如何免费调用有道翻译API实现多语言翻译

动作识别(Action Recognition)是计算机视觉领域的一个重要分支,它涉及到识别和理解视频中的人物动作。这项技术在多个领域都有应用,如视频监控、人机交互、健康监测等。随着深度学习技术的发展,动作识别的准确性和效率都有了显著提升。
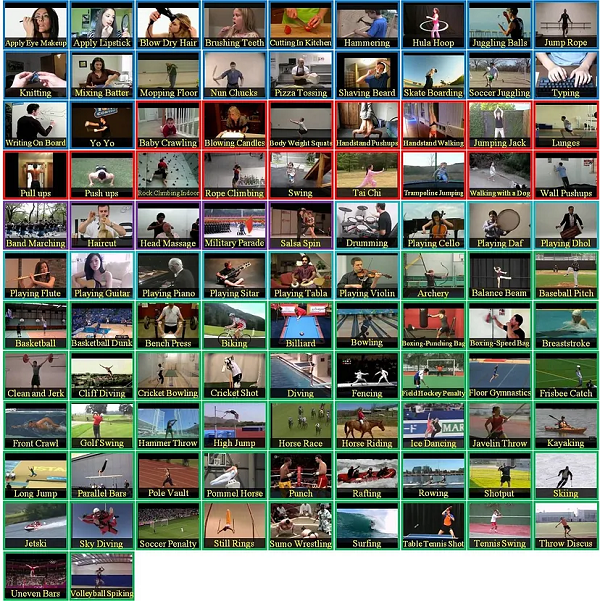
一个最受欢迎的学术数据集包含 2-20 秒的涉及人物情景的镜头片段:
第二受欢迎的数据集包含来自附在衣服上的摄像机的记录:
但这只是其中很小的一部分。还有“动作分类”、“视频分类”和“自监督动作识别”等任务(这些是部分重叠的任务 1、2、3)。有带骨架的数据集;有带烹饪过程的数据集:

在某些数据集中,它是短视频;无关紧要的是长视频。
什么是动作?动作是可以在视频上标记的事件,并且事先知道它可以在那里发生。人、机器、动物或其他东西可以产生事件。为什么我更喜欢这个定义?通常,在实践中(99% 的时间),动作识别用于某些确定性过程。确定发生了需要计数/说明/控制的某些事件。
对于实际的 ComputerVision 任务,这个定义通常是正确的,但对于需要“通用定义”的学术研究来说,它并不那么好。它也不适用于所有视频流和内容分析系统。
它有什么不同?什么是“现实世界的任务”?实际任务通常具有有限的数据、摄像机位置和情况。例如,我从未见过需要从任何角度找到 400 种不同动作的任务。相反,现实世界的问题可能是这样的:
这只是其中很小的一部分。但仍然:
我将描述的方案通常适用于许多任务。我将从比学术方法简单得多的方法开始。并以更具实验性和学术性的方法结束。
为了清楚起见,在大多数例子中,我将使用人作为参考,从侧面某处看。
我不会在这里写。相同的算法用于视频分析任务。我相信 Youtube 和 Netflix 有很多动作识别和视频分类。
好的,让我们从一个基本想法开始。假设你想识别某人何时按门铃。你将如何做?
在这种情况下,你能做的最后一件事是从 Papers With Code 的首选开始运行训练。毕竟,从以下内容检测某些东西要容易得多:
你不需要火箭科学。一个训练有素的检测器和良好的定位相机就可以工作。工作结果将得到保证和可解释。例如,如果没有检测到手,你可以了解原因 – 并尝试重新训练它(手套/奇怪的光线等)。
所以。物体检测->检查工作区域->检查相关条件工作非常出色:
基本思路是,你不需要行动;你需要了解发生了什么。
方法大致相同,其中动作描述是对象。当然,“在一般情况下”,你手中的煎锅并不意味着什么。但是,了解摄像头安装的环境,它可能是在厨房里“做饭”,在商店里“卖东西”,或者在 PUBG 中“打架”。
通过结合“位置”和“对象”之间的逻辑,你可以组合长动作或动作序列。
对象可以是任何东西。框架中的衣服/产品/汽车等。
让我们继续讨论处理视频片段的方法。在这里,我会立即将“一段视频”的概念分成两种:
有什么区别?当你需要处理视频时,神经网络非常不方便。最好有更高的性能、更复杂的数据集和更苛刻的训练。一种摆脱处理视频的方法是预先检测骨架并使用它。这可能是:
人物骨骼
动物骨骼
手臂骨骼
脸部点模型
物体的骨架模型(汽车、沙发等)。当然,更有趣的是那些可以动态的模型,例如挖掘机/机器人/等
骨骼动画会丢失可能至关重要的纹理信息:衣服、与之交互的物体和面部表情……
也可以将两个领域的某些内容结合起来。例如,将骨骼用于可以从骨骼中识别出的部分动作。以及不能使用纹理信息的方法。
这里有一个很好的实现经典分类的方法集合:
MMAction 是一个基于 MMCV 和 PyTorch 的开发但粗糙的框架。它变得越来越好。但还远远不够完美。
PyTorchVideo 是 Facebook 尝试制作一个模拟,但它仍然很弱。但原生的 PyTorch。
从全局来看,任务是按原样设置的,现在仍然是。“输入一堆帧”(或骨架),输出动作。一切都始于 2D 卷积:
然后的发展对应于经典的“骨干,衰减”
将所有内容移至 TimesFormer(所有轴上的transformer)
现在他们甚至把 RL 放在了它之上
2023年最流行的是超大型预训练网络(我们稍后会谈到它们)。
注意:此外,所有基准测试通常都在不同的数据集上,因此您无法进行比较。
可能需要注意的是,所有方法都存在相同的问题:
关于“使用整个视频”与“使用裁剪视频”的工作。选择算法时不要忘记这一点,并正确选择它。你可以一次识别整个视频,也可以识别人物的区域(预先检测和跟踪)。在第一种情况下,帧中有许多人时会出现问题。但是,当帧中有大量信息来帮助识别动作时,它会很好地工作。
此外,关于骨骼动画分类的几句话:那里没有什么魔法。文章很少。最好的作品是 PoseC3D,它属于上述 MMAction。这些作品的主要区别在于精确使用卷积网络,而不是在点阵列上工作的经典方法:
但是,如你所见,该模型对于 2021 年来说足够简单。并且它有很多地方使用:
许多网络都在处理点阵列。但是,由于速度快,我更经常使用它们。
Papers with code中的 Zero-shot 带代码。自监督也在那里。
我能摆脱一些问题吗?是的。你可以摆脱数据集收集和训练。当然,这有利于准确性。
当前顶级方法使用类似 CLIP 的神经网络 + 一些技巧。例如,蒙版视频编码器(或其他一些技巧)。
一般来说,大多数方法都是基于创建一些表征动作的“嵌入”向量。
但当然,主要问题是一样的。训练数据集与你将使用的数据集有多远?
另一种流行的方法是自监督。当我们在数据集 A 上进行训练,用这个网络标记数据集 B,并在这个“自动标记”的数据上进行训练时。有时可以使用这种方法(当数据集很大但不容易标记时)。
这在近年来准确率如何进步的图像中也很明显,关于错误我们稍后会讨论。
随着最新的大型数据集预训练模型的发布,事情将变得相当简单。
以下是几个示例。这里许多动作都被骨骼成功识别(我与这家公司合作过很多次):
对于某些动作,1-2 个示例足以进行训练。但你必须非常小心选择实施的位置。
以下是有关该主题的一些学术论文和排序,以帮助构建逻辑。
当然,每个人都通过嵌入来实现这一点,但神奇之处在于如何创建它。
几年前在 ODS Data Fest 上,来自 Yandex 的人对人脸模型(68 分)说了类似的话(骨架嵌入),形成嵌入并使用它们来设置数据集/分类动作:
但视频是俄语的。
有几个项目为手生成了嵌入。其中一个是这样的:
我觉得应该有人在产品中使用它来识别/记住手势。我们已经使用了类似的方法进行时间手部过滤和咀嚼速度计算。
计算简单,易于训练(你不必在另一个数据集上进行训练),逻辑简单。如果将其与传统方法进行比较,错误也有所不同!
近年来的一个趋势是出现了强大的预训练网络。近年来最有趣的网络是 InterVideo。但到目前为止,只有一些声明的功能出现在开源中。它看起来很神奇:
并非所有事情都令人兴奋。这样的网络只需训练一次,因为要只教授网络的一部分,你需要 128 个 A100 持续两周。
在 Inter Video 的情况下,它是两个编码器的训练:
在此之后,对下游任务进行transformer训练。
未来几年,这一领域可能会取得重大进展。当前的实现将变得更快,使用调整的成本也更低。
然而,我描述了监督和无监督方法。哪一个更容易/更快/更方便?哪一个在哪里使用?
同样,这个问题没有明确的答案:
正如我之前提到的,在 OneShot 视频数据集上,错误率相差三倍。而在 OneShot 骨架和骨架之间的数据集上,错误率相差三倍,等等。
但在这里,你必须明白错误率并不统一。有些动作几乎可以完美地被 OneShot 识别。这些主要是与纹理没有交互的短动作。最好是没有变化的活动。例如,你可以用一百种方式“摔倒”。但“从地板上捡起盒子”可能只有一种正确方式,而有两三种方式是错误的。对于某些算法来说,角度至关重要。
容联云【AI视觉】提供视频采集+海量识别算法+智能检测+统计分析,深耕行业解决方案,包括 1、智慧营业厅——超柜代客检测、加钞间检测、箱包交接检测等相关算法 2、智慧加油站——卸油流程检测、加油区检测、便利店检测等
人体骨骼关键点 API 能够精确检测人体各部位的关键点及其位置,其中涵盖了头、颈、肩、肘、手、臀、膝、脚等多个部位。它可以帮助实现对人体姿态的准确分析和识别,在诸多领域都有重要应用价值。
识别图片中的手势类型,返回手势名称、手势矩形框、置信度等信息,可识别常见手势,适用于手势特效、智能家居手势交互等场景。识别质量受拍摄距离、图片质量影响,建议针对近距离单个手势进行识别,效果最佳。
人体分析-腾佑科技 API 服务,专注于人体分析领域。它能进行人体检测与追踪,精确实现关键点定位,还可准确进行人流量统计以及属性识别等多种检测,为相关应用场景提供强大的技术支持和精准的数据服务。
原文链接:http://www.bimant.com/blog/action-recognition-comprehensive-guide/