
 |
网站在线爬虫服务-grabz
专用API
【更新时间: 2024.08.08】
GrabzIt提供的在线爬虫服务简化了网页数据抓取。用户可自定义目标网站和数据类型,设置存储与传输方式,实现数据的自动化提取与分析。
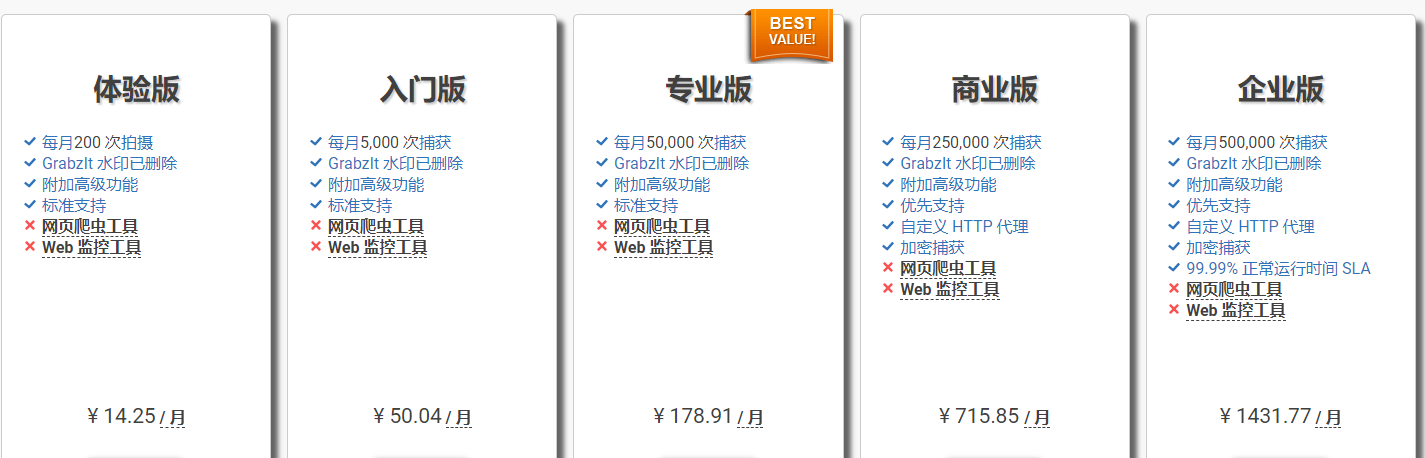
¥ 14.25 / 月
去服务商官网采购>
|
浏览次数
71
采购人数
5
试用次数
0
 SLA: N/A
响应: N/A
适用于个人&企业
SLA: N/A
响应: N/A
适用于个人&企业
收藏
×
完成
取消
×
书签名称
确定
|


- API详情
- 定价
- 使用指南
- 常见 FAQ
- 关于我们
- 相关推荐


什么是grabz的网站在线爬虫服务?
grabz网站在线爬虫服务指的是GrabzIt提供的在线网页抓取服务,它简化了从互联网上任何网站抓取数据的过程。通过该服务,用户可以定义目标网站、指定要抓取的数据类型以及数据的存储和传输方式,从而实现自动化的数据提取和分析。
grabz的网站在线爬虫服务有哪些核心功能?
-
网页转图像:使用我们的API将网页转换为图像。
-
HTML转DOCX: 利用我们的API实现HTML和网页到DOCX格式的转换。
-
TML表格转CSV: 我们的API支持将HTML表格转换成CSV、JSON或Excel格式。
-
URL转呈现HTML:获取执行所有资源后网页的实际HTML。
-
URL转PDF或HTML转PDF: 使用我们的API将网页或HTML转换成PDF格式,便于离线浏览。
-
视频转GIF:利用我们的API将YouTube、Vimeo等在线视频转换为GIF动画。
-
网页转图标: 通过我们的API,根据网页元数据为任何URL生成图像图标。
-
HTML转视频:使用我们的API将HTML或URL转换为加载完成的网页视频。
grabz的网站在线爬虫服务的核心优势是什么?
- 易用性:设计简单,用户无需编程技能即可使用,大大降低了使用门槛。
- 高效性:支持多浏览器实例和代理服务器,加快抓取速度,避免被目标网站阻塞。
- 灵活性:提供丰富的选项和配置,满足不同用户的个性化需求。
- 准确性:能够处理复杂的网页结构和动态内容,确保抓取数据的准确性和完整性。
- 可扩展性:支持大规模数据抓取,满足企业级应用的需求。
在哪些场景会用到grabz的网站在线爬虫服务?
1. 数据收集与分析
- 市场调研:企业可以利用GrabzIt API接口从多个网站收集竞争对手的产品信息、价格策略、市场活动等数据,用于市场趋势分析、竞争对手分析以及市场策略制定。
- 行业报告:分析师和顾问公司可以使用该API接口从多个来源抓取数据,整合成行业报告,为客户提供深入的市场洞察。

2. 内容聚合与展示
- 内容聚合平台:如新闻聚合网站、电商平台的价格比较工具等,可以使用GrabzIt API接口从多个网站抓取内容,并在自己的平台上进行展示,为用户提供更全面的信息和服务。
- 垂直领域应用:在特定行业或垂直领域,如房地产、汽车等,应用可以抓取相关网站的数据,为用户提供更精准的信息检索和比较功能。

3. SEO与网站监控
- SEO优化:SEO从业者可以利用GrabzIt API接口监控网站在搜索引擎中的排名和表现,评估SEO策略的效果,并根据数据反馈调整优化策略。
- 网站健康检查:网站管理员可以使用该API接口定期检查网站的关键页面和内容是否正常运行,及时发现并处理潜在的问题。

4. 自动化测试与监控
- 软件测试:在软件开发和测试阶段,开发团队可以使用GrabzIt API接口自动化地抓取网页,以测试网站的功能和性能是否符合预期。
- 网站监控:运维团队可以使用该API接口对网站进行实时监控,确保网站在高并发、高负载等情况下仍能稳定运行。

1. 确定目标网站
定义要从哪些网站、文件或网站部分抓取数据。然后安排执行此操作的时间。
2. 指定数据指定要抓取的数据
定义要抓取网页或文件的哪些部分。接下来,定义如何存储这些数据。
3. 封装数据打包抓取的数据
指定存储数据的文件格式。最后指定您希望如何将抓取数据传输给您。
指南详情链接:https://grabz.it/scraper/
创始人
我们的创始人Dominic Skinner(理学学士、理学硕士)是一位经验丰富的网络开发人员,他创办 GrabzIt 的目的是让网络完全机器可读。我们仍在努力实现这一目标。他利用自己多年的软件工程经验,努力让 GrabzIt 的所有服务尽可能地对其他网络开发人员和非网络开发人员有用。
基础设施
GrabzIt 网络
左侧是我们的 Web 服务架构的简化图。虽然实际上涉及的服务器更多,但在适用时,这些服务器会为对我们的 Web 服务发出的请求提供缓存响应。所有这些都是为了使我们的系统具有大规模可扩展性,并允许我们在需要时轻松扩展我们的能力。
由于我们的系统满足全球众多客户的需求,因此它在设计上尽可能可靠,并在系统架构的所有层中内置了多个冗余系统。
结合所有这些因素,您应该可以自信地选择 GrabzIt 来解决您的数据捕获需求。
1. 确定目标网站
定义要从哪些网站、文件或网站部分抓取数据。然后安排执行此操作的时间。
2. 指定数据指定要抓取的数据
定义要抓取网页或文件的哪些部分。接下来,定义如何存储这些数据。
3. 封装数据打包抓取的数据
指定存储数据的文件格式。最后指定您希望如何将抓取数据传输给您。
指南详情链接:https://grabz.it/scraper/
创始人
我们的创始人Dominic Skinner(理学学士、理学硕士)是一位经验丰富的网络开发人员,他创办 GrabzIt 的目的是让网络完全机器可读。我们仍在努力实现这一目标。他利用自己多年的软件工程经验,努力让 GrabzIt 的所有服务尽可能地对其他网络开发人员和非网络开发人员有用。
基础设施
GrabzIt 网络
左侧是我们的 Web 服务架构的简化图。虽然实际上涉及的服务器更多,但在适用时,这些服务器会为对我们的 Web 服务发出的请求提供缓存响应。所有这些都是为了使我们的系统具有大规模可扩展性,并允许我们在需要时轻松扩展我们的能力。
由于我们的系统满足全球众多客户的需求,因此它在设计上尽可能可靠,并在系统架构的所有层中内置了多个冗余系统。
结合所有这些因素,您应该可以自信地选择 GrabzIt 来解决您的数据捕获需求。

