性模型、包含偏见或产生幻觉的模型会让客户的隐私、数据权利和信任付出高昂的代价。您的人工智能必须是可解释的、公平的和透明的。

三、什么是机器学习?
机器学习是人工智能的一个子集,可以进行优化。如果设置得当,它可以帮助你进行预测,最大限度地减少仅凭猜测而产生的错误。例如,亚马逊等公司利用机器学习,根据特定客户之前查看和购买过的产品向其推荐产品。
经典或 "非深度 "机器学习依赖于人工干预,使计算机系统能够识别模式、学习、执行特定任务并提供准确结果。人类专家决定特征的层次结构,以了解数据输入之间的差异,通常需要更多的结构化数据来学习。
例如,假设我向你展示了一系列不同类型快餐的图片–"披萨"、"汉堡 "和 "玉米卷"。人类专家在处理这些图片时,会判断出每张图片区别于特定快餐类型的特征。每种食品中的面包可能就是一个区分特征。或者,他们也可以使用标签,如 "披萨"、"汉堡 "或 "玉米卷",通过监督学习来简化学习过程。
虽然被称为深度机器学习的人工智能子集可以在监督学习中利用标签数据集为算法提供信息,但它并不一定需要标签数据集。它可以摄取原始形式的非结构化数据(如文本、图像),并能自动确定将 "披萨"、"汉堡 "和 "玉米卷 "区分开来的特征集。随着我们产生更多的大数据,数据科学家将使用更多的机器学习。如需深入了解这些方法之间的差异,请参阅《监督学习与非监督学习》(Supervised vs. Unsupervised Learning):有什么区别?
机器学习的第三类是强化学习,即计算机通过与周围环境互动并获得行动反馈(奖励或惩罚)来学习。在线学习是一种 ML,数据科学家会在获得新数据时更新 ML 模型。
四、机器学习和深度学习的区别
正如我们关于深度学习的文章所述,深度学习是机器学习的一个子集。机器学习和深度学习的区别在于每种算法如何学习,以及每种算法使用多少数据。
深度学习能自动完成大部分特征提取工作,从而省去了部分人工干预。它还能使用大型数据集,因此被称为可扩展的机器学习。当我们进一步探索非结构化数据的使用时,这种能力令人兴奋,特别是因为据估计,一个组织 80% 以上的数据都是非结构化的。
观察数据中的模式可以让深度学习模型对输入进行适当的聚类。以前面的例子为例,我们可以根据图像中的相似点或不同点,将披萨、汉堡和墨西哥卷饼的图片归入各自的类别。深度学习模型需要更多的数据点来提高准确性,而机器学习模型由于其底层数据结构,所依赖的数据更少。企业通常将深度学习用于更复杂的任务,如虚拟助手或欺诈检测。
机器学习和深度学习的区别常见问题FAQ
- 机器学习和深度学习的区别?
- 机器学习是人工智能的一个分支,它使计算机能够从数据中学习和提高性能,而不需要明确编程。深度学习是机器学习的一个子集,它使用类似于人脑结构的神经网络(特别是深层神经网络)来模拟人类学习过程。
- 深度学习为什么被称为“深度”?
- “深度”一词指的是神经网络中的层数。深度学习模型通常包含多个隐藏层,这些层可以捕捉数据中的复杂模式和抽象。
- 深度学习是否总是比机器学习更好?
- 不一定。虽然深度学习在图像和语音识别等领域表现出色,但对于某些问题,传统的机器学习方法可能更为简单和有效。
- 深度学习模型需要大量数据吗?
- 是的,深度学习模型通常需要大量的标记数据来训练,以便学习数据中的模式。而机器学习模型可能不需要那么多数据,特别是如果它们使用更简单的算法。
- 机器学习和深度学习的区别,在计算资源上有何不同?
- 深度学习模型由于其复杂的结构,通常需要更多的计算资源,如GPU或TPU,而传统的机器学习模型可能只需要CPU。
- 深度学习可以应用于哪些领域?
- 深度学习可以应用于计算机视觉、自然语言处理、语音识别、推荐系统、游戏和模拟等多个领域。
- 机器学习模型有哪些类型?
- 深度学习模型有哪些类型?
- 如何选择合适的机器学习或深度学习模型?
- 选择模型通常取决于问题的性质、数据的类型和量、计算资源的可用性以及项目的具体需求。
- 机器学习和深度学习是否需要专业知识?
- 是的,这两个领域都需要对算法、数据处理和模型评估有深入的理解。然而,随着各种工具和库的发展,入门的门槛正在逐渐降低。

五、什么是神经网络?
神经网络,也称为人工神经网络(ANN)或模拟神经网络(SNN),是机器学习的一个子集,也是深度学习算法的支柱。它们之所以被称为 "神经 "网络,是因为它们模仿了大脑神经元相互传递信号的方式。
神经网络由节点层(一个输入层、一个或多个隐藏层和一个输出层)组成。每个节点都是连接下一个节点的人工神经元,每个节点都有权重和阈值。当一个节点的输出高于阈值时,该节点就会被激活,并将数据发送到网络的下一层。如果低于阈值,则没有数据传输。
训练数据可以教导神经网络,并有助于随着时间的推移提高其准确性。一旦对学习算法进行了微调,它们就会成为强大的计算机科学和人工智能工具,因为它们能让我们快速对数据进行分类和聚类。利用神经网络,语音和图像识别任务可以在几分钟内完成,而不是像人工识别那样需要几个小时。谷歌的搜索算法就是神经网络的一个著名例子。
六、深度学习和神经网络有什么区别?
了解了机器学习和深度学习的区别之后,我们再来了解下深度学习和神经网络的区别,如上文对神经网络的解释所述,但值得更明确地指出的是,深度学习中的 "深度 "指的是神经网络的层深度。包括输入和输出在内,层数超过三层的神经网络可视为深度学习算法。这可以用下图来表示:
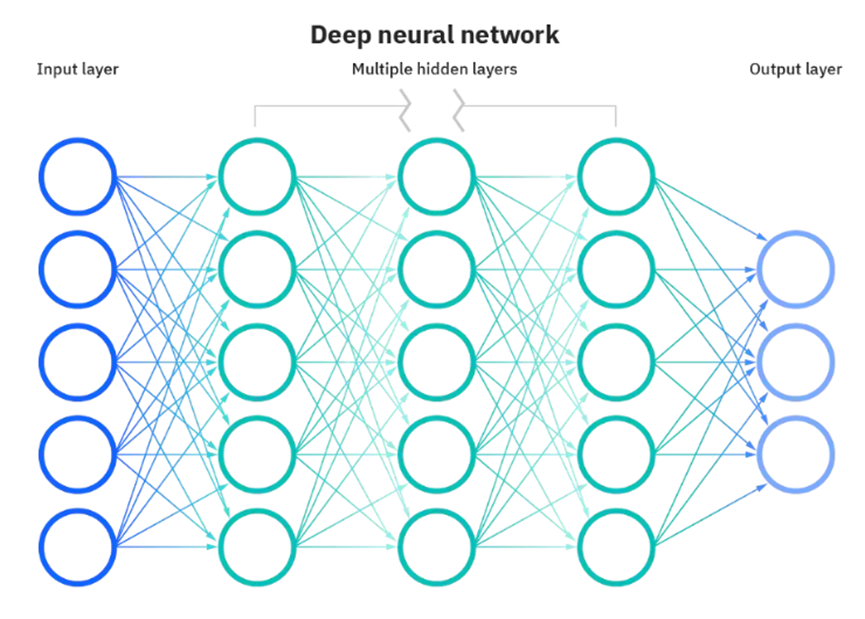 大多数深度神经网络都是前馈式的,这意味着它们只能从输入向输出单向流动。不过,您也可以通过反向传播来训练模型,即从输出到输入的反向传播。通过反向传播,我们可以计算和归因与每个神经元相关的误差,从而对算法进行适当的调整和调整。
大多数深度神经网络都是前馈式的,这意味着它们只能从输入向输出单向流动。不过,您也可以通过反向传播来训练模型,即从输出到输入的反向传播。通过反向传播,我们可以计算和归因与每个神经元相关的误差,从而对算法进行适当的调整和调整。
七、管理人工智能数据
虽然所有这些人工智能领域都能帮助您简化业务领域并改善客户体验,但实现人工智能目标可能具有挑战性,因为您首先需要确保拥有正确的系统来构建学习算法并管理数据。数据管理不仅仅是建立业务模型。在开始构建任何东西之前,您需要一个存储数据的地方以及清理数据和控制偏差的机制。
在 IBM,我们正在将机器学习和人工智能的力量结合到我们用于基础模型、生成式人工智能和机器学习的新工作室 watsonx.ai。
原文链接:AI vs. Machine Learning vs. Deep Learning vs. Neural Networks: What’s the difference?