

AI Agent框架 – 7大认知框架全解析与代码讲解ai实现

使用大型语言模型(LLMs)进行工具学习已成为增强LLMs能力以解决高度复杂问题的一个有希望的范式。尽管这一领域受到越来越多的关注和快速发展,但现有的文献仍然分散,缺乏系统性的组织,为新来者设置了进入障碍。因此对LLMs工具学习方面的现有工作进行全面调查,从两个主要方面展开:(1)为什么工具学习是有益的;(2)如何实现工具学习,以全面理解LLMs的工具学习。根据工具学习工作流程中的四个关键阶段对文献进行了系统性审查:任务规划、工具选择、工具调用和响应生成。图1:工具学习发展轨迹的示意图。展示了按出版年份和会议统计的论文,每个会议由一种独特的颜色表示。对于每个时间段,选择了一些对领域有重大贡献的代表性里程碑研究。(使用第一作者的机构作为代表机构)
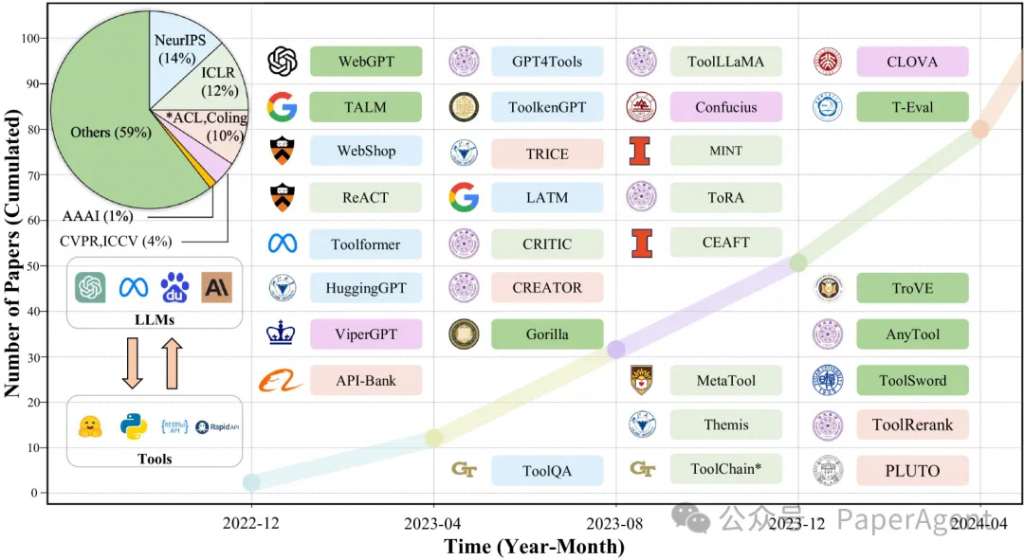
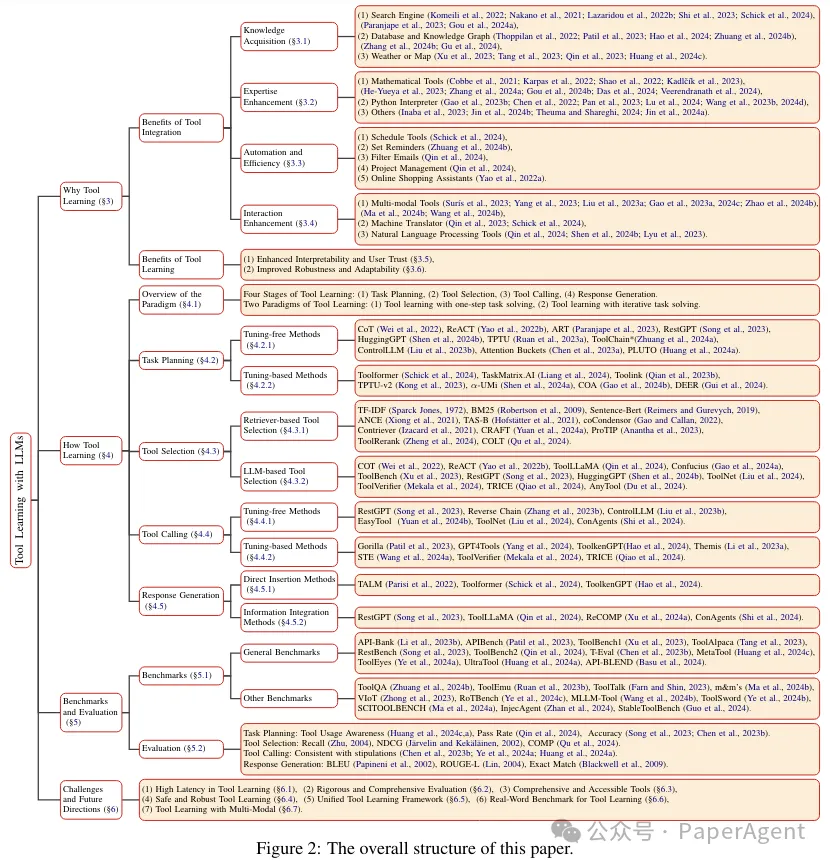
图2:总体研究结构框架
一方面,将工具整合到LLMs中可以增强多个领域内的能力,即知识获取、专业技能提升、自动化与效率以及交互增强。另一方面,采用工具学习范式可以增强响应的稳健性和生成过程的透明度,从而提高可解释性和用户信任度,以及改善系统的稳健性和适应性
图3:使用大型语言模型进行工具学习的整体工作流程。左侧部分展示了工具学习的四个阶段:任务规划、工具选择、工具调用和响应生成。右侧部分展示了两种工具学习范式:一步式任务解决的工具学习和迭代式任务解决的工具学习。
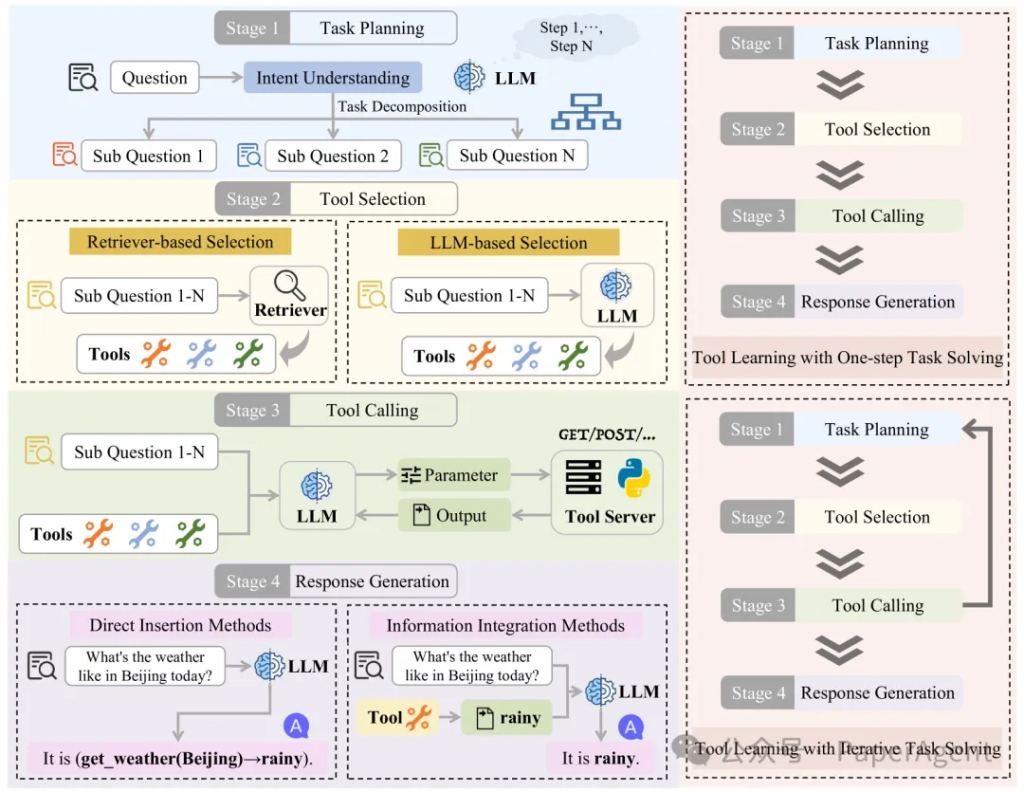



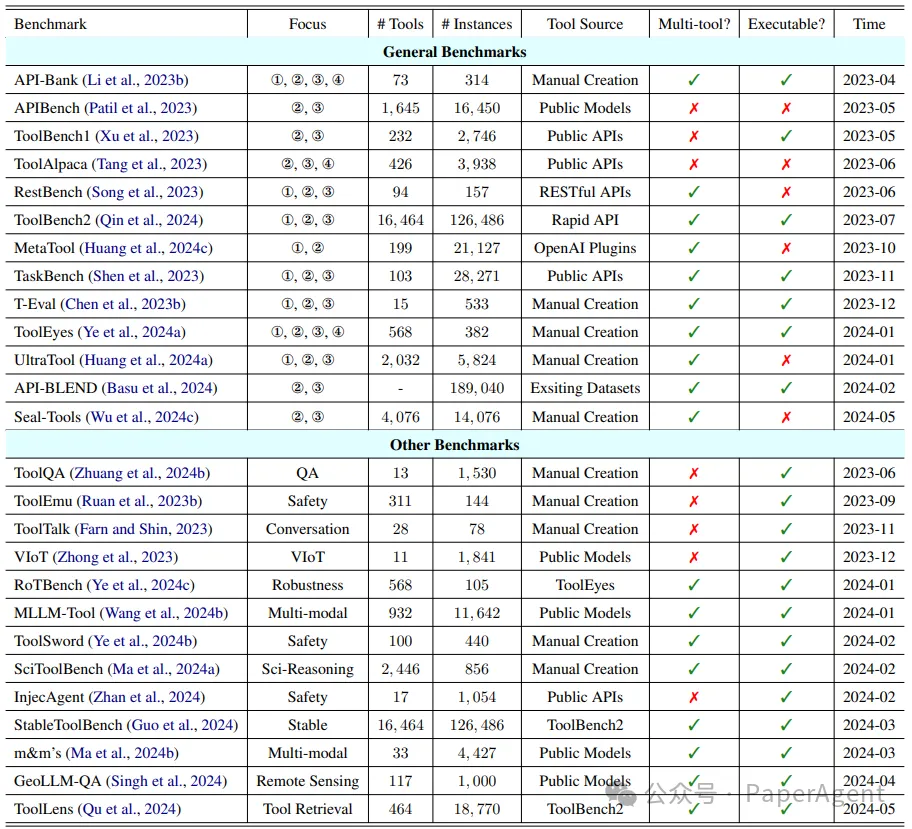
图4:不同基准测试及其具体配置的详细列表。符号①、②、③和④分别代表工具学习的四个阶段——任务规划、工具选择、工具调用和响应生成
Tool Learning with Large Language Models: A Survey
https://arxiv.org/pdf/2405.17935
https://github.com/quchangle1/LLM-Tool-Surve本文转自微信公众号@PaperAgent




