

ChatGPT生态系统的安全漏洞导致第三方网站账户和敏感数据泄露

文/王吉伟
著名AI学者、斯坦福大学教授吴恩达提出的AI Agent四种设计方式引发了全球范围内对Agentic Workflow(智能体工作流)的热潮,多个行业纷纷实践这一应用,并推动了新的Agentic AI探索浪潮。
随着技术的发展与应用的不断演进,我们已经进入了一个新的拐点。从大语言模型(Large Language Models,LLM)到AI Agent,再到Agentic Workflow,这些新兴技术一经推出便迅速得到应用。作为LLM的实际应用形式,AI Agent和Agentic Workflow因其在各种场景中的普适性和灵活性,其普及速度远超我们的预期。
比如在4月份文心智能体平台就已汇聚超5万开发者,创建智能体超过3万,还有30万创作者在文心一言APP创建了智能体,上线了40万个功能丰富的智能体,智能体调用量达8亿。在Coze平台,单是构建智能体能调用的插件就已超过100个。
在王吉伟频道的报道中,他提到了80多个AI代理构建平台,这些平台已经吸引了大量用户并创建了众多智能体。例如,OpenAI的GPT系列在今年1月就已经拥有超过300万个智能体。
随着智能体数量的激增,公众的担忧也随之增加。哈佛大学法学院教授、《互联网的未来》一书的作者Jonathan Zittrain在《The Atlantic》杂志上发表了一篇文章,表达了他的担忧。他指出,当智能体的数量达到数百万时,它们的行为可能会变得难以预测和控制,这可能会对人类社会造成不利影响。因此,他建议应该立即采取措施规范智能体的行为,并更新互联网标准,以确保智能体的发展不会脱离人类的控制,避免潜在的风险。
文章链接:https://www.theatlantic.com/technology/archive/2024/07/ai-agents-safety-risks/678864/
这篇文章同样反映出了Agentic Workflow技术的迅猛发展。
尽管Agentic Workflow技术已经取得了显著的成就,但公众和业界对其的理解仍存在一些误区。
吴恩达教授在讲解Agentic Workflow时,将其描述为一种与大型语言模型(LLM)互动并完成任务的策略。这种方法涉及将任务分解为多个阶段,并在每个阶段进行反复迭代,以指导系统逐步达到预期的结果。他还归纳了Agentic Workflow的四种设计模式:反思、工具使用、规划以及多智能体协作。
在实际操作中,智能体工作流的应用模式比我们通常所知的四种模式要丰富得多。例如,Coze平台不仅提供了多智能体和工作流功能,还扩展到了图像流领域。
通过插件、大型模型、代码、知识库、工作流、图像流、选择器、文本处理、消息、变量、数据库等多种元素构建的工作流,最终会被整合到“技能”模块中,形成一个智能体(Coze称之为Bot)。这些智能体能够执行更多任务,并参与到更复杂的业务流程中。
仔细观察可以发现,在大型语言模型(LLM)应用日益普及的背景下,许多工作流都是将传统业务流程与智能体工作流相结合的。这些工作流不仅包括了“四种模式”,还包括了将传统应用与生成式AI(GenAI)结合的工作流,以及直接应用大型语言模型的简单工作流。
一个典型的例子是,目前通过AI代理构建平台构建的智能体工作流还无法处理操作企业管理软件等复杂业务流程(受到API和连接能力的限制),而通过RPA等超自动化工具连接更多的简单智能体工作流是一种有效的解决方案。
同时,RPA等超自动化工具现在已经发展成为RPA Agent,使用RPA本身也是智能体工作流应用的一种形式。这种应用方式正在越来越多地被用于企业级业务场景。
在王吉伟频道的观点中,Agentic Workflow不仅仅是智能体工作流,它是一个包含传统软件(工具、解决方案)、大型语言模型、AI代理等在内的新型业务流程的集合。当传统业务流程包含了LLM工作流或Agent工作流时,都可以被视为Agentic Workflow。
特别是在大型语言模型代理化以及智能助手(如Copilot,具备反思、规划、工具使用能力,并能调用代理)代理化的趋势下,它们更符合Agentic Workflow的定义。
因此,研究Agentic Workflow不仅要关注AI代理和Agentic Workflow本身,还要关注大型语言模型及RPA等传统业务流程在LLM和Workflow方面的进展。
为了帮助大家更好地学习和理解Agentic Workflow,本文精选了25篇与智能体工作流相关的论文,并将其分为技术框架、系统(套件与工具)、评估测试基准、编程语言、模型与工作流及方法论六大类别,希望对读者有所启发。
Sibyl: Simple yet Effective Agent Framework for Complex Real-world Reasoning
论文地址:https://arxiv.org/abs/2407.10718
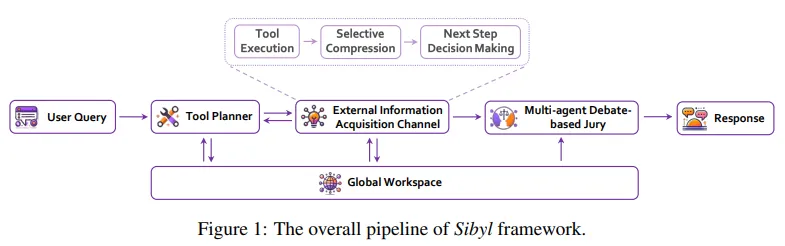
大型语言模型(LLM)集成了固有知识、上下文学习和零样本能力,展现出强大的问题解决能力。然而,现有智能体在长期推理和工具潜力利用方面存在不足,导致现实世界推理任务中的缺陷。为克服这些限制,Sibyl作为一个新型的LLM智能体框架,通过最少工具有效处理复杂推理任务。
Sibyl从全球工作空间理论中获取灵感,整合了全球工作空间,加强了系统知识和对话历史的管理与共享。在心智理论的指导下,Sibyl通过多主体辩论的陪审团机制自我完善答案,确保全面性和平衡性。这一设计旨在简化系统复杂性,拓宽问题解决范围,促进从系统1到系统2的思维转变。
Sibyl注重可扩展性和易调试性,采用函数式编程中的重入概念,以无缝集成到其他LLM应用中。在GAIA基准测试集中,Sibyl实现了34.55%的平均得分,展现了其先进性能。论文作者期望Sibyl能推动开发更可靠和可重用的LLM智能体,以应对复杂的现实世界推理挑战。
PEER: Expertizing Domain-Specific Tasks with a Multi-Agent Framework and Tuning Methods
论文地址:https://arxiv.org/abs/2407.06985
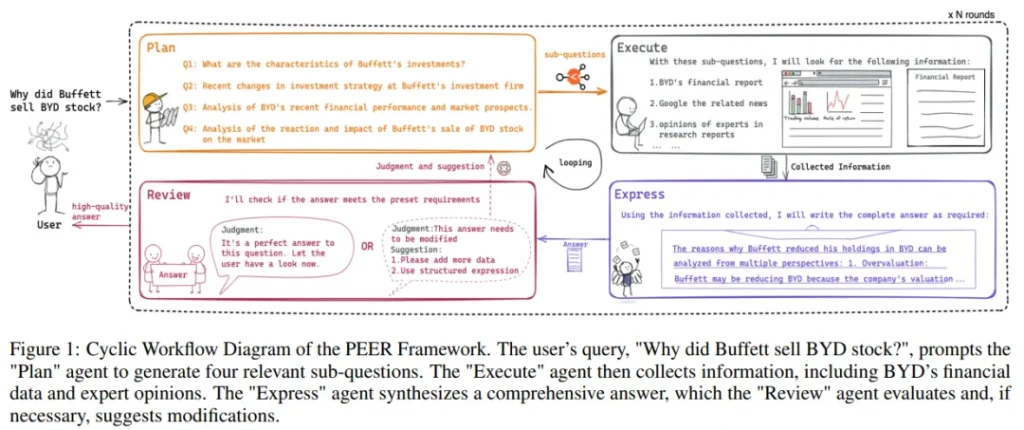
在专业领域应用中,GPT-4 通过精确的提示和检索增强生成(RAG)技术展现出巨大潜力,但同时也面临性能、成本和数据隐私的三重困境。高性能需求往往需要复杂的技术处理,而要管理多个智能体在复杂工作流程中的表现,不仅成本高,难度也大。
为应对这些挑战,论文提出了 PEER(规划、执行、表达、审查)多智能体框架。该框架通过整合精细的问题拆解、高效的信息检索、综合的总结能力以及严格的自我评估,系统化地处理专业领域任务。
考虑到成本和数据隐私的顾虑,许多企业正从 GPT-4 等专有模型转向定制模型,以期在成本、安全性与性能之间找到平衡点。团队利用在线数据和用户反馈,开发了一套行业实践,旨在实现模型的高效调整。
本研究提供了一套最佳实践指南,用于在特定领域问题解决中应用多智能体系统,并实施有效的智能体调优策略。特别是在金融问答领域的实证研究表明,该方法达到了 GPT-4 性能的 95.0%,同时在成本控制和数据隐私保护方面表现出色。
BMW Agents — A Framework For Task Automation Through Multi-Agent Collaboration
论文地址:https://arxiv.org/abs/2406.20041
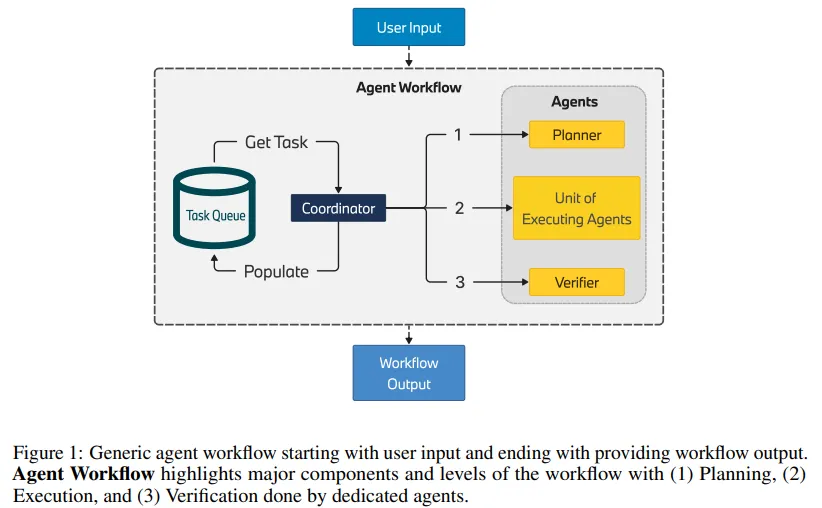
由大型语言模型(LLM)驱动的自主智能体展现了自动化的巨大潜力。技术的初步成效已在多个演示中显现,其中包括智能体解决复杂任务、与外部系统交互以扩展知识,以及触发必要操作。
特别是,多个智能体以协作方式共同解决复杂任务的场景,彰显了它们在非严格和非明确环境下的运作能力。因此,多智能体方法在许多工业应用中具有极大的应用潜力,无论是构建复杂的知识检索系统还是开发下一代机器人流程自动化。
考虑到当前LLM一代的推理能力,处理复杂流程需要采取多步骤策略,这包括制定明确定义的模块化任务计划。这些任务可以由单一智能体或一组智能体根据其复杂性执行。在本项研究中,团队专注于构建一个灵活的智能体工程框架,特别关注规划和执行阶段,以应对跨不同领域的复杂应用案例。
该框架能够为工业应用提供了所需的可靠性,并且为确保多个自主智能体能够协同工作、共同解决问题提供了一套可扩展、灵活且协作的技术流程。
Trace is the New AutoDiff — Unlocking Efficient Optimization of Computational Workflows
论文地址:https://arxiv.org/abs/2406.16218
项目地址:https://microsoft.github.io/Trace
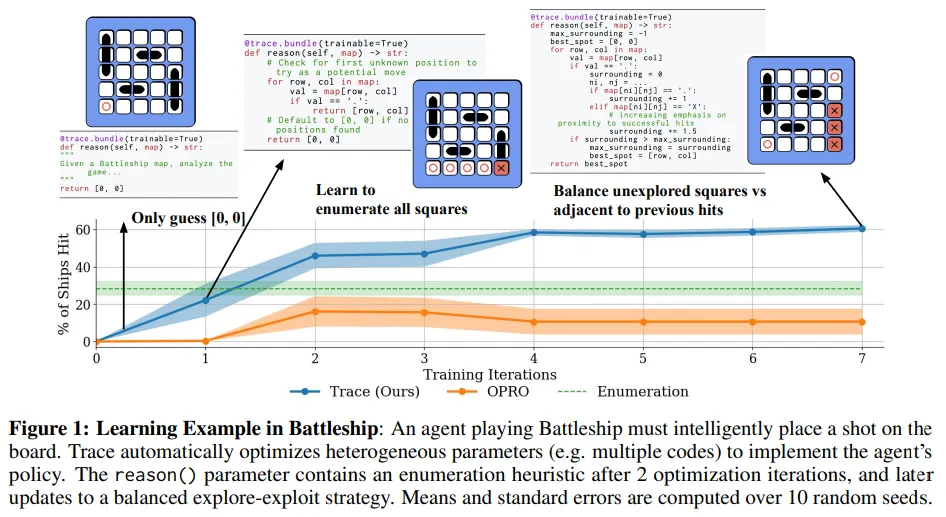
论文探索了一种针对自动化编码助手、机器人和副驾驶等人工智能系统的优化问题,研究团队开发了一个名为Trace的端到端优化框架,它将AI系统的计算流程视为神经网络图,并基于反向传播的泛化进行优化。这种优化处理了包括丰富反馈、异构参数和复杂目标在内的多种因素,并能适应动态变化的计算图。
Trace框架通过一种新的迭代优化数学设置——使用跟踪预言机优化(OPTO)——来捕获和抽象AI系统的特性,以设计跨领域的优化器。在OPTO中,优化器通过接收执行跟踪和输出反馈来迭代更新参数。Trace提供了一个Python接口,利用类似PyTorch的接口高效地将计算流程转换为OPTO实例。
利用Trace,团队开发了一个名为OptoPrime的通用优化器,它基于LLM,能够解决多种OPTO问题,包括数值优化、提示优化、超参数调优、机器人控制器设计和代码调试等,且性能可与领域内专业优化器相媲美。论文认为,Trace、OptoPrime和OPTO框架将推动下一代交互式智能体的发展,使其能够利用各种反馈实现自动适应。
RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models
https://arxiv.org/abs/2310.16340
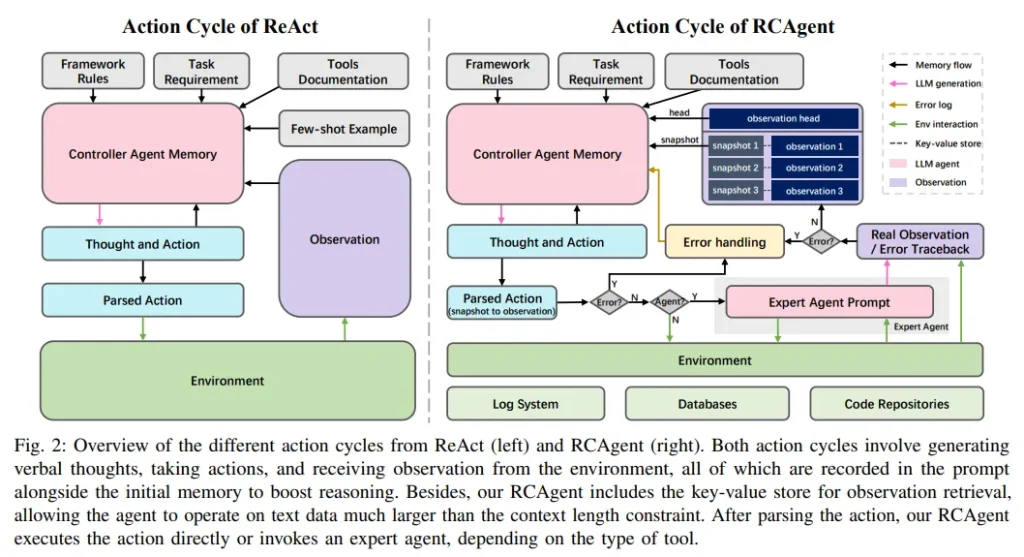
近期,云根本原因分析(RCA)领域对大型语言模型(LLM)的应用进行了积极探索。但现有方法仍依赖手动设置工作流,未能充分发挥LLM在决策和环境交互方面的能力。为此,研究团队推出了RCAgent,这是一个工具增强的LLM自治智能体框架,专为实用且注重隐私的工业RCA设计。
RCAgent不依赖外部模型如GPT系列,而是在内部部署的模型上运行,能够自主进行自由格式的数据收集和综合分析。该框架融合了多项增强功能,包括行动轨迹的自洽性,以及一系列用于上下文管理、稳定性提升和领域知识导入的方法。
实验结果表明,RCAgent在RCA的多个方面(如预测根本原因、解决方案、证据和责任)以及规则内外任务上均显示出显著且一致的优势,这些优势已通过自动化指标和人工评估得到验证。此外,RCAgent已成功集成至阿里云Apache Flink实时计算平台的诊断和问题发现工作流程中,进一步提升了工业RCA的效率和准确性。
AgileCoder: Dynamic Collaborative Agents for Software Development based on Agile Methodology
论文地址:https://arxiv.org/abs/2406.11912
软件智能体正成为解决复杂软件工程任务的有前景的工具。然而,现有研究常常过于简化软件开发流程,而现实世界中的这些流程往往更为复杂。
为了应对这一挑战,研究团队设计了AgileCoder,这是一个将敏捷方法论(AM)整合进框架的多智能体系统。该系统将特定的AM角色,如产品经理、开发人员和测试人员,分配给不同的智能体,它们根据用户输入协作开发软件。
AgileCoder通过组织工作为一系列冲刺(sprint),提高开发效率,并专注于逐步完成软件的开发。此外,还引入了一个动态代码图生成器,该模块能够在代码库更新时动态创建代码依赖图。这使得智能体能够更深入地理解代码库,从而在软件开发过程中实现更精确的代码生成和修改。
AgileCoder在性能上超越了现有的基准,如ChatDev和MetaGPT,树立了新的标准,并展现了多智能体系统在高级软件工程环境中的强大能力。这标志着软件开发向更自动化、智能化方向迈出了重要一步。
Parrot: Efficient Serving of LLM-based Applications with Semantic Variable
论文地址:https://arxiv.org/abs/2405.19888
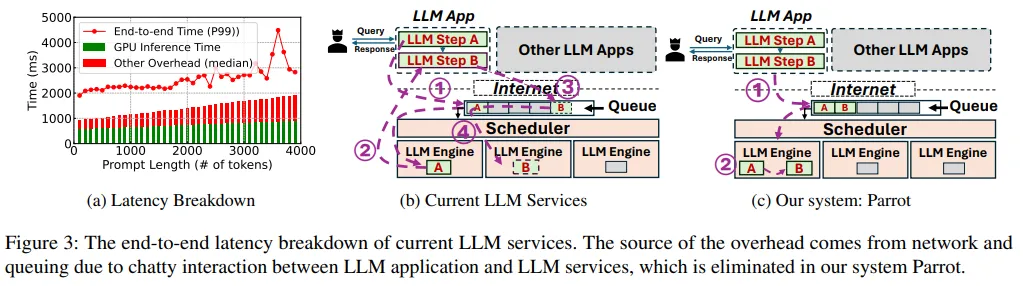
LLM的兴起催生了基于LLM与传统软件优势的新型应用程序——AI智能体(也叫副驾驶),这是一种软件新范式。
不同租户的LLM应用程序通过多个LLM请求设计复杂工作流以完成任务,但受限于当前公共LLM服务提供的简化请求级API,丢失了关键的应用程序级信息。这些服务只能盲目优化单个LLM请求,导致应用程序的整体性能不佳。
该论文介绍了Parrot,这是一个专注于LLM应用程序端到端体验的服务系统。Parrot引入了语义变量的概念,这是一种统一的抽象,将应用程序级知识暴露给公共LLM服务。语义变量在请求提示中标注输入/输出变量,并在连接多个LLM请求时形成数据管道,提供了一种自然的LLM应用程序编程方式。
公开语义变量给公共LLM服务,使其能够执行数据流分析,揭示多个LLM请求间的相关性,为LLM应用程序的整体性能优化开辟了新空间。广泛的评估显示,Parrot针对流行和实际的LLM应用程序用例实现了显著的性能提升。
Automating the Enterprise with Foundation Models
论文地址:https://arxiv.org/abs/2405.03710
项目地址:https://github.com/HazyResearch/eclair-agents
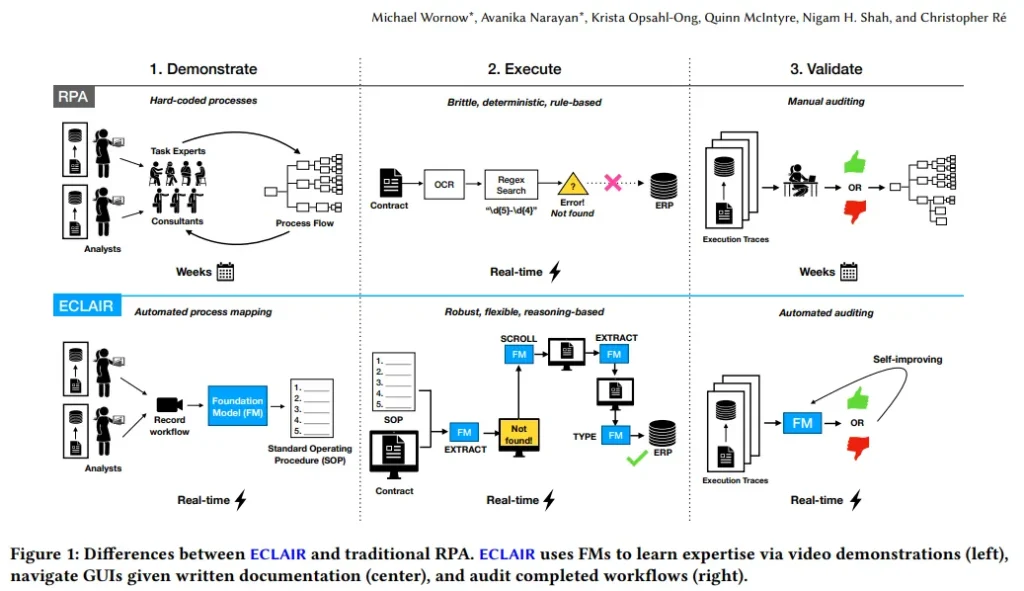
企业工作流程自动化每年可带来 4 万亿美元的生产力提升。尽管这一领域已受到数据管理社区数十年的关注,但实现端到端工作流自动化的终极目标仍然具有挑战性。现有解决方案主要依赖流程挖掘和机器人流程自动化(RPA),这些机器人通常被硬编码以遵循预设规则。
通过对医院和大型B2B企业的案例研究,研究团队发现RPA的普及受到诸如高设置成本(12-18个月)、执行不可靠(初始准确率60%)和维护繁重等问题的制约。新一代多模态基础模型(FM),如GPT-4,以其卓越的推理和规划能力,为工作流自动化提供了新的可能性。
为此,论文提出了ECLAIR系统,它在最少人工监督下实现企业工作流程自动化。初步实验显示,ECLAIR通过多模态FM实现了接近人类水平的工作流理解(准确率93%),并基于工作流的自然语言描述即可快速设置,实现了40%的端到端完成率。论文认为,人与AI的协作、验证和自我改进是未来研究的开放性挑战,并提出利用数据管理技术来解决这些问题。
S-Agents: Self-organizing Agents in Open-ended Environments
https://arxiv.org/abs/2402.04578
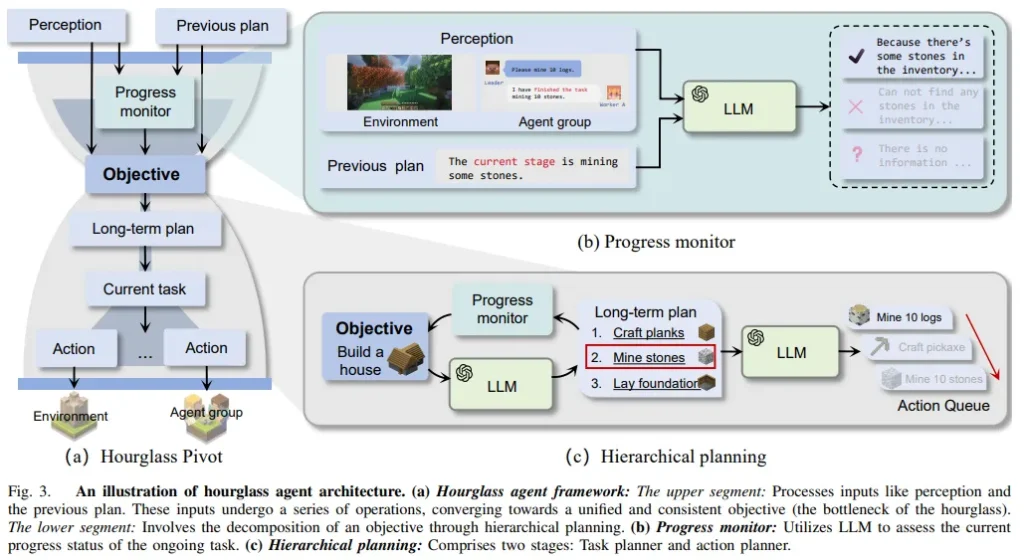
利用LLM,自主智能体在处理各类任务上取得了显著进步。在开放环境中,为了提升协作的效率和有效性,需要灵活调整策略。然而,现有研究多聚焦于固定且任务导向的工作流程,而忽视了以智能体为中心的组织结构。
受人类组织行为的启发,该团队提出了一种自组织智能体系统(S-Agents),它包括动态工作流的“智能体树”结构、用于平衡信息优先级的“沙漏智能体架构”,以及支持智能体间异步任务执行的“非阻碍协作”方法。这一结构使得一组智能体能在无人为干预下,有效应对开放和动态环境的挑战。
团队的实验在Minecraft环境中进行,S-Agent系统在执行协作建造和资源收集任务时表现出了熟练和高效,从而验证了其组织结构和协作方法的有效性。这一研究成果为智能体在复杂环境中的自组织协作提供了新的视角和解决方案。
A Human-Computer Collaborative Tool for Training a Single Large Language Model Agent into a Network through Few Examples
论文地址:https://arxiv.org/abs/2404.15974
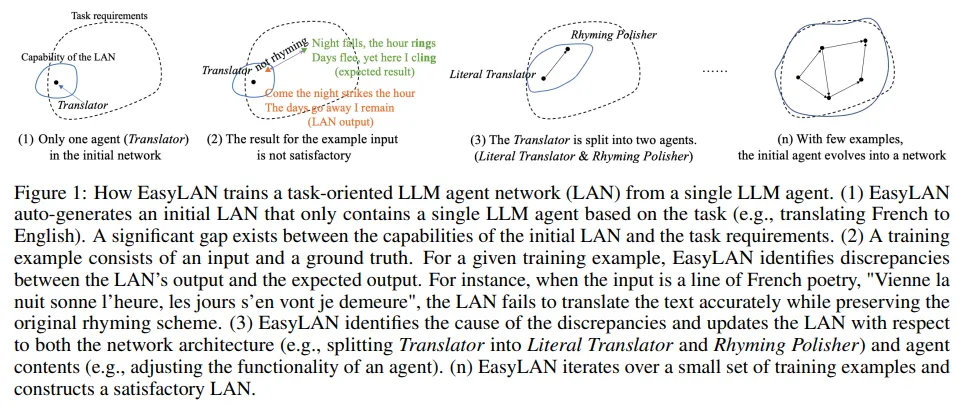
单个大型语言模型(LLM)智能体在解决复杂任务时能力有限。通过将多个LLM智能体连接成网络,可以显著提升整体性能。然而,构建这样的LLM智能体网络(LAN)是一项耗时且复杂的过程。
在本研究中,团队推出了EasyLAN,这是一个旨在帮助开发者构建智能体网络的人机协作工具。EasyLAN首先根据任务描述生成一个只包含单个智能体的网络。然后,它利用训练样本来逐步优化网络。EasyLAN会分析输出与实际值之间的差异,诊断错误原因,并采取策略进行修正。用户可以参与EasyLAN的工作流程,或直接对网络进行调整。
最终,网络从单一智能体发展成为一个成熟的LLM智能体网络。实验结果表明,使用EasyLAN,开发者能够迅速构建出性能优异的智能体网络。这一工具极大地简化了智能体网络的构建过程,提高了开发效率。
PromptRPA: Generating Robotic Process Automation on Smartphones from Textual Prompts
论文地址:https://arxiv.org/abs/2404.02475
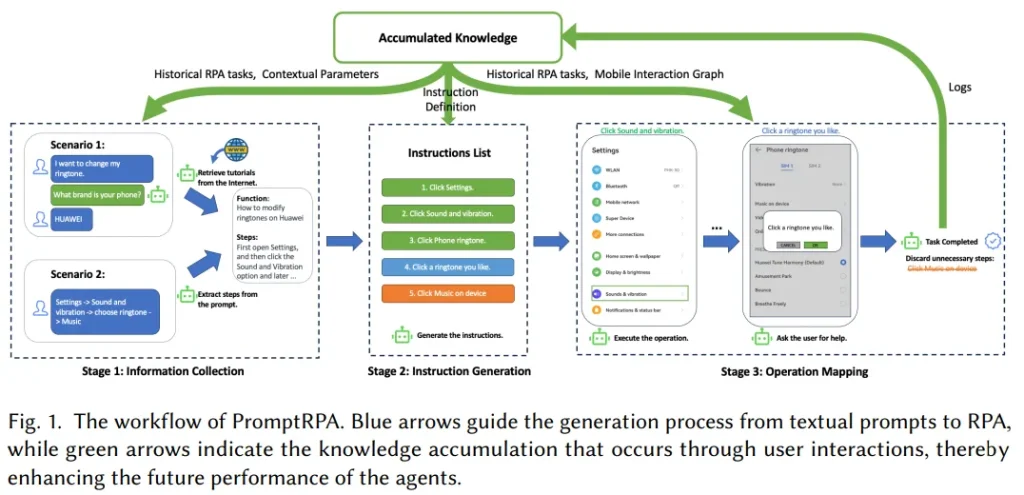
机器人流程自动化(RPA)通过模拟人机交互,在不修改现有代码的基础上,为自动化图形用户界面(GUI)上的任务提供了有效的解决方案。但RPA的广泛应用受限于对脚本语言和工作流设计专业知识的需求。
为解决这一问题,研究团队提出了PromptRPA,这是一个能够理解与任务相关的各种文本提示(如目标、程序)并生成及执行相应RPA任务的系统。
PromptRPA由一系列智能体组成,它们模仿人类的认知功能,专门用于解读用户意图、管理由RPA生成的外部信息,并在智能手机上执行操作。这些智能体能够从用户反馈中学习,并根据积累的知识不断提升性能。
实验结果显示,使用PromptRPA后,性能从基线的22.28%显著提升至95.21%,且每个新任务平均仅需1.66次用户干预。
PromptRPA在创建教程、智能辅助以及客户服务等领域展现出广阔的应用前景,为RPA技术的进一步普及和应用提供了新的可能性。
ProAgent: From Robotic Process Automation to Agentic Process Automation
论文地址:https://arxiv.org/abs/2311.10751
项目地址:https://github.com/OpenBMB/ProAgent
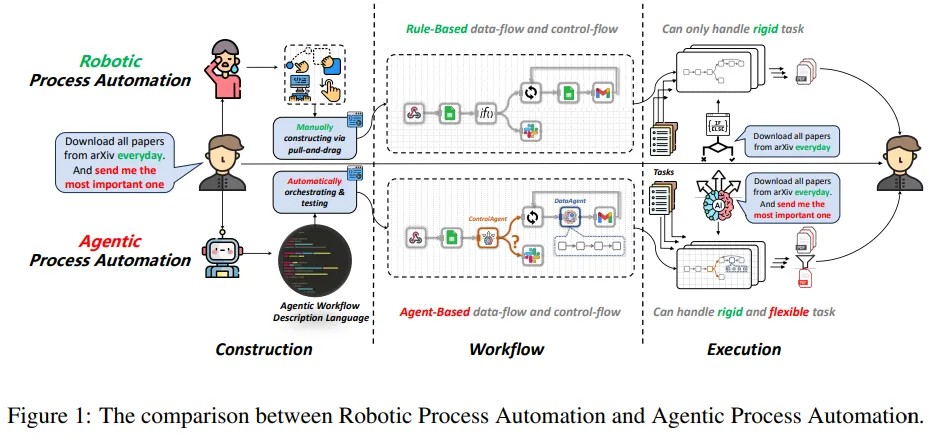
自动化技术从古代的水车发展到今天的RPA,一直在解放人类从事繁重任务。但RPA在处理需要人类智能的任务时面临挑战,尤其是在精心设计工作流和执行中的动态决策方面。
随着大型语言模型(LLM)的出现,研究团队提出了智能体流程自动化(APA),这是一种革命性的自动化新范式,利用基于LLM的智能体实现高级自动化,通过将任务分配给负责构建和执行的智能体来减轻人力负担。
论文具体实现了ProAgent,这是一个基于LLM的智能体,它可以根据人工指令创建工作流程,并通过协调专业的智能体做出复杂决策。
通过实证实验,论文详细展示了APA在工作流构建和执行方面的过程,证明了APA的可行性,并展现了由智能体驱动的自动化新范式的巨大潜力。这不仅为自动化领域带来了新的视角,也为未来智能自动化的发展提供了新的方向。
A Survey on LLM-Based Agents: Common Workflows and Reusable LLM-Profiled Components
论文地址:https://arxiv.org/abs/2406.05804
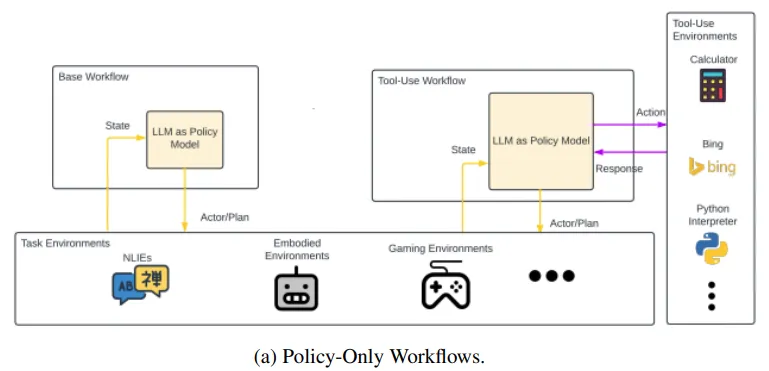
大型语言模型(LLM)的最新进展推动了基于LLM的复杂智能体框架的开发。然而,这些框架的复杂性在一定程度上阻碍了细粒度差异化的实现,这对于在不同框架间高效实现功能和推动未来研究至关重要。因此,该调查的主要目标是通过识别通用工作流程和可重用的LLM分析组件(LMPC),来促进对近期提出的多种框架的统一理解。
这项工作旨在简化不同智能体框架之间的差异,通过提取共通的工作流程和分析组件,为研究者和开发者提供一个更加清晰和一致的视角。通过这种方式,论文希望能够降低开发和维护智能体框架的难度,同时为未来的研究和创新打下坚实的基础。
WorkArena++: Towards Compositional Planning and Reasoning-based Common Knowledge Work Tasks
论文地址:https://arxiv.org/abs/2407.05291
基准测试项目:https://github.com/ServiceNow/WorkArena/tree/workarena-plus-plus

大型语言模型(LLM)因其模仿人类智能的能力而备受关注,这促使基于LLM的自主智能体数量激增。尽管最新的LLM展现出根据用户指令进行规划和推理的潜力,但它们在自主任务解决方面的实际应用效果尚待深入研究。特别是在企业环境中,自动化智能体的应用被寄予厚望,期望能够带来显著的影响。
为了解决这一研究空白,论文提出了WorkArena++,这是一个创新的基准测试套件,包含682个任务,覆盖知识工作者日常执行的实际工作流程。WorkArena++的目标是全面评估网络智能体在规划、问题解决、逻辑/算术推理、信息检索以及上下文理解等方面的能力。
通过对最先进的LLM、视觉语言模型(VLM)以及人类工作者的实证研究,论文揭示了这些模型在职场中作为有效助手所面临的若干挑战。
除了基准测试,论文还提供了一种机制,能够轻松生成数千条基于真实情境的观察/动作轨迹,这些轨迹可以用于微调现有的智能体模型,并期望这项工作能够成为推动社区向有能力的自主智能体发展的重要资源。
FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agent
论文地址:https://arxiv.org/abs/2406.14884
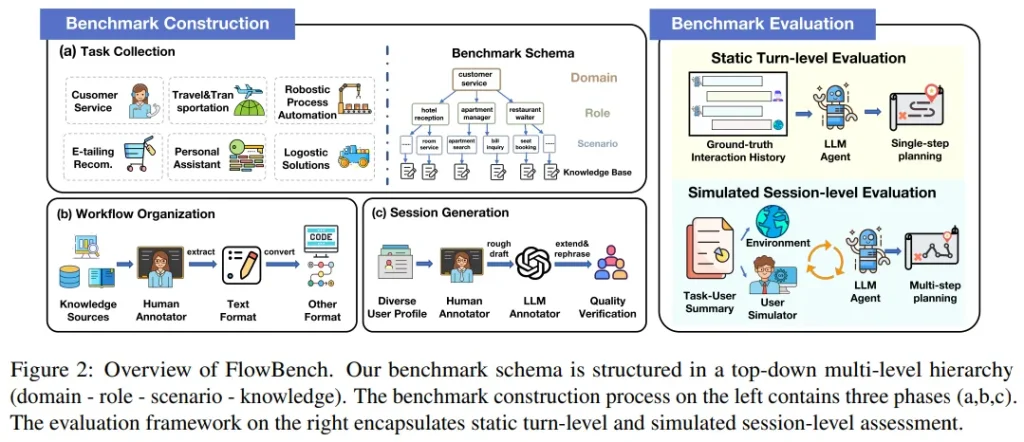
大型语言模型(LLM)驱动的智能体已成为执行复杂任务的有前途工具,它们通过迭代规划和行动来完成任务。但当缺乏对专业知识密集型任务的深入理解时,这些智能体可能会产生不切实际的规划幻想。为提高规划的可靠性,该团队尝试整合与工作流相关的外部知识。
尽管这一方法有潜力,但整合的知识往往杂乱无章、形式多样,缺乏严格的形式化和全面评估。因此,该团队对不同格式的工作流知识进行形式化处理,并推出了FlowBench——首个工作流引导规划的基准测试。FlowBench覆盖6个领域的51个不同场景,以多种形式展现知识。
为了在FlowBench上评估不同的LLM,团队设计了一个多层评估框架,评估了工作流知识在多种格式下的有效性。结果表明,现有的LLM智能体在规划方面还有很大的提升空间。论文期望FlowBench这一具有挑战性的基准测试能够为未来智能体规划研究提供参考,推动相关技术的进步。
Do Multimodal Foundation Models Understand Enterprise Workflows? A Benchmark for Business Process Management Tasks
论文地址:https://arxiv.org/abs/2406.13264
数据集和实验项目地址:https://github.com/HazyResearch/wonderbread
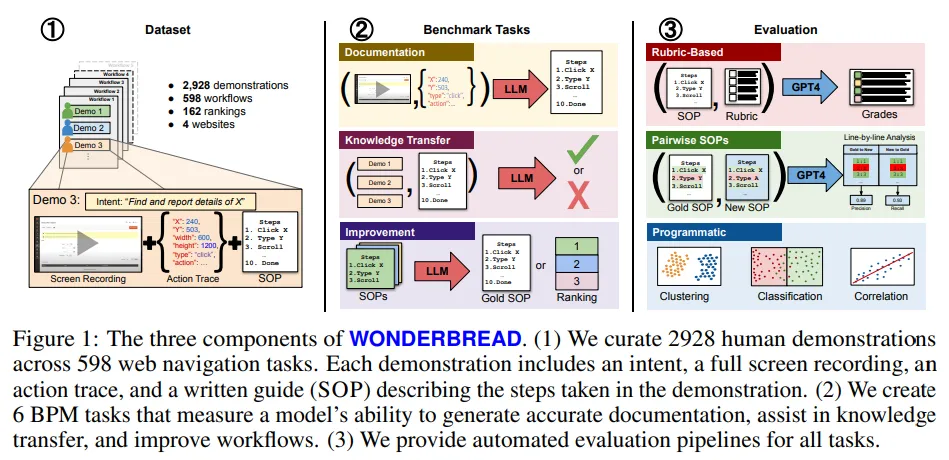
现有的机器学习(ML)基准测试在评估业务流程管理(BPM)任务时,缺乏足够的深度和多样性的注释。BPM 是一种旨在记录、衡量、改进和自动化企业工作流的实践。
目前的研究几乎完全集中在单一任务上,即利用多模态基础模型(FM)如 GPT-4 实现端到端的自动化。这种对自动化的专注忽视了大多数BPM工具的实际应用情况——在典型的流程优化项目中,仅仅记录相关工作流就占据了60%的时间。
为了填补这一空白,研究团队推出了WONDERBREAD,这是首个用于评估BPM任务的多模态FM基准测试,它超越了自动化的范畴。该论文的贡献包括:
团队期望WONDERBREAD能够激励开发更多以人为中心的AI工具,用于企业应用程序,并进一步探索多模态FM在更广泛的BPM任务中的应用。
APPL: A Prompt Programming Language for Harmonious Integration of Programs and Large Language Model Prompts
论文地址:https://arxiv.org/abs/2406.13161
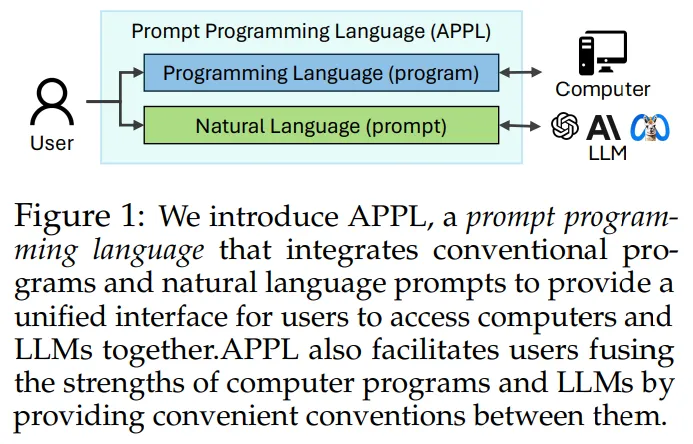
大型语言模型(LLM)通过精心设计的提示和外部工具的集成,日益展现出处理各类任务的能力。然而,随着任务复杂性的提升,涉及LLM的工作流程可能变得复杂,难以实现和维护。为解决这一难题,研究团队提出了APPL,一种新颖的提示编程语言,它作为计算机程序与LLM之间的桥梁,支持将提示无缝嵌入Python函数,反之亦然。
APPL具备直观的Python原生语法,拥有异步语义的高效并行化运行时环境,并且配备了无需额外成本的跟踪模块,以支持有效的故障诊断和重放。论文通过三个典型场景——自一致性的思维链(CoT-SC)、ReAct工具使用的智能体,以及多智能体聊天——证明了APPL程序的直观性、简洁性和高效性。
此外,对三个可并行化工作流的实验进一步证实了APPL在并行化独立LLM调用方面的有效性,并实现了与预期估算相匹配的显著加速比。这表明APPL是一个强大的工具,能够提升LLM在复杂任务中的性能和可用性。
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
论文地址:https://arxiv.org/abs/2405.04324
项目地址:https://github.com/ibm-granite/granite-code-models
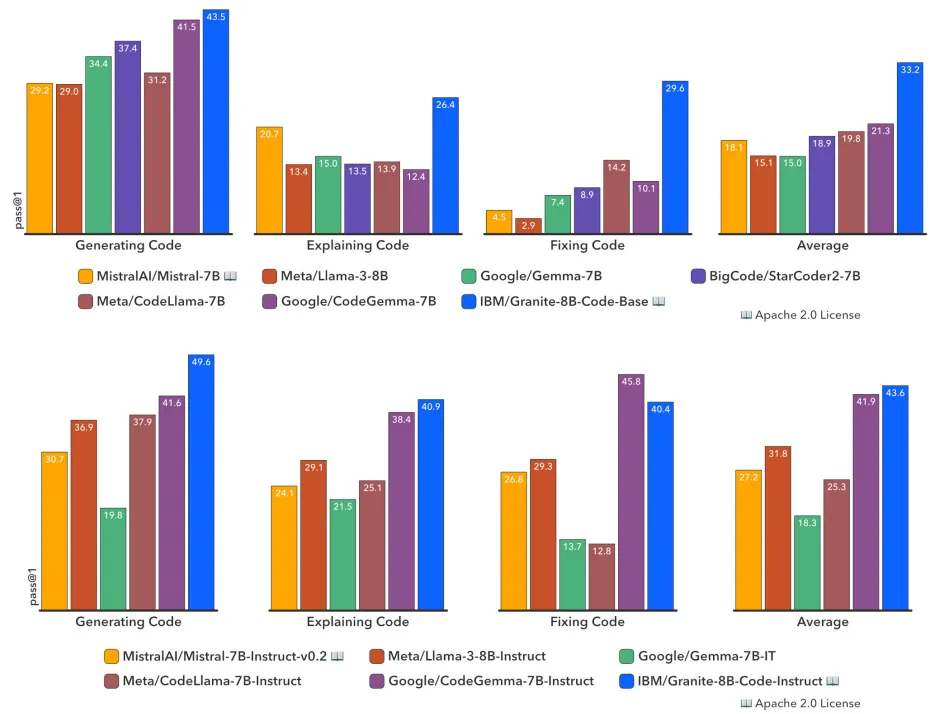
LLM在代码训练方面取得了突破性进展,正深刻改变着软件开发的生态。越来越多的代码LLM被融入到软件开发工具中,以提升程序员的工作效率。同时,基于LLM的智能体也开始展现出独立处理复杂编码任务的能力。
要充分发挥代码LLM的潜力,需要它们具备广泛的能力,如代码生成、错误修复、代码解释、文档编写和代码库维护等。在本项研究中,团队推出了Granite系列仅解码器代码模型,专门用于代码生成任务。这些模型经过了116种编程语言的代码训练,覆盖了从30亿到340亿参数大小不等的多种模型,能够满足从复杂的应用现代化到设备内存受限的各种场景。
通过一系列综合任务的评估,团队发现Granite Code模型在所有可用的开源代码LLM中始终保持最先进的性能。
该模型系列针对企业级软件开发流程进行了特别优化,在代码生成、修复和解释等多项编码任务中均有出色表现,成为一个多功能的全能型代码模型。所有Granite Code模型均在Apache 2.0许可下发布,既适用于研究也适用于商业用途,为软件开发领域带来了前所未有的灵活性和创新潜力。
Towards Hierarchical Multi-Agent Workflows for Zero-Shot Prompt Optimization
论文地址:https://arxiv.org/abs/2405.20252
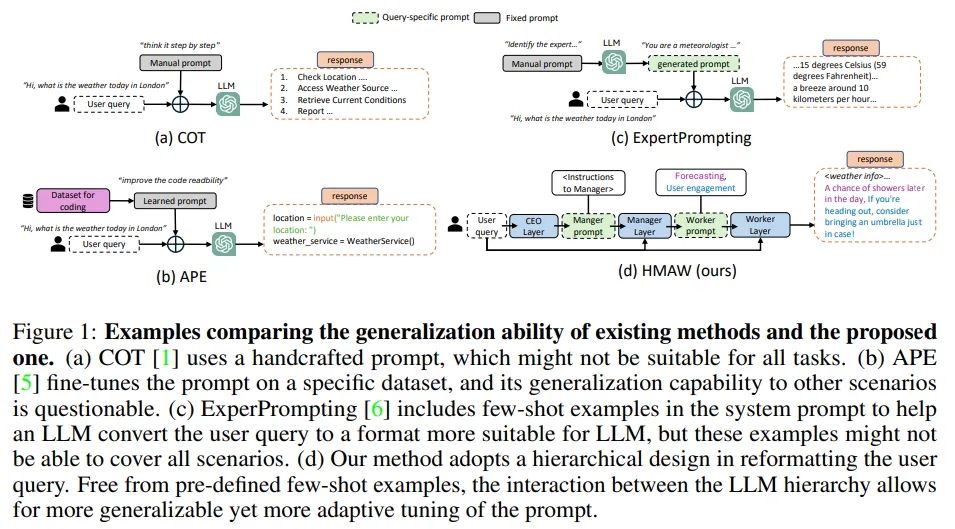
大型语言模型(LLM)在解答用户问题上取得了显著进步,支撑了多样化的应用场景。但LLM的回答质量极大程度上依赖于提示的质量,一个精心设计的提示能够引导LLM准确回答极具挑战性的问题。
尽管已有研究开发了多种策略来优化提示,包括手工制作和领域内优化,它们在开放场景下的有效性仍受限,因为前者依赖于人类对问题的理解,而后者对未见过场景的泛化能力不足。
为克服这些限制,研究团队提出了一种让LLM自主设计最佳提示的方法。具体来说,团队构建了一个分层的提示生成框架,首先创建包含精确指令和准确措辞的提示,再基于此生成最终答案。这一流程称为分层多智能体工作流(HMAW)。
与现有方法相比,HMAW不受任何人类预设限制,无需训练,完全任务独立,同时能够适应任务的细微差别。通过跨多个基准的实验,证实了HMAW虽然简单,却能创建出详尽且合适的提示,进一步提升了LLM的性能。
Autonomous Workflow for Multimodal Fine-Grained Training Assistants Towards Mixed Reality
论文地址:https://arxiv.org/abs/2405.13034
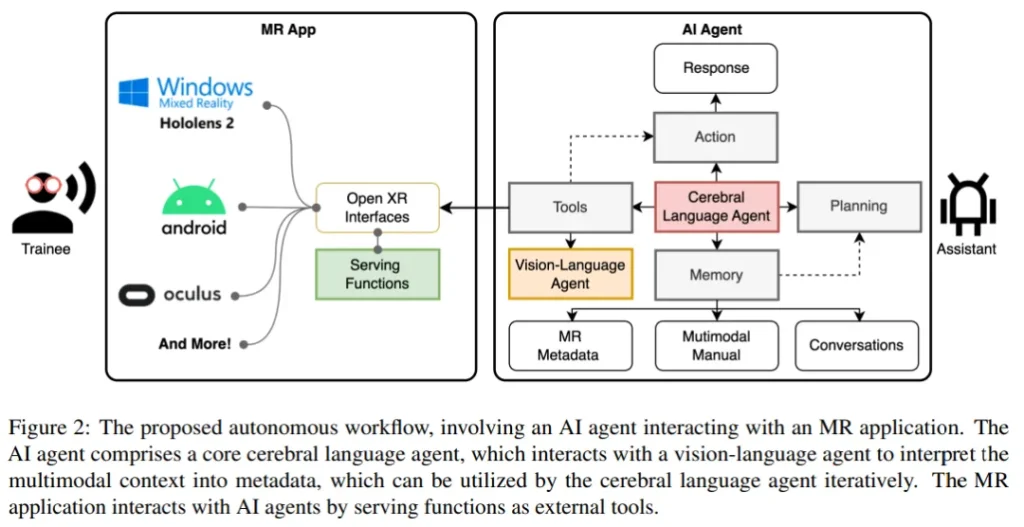
自主人工智能智能体(Autonomous Agent)在自动理解基于语言的环境中展现出巨大潜力,尤其是在大型语言模型(LLM)迅猛发展的背景下。然而,对多模态环境的深入理解尚待进一步探索。本研究设计了一个自主工作流程,旨在将AI智能体无障碍地集成到扩展现实(XR)应用中,实现细粒度训练。
论文展示了一个在XR环境中用于乐高积木组装的多模态细粒度培训助手的案例。该智能体结合了LLM、记忆、规划功能以及与XR工具的交互能力,能够根据历史经验做出决策。此外,论文介绍了LEGO-MRTA,这是一个多模态细粒度装配对话数据集,它能够在商业LLM服务的工作流程中自动合成,包含多模态说明、对话、XR响应和视觉问答。
研究团队选取了几个流行的开放资源LLM作为基准,评估它们在微调和未微调状态下对团队提出的数据集的性能。论文期望这一工作流程能够推动更智能助手的开发,实现XR环境中的无缝用户交互,并促进AI和人机交互(HCI)社区的研究。
Leveraging Multi-AI Agents for Cross-Domain Knowledge Discovery
论文地址:https://arxiv.org/abs/2404.08511
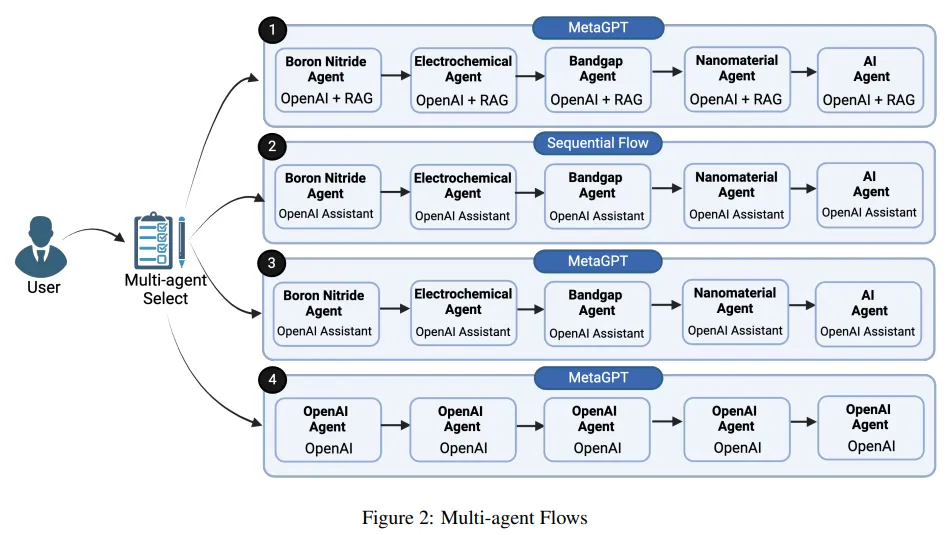
在迅速发展的人工智能领域,跨领域知识的整合与应用是一项关键的挑战与机遇。本研究提出了一种新方法,通过部署专注于不同知识领域的多人工智能智能体,实现跨学科的知识发现。每个智能体都像特定领域的专家,在统一框架下协同工作,提供综合的、超越单一领域限制的深入见解。
研究团队的平台通过促进智能体间的无缝互动,利用每个智能体的独特优势,增强了知识发现和决策过程。通过对比分析不同的多智能体工作流场景,评估了它们在效率、准确性和知识整合广度上的表现。实验结果表明,这些特定领域的多智能体系统在识别和填补知识空白方面表现出色。
这项研究不仅凸显了协作智能在促进创新中的关键作用,也为人工智能推动的跨学科研究和应用的发展奠定了基础。团队在小规模试点数据上评估了其方法,结果显示出预期趋势,随着自定义训练智能体的数据量增加,这些趋势预计将变得更加明显。
The Case for Developing a Foundation Model for Planning-like Tasks from Scratch
论文地址:https://arxiv.org/abs/2404.04540
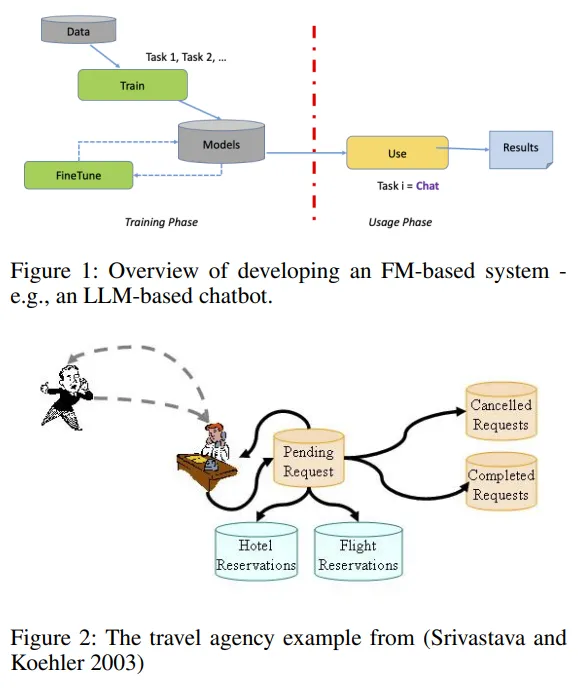
基础模型 (FM) 彻底改变了许多计算领域,包括自动规划和调度 (APS)。例如,最近的一项研究发现它们对规划问题很有用:计划生成、语言翻译、模型构建、多智能体规划、交互式规划、启发式优化、工具集成和大脑启发规划。
除了APS,还有许多任务涉及生成一系列行动,这些行动对于达成目标的可执行性有不同的保障,团队统称这些为类似计划(PL)任务,例如业务流程、程序编写、工作流管理和指南制定。研究人员正考虑将FM应用于这些领域。
然而,以往的研究多集中在使用现成的预训练FM,并可能对它们进行微调。该论文讨论了为PL任务从头开始设计全面的FM的必要性,并探讨了设计时需考虑的因素。论文认为,这样的FM将为PL问题提供新的有效解决方案,正如大型语言模型(LLM)为APS领域所做的那样。
Transformations in the Time of The Transformer
论文地址:https://arxiv.org/abs/2401.10897
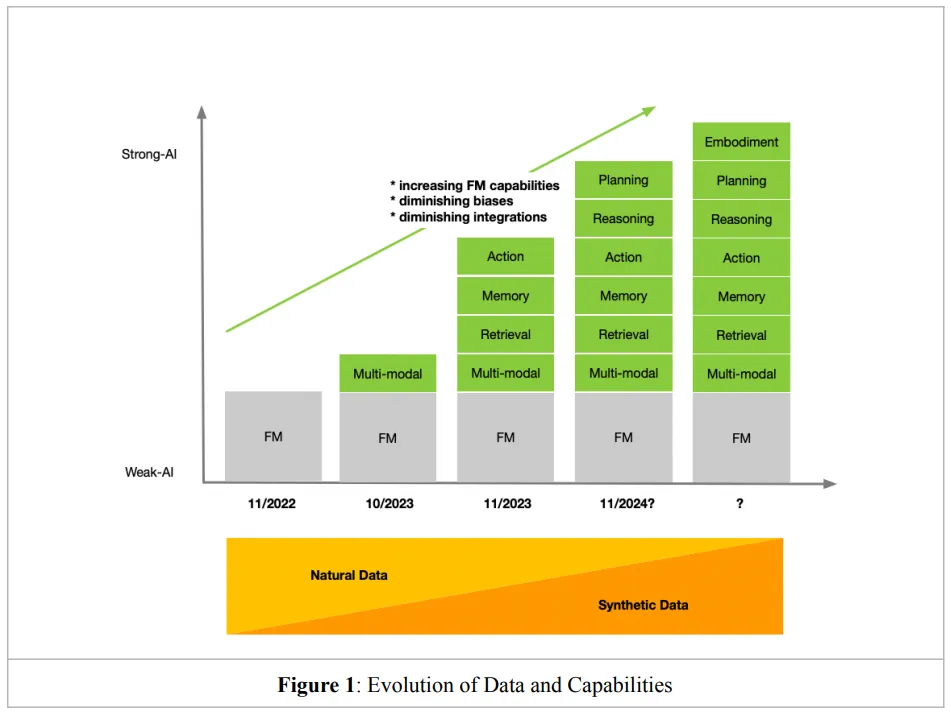
基础模型为以人工智能为主导的视角重新设计现有系统和工作流程提供了新的机遇。然而,实现这一转型面临着挑战和需要权衡的问题。本文旨在提供一个结构化的框架,帮助企业在向以AI为优先的组织转型过程中做出明智的决策。所提供的建议旨在帮助企业全面、有意识地做出知情的选择,同时避免受到不必要的干扰。
尽管这个领域看似发展迅猛,但其中一些核心的基础要素发展步伐相对较慢。团队专注于这些稳定不变的因素,以此构建论证的逻辑基础。通过深入理解这些不变的基本面,企业可以更稳健地把握AI转型的方向和步骤。
Synergizing Human-AI Agency: A Guide of 23 Heuristics for Service Co-Creation with LLM-Based Agents
论文地址:https://arxiv.org/abs/2310.15065
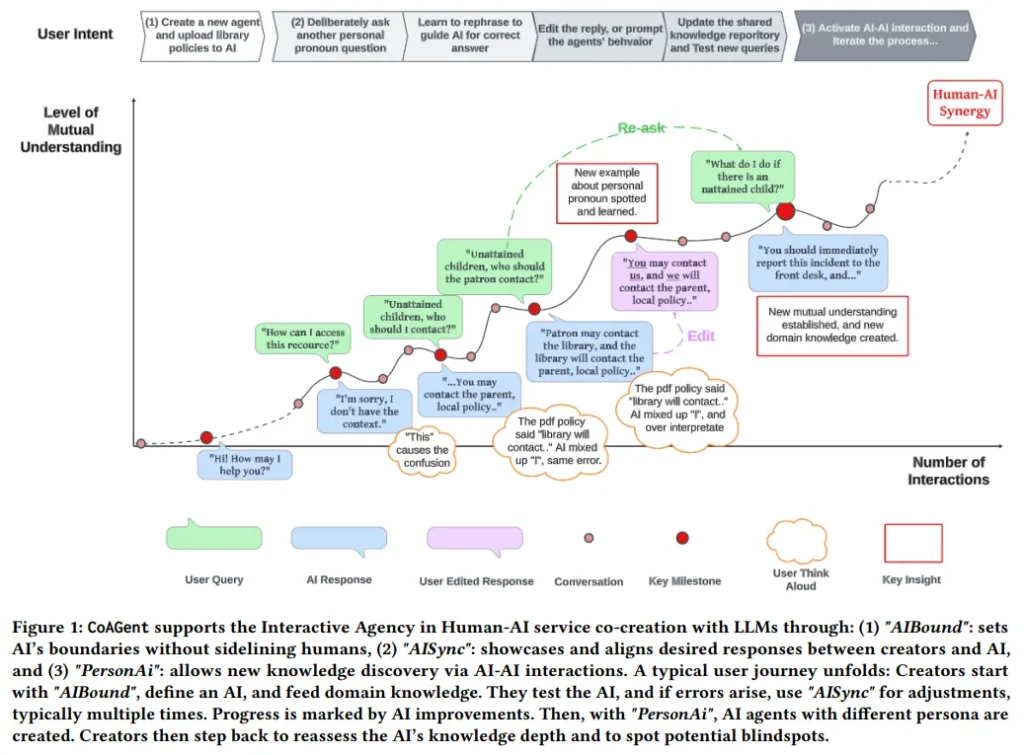
本项实证研究为服务供应商提供了入门知识,帮助他们确定是否以及如何将大型语言模型(LLM)技术集成到其从业者和更广泛社区的工作之中。通过CoAGent——一种与基于LLM的智能体共同创造服务的工具,研究团队探索了非AI专家与AI相互学习的过程。
这项研究通过与23位来自美国公共图书馆的领域专家合作,经历了一个三阶段的参与式设计流程,揭示了将AI集成到人类工作流程中所面临的根本性挑战。
研究结果提供了23种可操作的“与AI共同创造服务的启发式方法”,这些方法突出了人类与AI之间微妙的共同责任。并进一步提出了人工智能的9个基本智能体方面,强调了所有权、公平待遇和言论自由等基本要素。这种创新方法通过将AI视为关键利益相关者,并利用AI与AI的交互来识别盲点,从而丰富了参与式设计模型。
这些见解为服务环境中协同和道德的人类与AI共创铺平了道路,为人工智能共存的劳动力生态系统做好了准备。这不仅为服务供应商提供了实用的指导,也为构建人机协作的未来提供了宝贵的洞见。
The Foundations of Computational Management: A Systematic Approach to Task Automation for the Integration of Artificial Intelligence into Existing Workflows
论文地址:https://arxiv.org/abs/2402.05142
在AI迅猛发展的今天,组织面临一个核心问题:如何将AI技术有效融入现有运营?为解答这一问题、调控期望并减少挑战,该论文引入了计算管理——一种系统化的任务自动化方法,旨在增强组织利用AI的潜力。计算管理融合了管理科学的战略洞察与计算思维的分析精确性,架设了二者之间的桥梁。
论文提供三个分步流程,以助于在工作流中启动AI的集成。
首先是任务(重新)制定,它将工作活动拆解为基本单元,每个单元由智能体执行,包括明确行动并产生多样结果。
第二,评估任务自动化潜力,通过任务自动化指数对任务进行评估,依据其标准化输入、规则明确性、重复性、数据依赖性和客观输出进行排序。
第三,任务规范模板详述了16个关键组件,作为选择或调整AI解决方案以适应现有工作流程的清单。
这些流程结合了手动和自动方法,并为现有的大型语言模型(LLM)提供了使用提示,以辅助完成这些步骤。计算管理为人与AI的协同提供了路线图和工具,提升了组织效率和创新力,为人机共荣的未来铺平了道路。
注:本文论文叙述部分配图,皆来自论文截图,具体内容请参考论文详情。
本文转自 微信公众号@王吉伟










