全球API推荐:各语言最佳文本生成api介绍
文章目录
随着全球科技的不断发展,API(应用程序接口)在各行业中扮演着越来越重要的角色,尤其是在文本处理领域。2024年,各国的文本工具API服务正处于热门之中,为用户提供了各种强大的功能和服务。其中涉及到的文本工具类型API服务多种多样,如文本纠错、文本分析、URL转换、实体识别、PDF生成、个人资料生成等。
在当今数字化时代,文本处理API服务的发展势头迅猛,为用户提供了更加智能、高效的文本处理解决方案。通过不断创新和技术进步,各国的API服务商们正在不断推出新的文本工具API接口,为用户带来更多可能性和便利。在这些API服务的推动下,全球各国的文本处理能力得到了极大的提升,为用户带来了更加便捷和高效的文本处理体验。
文本工具API接口的作用?
文本工具API在当今社会中扮演着至关重要的角色。通过自动化的方式处理大量文本数据,可以提高工作效率。
文本工具型接口一般都提供哪些功能?
文本工具提供了非常多日常写作中可以用到的功能,包括关键词优化,中文字符转换,文本翻译,词法分析等功能。
文本纠错【聚合数据】
介绍
文本纠错API是一种专门针对中文文本的自动校对服务。它能够智能地检测文本中的错误,并给出相应的修改建议。这项技术对于提高文本质量、减少人为错误以及提升用户体验有着重要的作用。通过接入该API,应用程序可以实现自动化的文本校验和修正功能,使得最终输出的文本更加准确无误。
核心功能
- 文本纠错: 提供文本纠错服务,识别文本中存在的错误、拼写错误、语法错误等,并给出错误提示。
- 建议文本内容: 支持提供正确的建议文本内容,协助用户进行文本编辑和校对工作。
- 错误定位: 能够准确定位文本中的错误位置,并提供详细的纠错建议,以便用户理解和修改。
- 批量处理: 支持批量文本纠错,能够同时处理大量文本,提高工作效率。
- 自定义词库: 允许用户自定义词库,提升专业领域的纠错能力,满足特定行业需求。
文本分析API接口-JeTrun
介绍
文本分析API接口是一组预定义的方法和协议,用于与提供文本分析功能的软件组件或系统进行交互。这些API允许开发者通过编程方式,利用自然语言处理技术对文本进行各种分析操作。
核心功能
- 同义词/同义词库:
- 提供与给定词汇相关的同义词或短语,可能包含不同领域的同义词库,如医学、金融等。
- 文本分类:
- 将文本数据按照特定的类别或主题进行分类,可应用于新闻分类、社交媒体帖子分析等场景。
- 情感分析:
- 分析文本中的情感倾向,如正面、负面或中性,可用于分析用户评论、产品评价等。
- 关键词提取:
- 从文本中提取关键信息或关键词,这些关键词可用于内容摘要、主题建模等。
- 命名实体识别(NER):
- 识别文本中的特定类型实体,如人名、地名、组织名等,对信息抽取、关系抽取等任务至关重要。
- 语法和语义分析:
- 分析文本的语法结构和深层含义,有助于理解文本的复杂结构和内在含义。
- 文本相似度比较:
- 评估两个或多个文本之间的相似度或差异度,可用于文档去重、抄袭检测等场景。
URL转换LLM服务-Jina
介绍
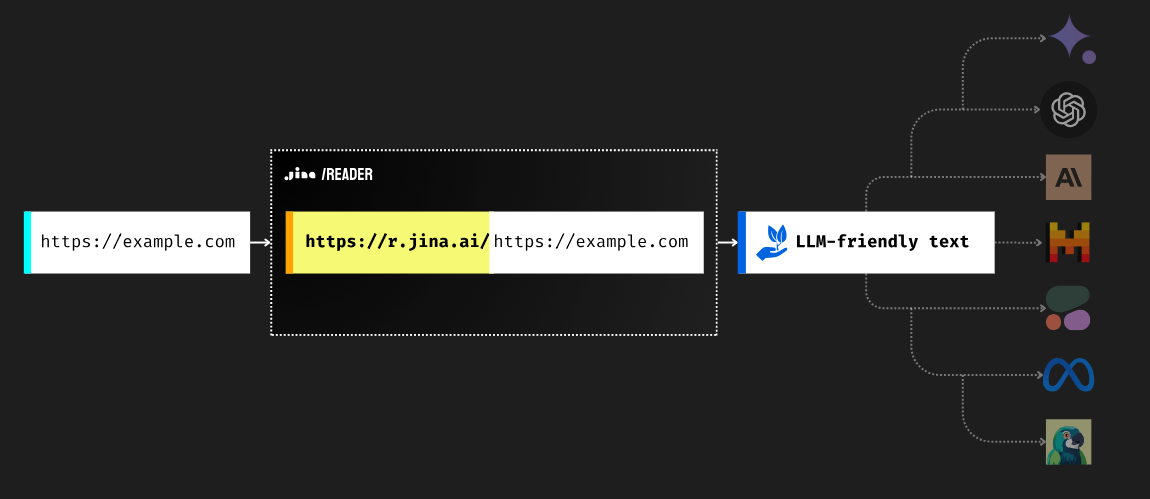
将网络信息输入LLM是打基础的重要一步,但它可能具有挑战性。最简单的方法是抓取网页并提供原始 HTML。然而,抓取可能很复杂并且经常被阻止,并且原始 HTML 中混杂着无关的元素,例如标记和脚本。 Reader API 通过从 URL 中提取核心内容并将其转换为干净、LLM 友好的文本来解决这些问题,从而确保代理和 RAG 系统的高质量输入。
核心功能
- 搜索基础阅读器
- LLM有知识限制,这意味着他们无法获取最新的世界知识,可能导致错误信息、过时的反应、幻觉等问题。接地对于 GenAI 应用至关重要。Reader 可以帮助您利用网络上的最新信息为您的法学硕士打下基础。只需在查询中添加
https://s.jina.ai/,Reader 将搜索网络并返回前5个结果及其URL和内容,每个结果都以干净、LLM友好的文本形式显示。这样,您可以始终保持您的LLM更新,提高其真实性并减少幻觉。
- LLM有知识限制,这意味着他们无法获取最新的世界知识,可能导致错误信息、过时的反应、幻觉等问题。接地对于 GenAI 应用至关重要。Reader 可以帮助您利用网络上的最新信息为您的法学硕士打下基础。只需在查询中添加
- 读者还可以阅读图像
- 使用阅读器中的视觉语言模型自动为网页上的图像添加标题,并在输出中格式化为图像alt标签。这为您的下游LLM提供了足够的提示,将这些图像合并到其推理和总结过程中。这意味着您可以提出有关图像的问题、选择特定图像,甚至将其URL转发到更强大的VLM进行更深入的分析!
- 阅读器还可以阅读PDF
- 是的,Reader 本身支持PDF阅读。它与大多数PDF兼容,包括那些包含许多图像的PDF,而且速度快如闪电!与LLM相结合,您可以立即轻松构建ChatPDF或文档分析人工智能。
文本分析API接口-雅虎
介绍
“文本分析API接口-雅虎”是由雅虎!JAPAN提供的一系列网络服务,旨在支持开发者创建能够分析日语文本的应用程序。这些API接口包括日语形态分析、假名汉字转换、红宝石编排(即注音假名添加)、校对支持、日语依存关系分析、关键词提取、自然语言理解、命名实体提取等功能。

核心功能
- 日语形态分析– 提供将日语句子划分为语素、添加词性、读法以及获取统计信息的功能。
- 假名-汉字转换– 将罗马字和平假名句子分成从句并提出转换候选。同时提供一种从短字符串猜测转换候选者的模式,采用与 VJE 相同的方法进行假名汉字转换。
- 注音假名– 在汉字和假名混合的句子中,添加平假名和罗马字的注音假名(拼音)。
- 校准支持– 支持对日语文本进行校对,检查印刷错误、用词不当、混乱的符号和不恰当的表达。
- 日本依存关系分析– 提供分析日语句子中依存关系的功能。
- 关键词提取– 分析日语句子并提取特征表达(关键短语)。
- 自然语言理解– 提供分析日语句子并提取信息的功能。
- 命名实体提取– 提供分析日语句子并提取命名实体(例如人名和组织名称)的功能。
法语实体识别
介绍
法语实体识别API服务是一种文本分析工具,它能够识别文本中的法语命名实体。这项服务适用于需要对法语文本进行深入分析的应用。
核心功能
- 识别法语文本中的命名实体。
- 提供实体识别的文本分析服务。
doqs PDF生成
介绍
只需一次 API 调用,您就可以从自己的 HTML 模板生成高质量的 PDF 文档,从而节省您的时间和精力。无论您需要创建发票、报告还是其他文档,请专注于您的产品,我们将负责文档生成。

核心功能
- 从HTML模板生成PDF:
- 用户可通过单次API调用,利用自定义的HTML模板生成高质量PDF文档。
- HTML模板可便捷定制,满足各种文档格式和内容需求。
- 高度自定义:
- 提供了多样API选项,允许用户自定义PDF文档的方向、格式(如纸张大小、页边距等)和其他视觉属性。
- 用户可根据具体需求轻松调整文档布局和样式。
- 基于云的API服务:
- 利用基于云的API,用户可轻松实现大规模PDF文档生成,无需担心基础设施的维护问题。
- 这种基于云的解决方案提高了灵活性和可扩展性,支持按需生成PDF文档。
- 易于集成:
- 提供了简单直接的API接口,方便用户集成到自己的系统中。
- 支持无代码解决方案,如Zapier、Make.com或Bubble等,降低了集成难度和成本。
- 安全委托上传:
- 提供了安全委托上传功能,用户可将文档安全上传给提供商,无需共享敏感凭证。
- 这种上传方式确保了数据的安全性和隐私性,同时提升了用户体验。
MySafeInfo随机个人资料生成器
介绍
该端点提供了一种灵活动态的方式来生成随机个人资料,非常适合需要高质量模拟数据的开发人员和测试人员。该端点因其支持多种数据格式而脱颖而出,包括 JSON、XML、CSV 等,确保与不同系统和技术的无缝集成。此外,用户可以利用各种自定义选项来根据自己的特定需求定制输出,例如设置配置文件的数量、按特定标准进行过滤以及调整返回数据的详细程度。有关所有支持的格式和自定义可能性的详细概述,请参阅我们的综合文档。
核心功能
- 生成随机个人资料:生成包括姓名、年龄、性别、出生日期等基本个人信息。
- 多种数据类型支持:提供职业信息、财务信息、身份信息等多种数据类型,例如工作职位、银行账户、社会安全号码等。
- 自定义数据生成:允许用户根据需求自定义生成的数据字段和格式,以满足特定应用场景的需求。
- 批量数据生成:支持一次性生成大量随机个人资料,便于进行大规模测试或数据填充,提高工作效率。
百度AI文章标签
介绍
百度AI文章标签API服务是一种智能的文本分析工具,旨在自动从文章内容中提取关键词和生成标签,以帮助用户快速了解文章的主题和内容。这项服务采用先进的自然语言处理技术和深度学习模型,能够深入分析文章的文本结构和语义信息,从而准确地识别出文章的核心关键词和相关标签。
核心功能
- 关键词提取:自动识别并提取文章中的核心关键词,快速揭示文章的主要内容和焦点。
- 标签生成:基于文章内容生成相关标签,便于内容分类和检索。
- 深度语义理解:利用深度学习技术理解文章的深层语义,确保关键词和标签的准确性和相关性。
- 广泛适用性:适用于各种类型的文本内容,包括新闻、博客、研究报告、产品描述等。
- 实时高效处理:支持快速处理大量文本,满足企业级应用的需求。
应用场景
内容管理系统
自动为文章生成标签,提高内容组织和检索效率。
搜索引擎优化(SEO)
利用关键词和标签优化文章,提高搜索引擎的可见度和排名。
内容推荐系统
基于文章标签匹配用户兴趣,提供个性化的内容推荐。
市场分析
分析相关文章和报告的关键词,洞察市场趋势和热点话题。
核心功能
- 文章标签的核心功能包括:自动标签生成、关键词提取、分类标签、实体标签等。
- 自动标签生成:利用人工智能技术自动识别文章内容,为文章添加相关标签,提高文章的搜索引擎优化效果。
- 关键词提取:提取文章中的关键词,帮助用户快速了解文章内容,也可用于文章的检索和分类。
- 分类标签:根据文章内容自动分析并添加相应的分类标签,帮助用户更快速地找到感兴趣的文章。
- 实体标签:识别文章中的实体信息,如人名、地名、组织机构等,为文章内容提供更加详细的标签信息,方便用户理解和搜索。
- 提高用户体验:通过为文章添加标签,提高用户对文章的浏览体验,使用户更容易找到自己感兴趣的内容,提高用户留存和转化率。
总结
- 文本纠错【聚合数据】: 该API提供了中文文本的自动校对服务,包括文本纠错、建议文本内容、错误定位、批量处理和自定义词库等功能,帮助提高文本质量和用户体验。
- 文本分析API接口-JeTrun: 这个API接口提供了文本分析的多种功能,包括同义词库、文本分类、情感分析、关键词提取、命名实体识别、语法和语义分析以及文本相似度比较等功能,可应用于各种自然语言处理任务。
- URL转换LLM服务-Jina: Jina提供了URL转换服务,可以从URL中提取核心内容并转换为干净、LLM友好的文本,为代理和RAG系统提供高质量的输入。
- 文本分析API接口-雅虎: 该API接口由雅虎!JAPAN提供,支持日语文本的形态分析、假名汉字转换、注音假名添加、校对支持、依存关系分析、关键词提取、自然语言理解和命名实体提取等功能。
- 法语实体识别: 这个API服务能够识别法语文本中的命名实体,适用于需要深入分析法语文本的场景。
- doqs PDF生成: 通过该API可以从自定义HTML模板生成高质量的PDF文档,支持自定义和批量处理,帮助节省时间和精力。
- MySafeInfo随机个人资料生成器: 这个API提供了生成随机个人资料的功能,支持多种数据类型和自定义生成,适用于开发人员和测试人员需要模拟数据的场景。
- 百度AI文章标签: 这个API服务可以自动从文章内容中提取关键词和生成标签,帮助用户快速了解文章主题和内容,适用于内容管理系统、搜索引擎优化、内容推荐系统和市场分析等场景。
如何通过幂简集成发现API
幂简集成是国内领先的API集成管理平台,专注于为开发者提供全面、高效、易用的API集成解决方案。幂简API平台提供了多种维度发现API的功能:通过关键词搜索API、从API Hub分类浏览API、从开放平台分类浏览企业间接寻找API等。
此外,幂简集成博客会编写API入门指南、多语言API对接指南、API测评等维度的文章,让开发者选择符合自己需求的API。