
 |
Adobe PDF 提取服务
专用API
【更新时间: 2024.08.13】
Adobe PDF 提取 API使用由 Adobe Sensei 机器学习提供支持的 Web 服务解锁任何 PDF 的结构和内容元素。
|
浏览次数
134
采购人数
2
试用次数
1
 SLA: N/A
响应: N/A
适用于个人&企业
SLA: N/A
响应: N/A
适用于个人&企业
试用
收藏
×
完成
取消
×
书签名称
确定
|

- API详情
- 定价
- 使用指南
- 常见 FAQ
- 关于我们
- 相关推荐


什么是Adobe PDF 提取服务?
"Adobe PDF 提取服务"是一种基于 Adobe Sensei 机器学习技术的 Web 服务,旨在解锁 PDF 文档的结构和内容元素。该服务通过 Adobe PDF Extract API 提供,允许用户从任何 PDF 文件中提取结构化数据,包括文本、表格、图像等,并将这些数据以 JSON、CSV、XLSX 或 PNG 等格式输出。这使得用户能够轻松地在各种下游系统中存储、分析和操作这些数据。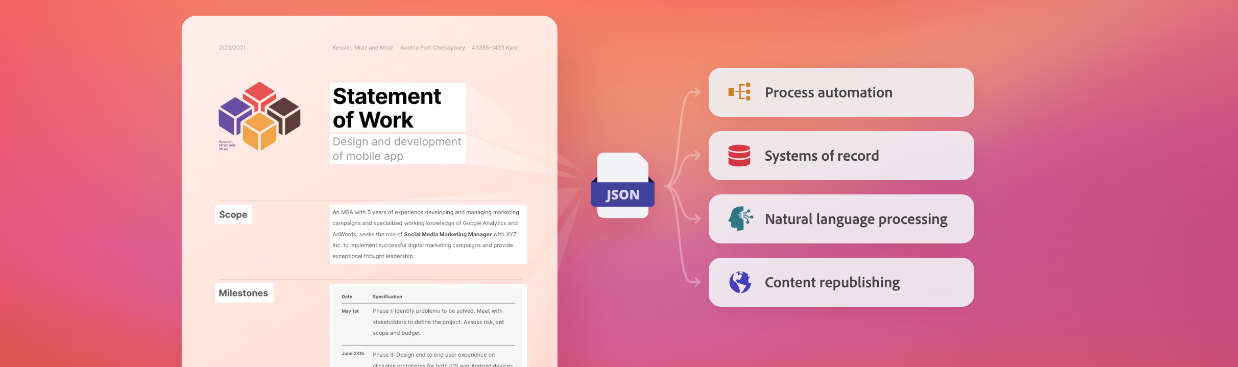
Adobe PDF 提取服务有哪些核心功能?
 |
 |
 |
 |
|
全面的内容提取
|
文档结构理解 对可能跨多列或多页的文本对象(如标题、列表、脚注和段落)进行分类。捕获所有对象的文本字体和样式、定位和自然阅读顺序。 |
高度准确的结果 Adobe Sensei AI 技术可在多种文档类型(原生 PDF 和扫描 PDF)中提供高度准确的数据提取,而无需自定义 ML 模板或模型训练。 |
平台无关
|
Adobe PDF 提取服务的核心优势是什么?
-
全面的内容提取:Adobe PDF 提取服务能够提取 PDF 文档中的所有元素,包括文本、表格和图像,并以结构化的 JSON 文件形式输出。这种全面的内容提取能力支持各种下游解决方案,如数据分析、内容重新发布等。
-
文档结构理解:借助 Adobe Sensei AI 技术,该服务能够深入理解文档结构,包括元素的识别、位置、相对于其他元素的连接以及自然阅读顺序。这使得提取的数据更加准确和有用。
-
高度准确的结果:Adobe Sensei AI 技术在多种文档类型(原生 PDF 和扫描 PDF)中提供高度准确的数据提取,而无需用户自定义 ML 模板或进行模型训练。这大大降低了使用门槛,提高了工作效率。
-
平台无关:Adobe PDF Extract API 是 RESTful 风格的,可以与任何云平台或内部部署应用程序无缝集成。这种灵活性使得该服务能够广泛应用于各种场景和环境中。
-
安全性:Adobe 非常重视用户数据的安全性,提供了全面的安全概述和保障措施,确保用户在使用该服务时数据的安全性和隐私性。
-
易用性:用户可以从免费套餐开始,每月获得一定数量的免费文档交易。此外,Adobe 还提供了可立即运行的示例代码和交互式演示,帮助用户快速上手并体验 API 的强大功能。
在哪些场景会用到Adobe PDF 提取服务?
 |
 |
 |
| 内容处理 快速准确地从原生和扫描的 PDF 中提取数据和上下文,以使用机器人流程自动化 (RPA) 和自然语言处理 (NLP) 等技术实现下游流程的自动化。 |
数据分析
|
内容重新发布 通过提取数据、结构上下文、文本和表格格式以及阅读顺序,以不同的媒体、语言和格式重新发布 PDF 文档中的内容。 |
步骤 1:获取访问令牌
PDF 服务 API 端点是经过身份验证的端点。获取访问令牌分为两个步骤:
- 获取凭据 调用 PDF 服务 API 需要 Adobe 提供的凭据。要获取凭据,请单击此处并完成工作流程。请务必将凭据值复制并保存到安全位置。
- 检索访问令牌PDF 服务 API 需要 access_token 来授权请求。使用 Postman Collection 中的“获取 AccessToken”API 以及您的 client_id、client_secret(在 1 中下载的 pdfservices-api-credentials.json 文件中提到)来获取 access_token,或者直接使用下面提到的 cURL 来获取 access_token。
步骤 2:上传资产
获取访问令牌后,我们需要上传资产。上传资产分为两个步骤:
- 首先您需要使用以下 API 获取上传预签名 URI。
- 从上述 API获取响应状态后,使用
uploadUri上述 API 响应主体中的字段,通过 PUT API 调用将资产直接上传到云提供商。您还将获得一个assetID用于创建作业的字段。
步骤 3:创建作业
要为操作创建作业,请 assetID在 API 请求正文中使用步骤 2 中获得的。成功提交作业后,您将获得状态代码和将用于轮询的响应标头。
要创建作业,请参阅特定PDF 操作的相应 API 规范。
步骤 4:获取状态
成功创建作业后,您需要location使用以下 API 轮询步骤 3 中返回的响应标头
步骤 5:下载资产
从轮询 API获取响应代码后,您将status在响应正文中收到一个字段,该字段可以是in progress、done或failed。
如果status字段为in progress,则需要继续轮询位置,直到它变为done或failed。
如果该status字段是done响应主体,则该字段中还会有一个下载预签名 URI dowloadUri,它将用于通过以下 API 调用直接从云提供商下载资产
指南详情链接:https://developer.adobe.com/document-services/docs/overview/pdf-accessibility-auto-tag-api/gettingstarted/
目标是我们的核心
了解我们如何努力为世界创造积极的变化。
|
面向所有人的 Adobe
|
|
|
|
人人享有创造力 作为一家创意公司,我们独特地致力于为全世界的创作者赋能。 |
技术变革 我们致力于推动负责任地使用技术,造福社会。 |
|
 |
我们的价值观 我们的公司价值观——创造未来、拥有结果、提高标准和真诚——代表了我们是谁、我们如何在世界上出现,以及我们将如何定义我们未来的成功。 |



Adobe 和 AI
Adobe 正在利用人工智能作为副驾驶,使世界更具创造力、生产力和个性化,从而放大人类的聪明才智。
步骤 1:获取访问令牌
PDF 服务 API 端点是经过身份验证的端点。获取访问令牌分为两个步骤:
- 获取凭据 调用 PDF 服务 API 需要 Adobe 提供的凭据。要获取凭据,请单击此处并完成工作流程。请务必将凭据值复制并保存到安全位置。
- 检索访问令牌PDF 服务 API 需要 access_token 来授权请求。使用 Postman Collection 中的“获取 AccessToken”API 以及您的 client_id、client_secret(在 1 中下载的 pdfservices-api-credentials.json 文件中提到)来获取 access_token,或者直接使用下面提到的 cURL 来获取 access_token。
步骤 2:上传资产
获取访问令牌后,我们需要上传资产。上传资产分为两个步骤:
- 首先您需要使用以下 API 获取上传预签名 URI。
- 从上述 API获取响应状态后,使用
uploadUri上述 API 响应主体中的字段,通过 PUT API 调用将资产直接上传到云提供商。您还将获得一个assetID用于创建作业的字段。
步骤 3:创建作业
要为操作创建作业,请 assetID在 API 请求正文中使用步骤 2 中获得的。成功提交作业后,您将获得状态代码和将用于轮询的响应标头。
要创建作业,请参阅特定PDF 操作的相应 API 规范。
步骤 4:获取状态
成功创建作业后,您需要location使用以下 API 轮询步骤 3 中返回的响应标头
步骤 5:下载资产
从轮询 API获取响应代码后,您将status在响应正文中收到一个字段,该字段可以是in progress、done或failed。
如果status字段为in progress,则需要继续轮询位置,直到它变为done或failed。
如果该status字段是done响应主体,则该字段中还会有一个下载预签名 URI dowloadUri,它将用于通过以下 API 调用直接从云提供商下载资产
指南详情链接:https://developer.adobe.com/document-services/docs/overview/pdf-accessibility-auto-tag-api/gettingstarted/
目标是我们的核心
了解我们如何努力为世界创造积极的变化。
|
面向所有人的 Adobe
|
|
|
|
人人享有创造力 作为一家创意公司,我们独特地致力于为全世界的创作者赋能。 |
技术变革 我们致力于推动负责任地使用技术,造福社会。 |
|
|
我们的价值观 我们的公司价值观——创造未来、拥有结果、提高标准和真诚——代表了我们是谁、我们如何在世界上出现,以及我们将如何定义我们未来的成功。 |
Adobe 和 AI
Adobe 正在利用人工智能作为副驾驶,使世界更具创造力、生产力和个性化,从而放大人类的聪明才智。

