
 |
Dataflow 网站数据提取
专用API
【更新时间: 2024.08.15】
DFK的API使您能够以编程方式管理和运行web数据提取和SERP收集任务。之后您可以轻松检索提取的数据。
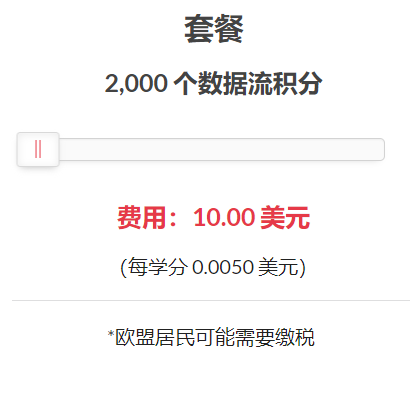
10$ / 2,000 个数据流积分
去服务商官网采购>
|
浏览次数
30
采购人数
1
试用次数
1
 SLA: N/A
响应: N/A
适用于个人&企业
SLA: N/A
响应: N/A
适用于个人&企业
试用
收藏
×
完成
取消
×
书签名称
确定
|


- API详情
- 定价
- 使用指南
- 常见 FAQ
- 关于我们
- 相关推荐


什么是Dataflow 网站数据提取?
我们帮助人们自动化网络抓取任务,从任意规模的多个页面中提取、处理和转换数据。通过点击式网页抓取界面,单击即可提取文本、图像、属性。我们代表您访问网页,在云中使用无头 Chrome 渲染 Javascript 驱动的页面,返回静态 HTML,并捕获屏幕截图或另存为 PDF。

Dataflow 网站数据提取有哪些核心功能?
|
无头 Chrome 即服务。 在云端渲染 Javascript 驱动的网页,返回静态 HTML。 |
指向并单击网络抓取工具。 Dataflow Kit 将为您猜测类似的数据元素。无需编码。
|
抓取 SERP 数据。 使用我们的 SERP API 从流行的搜索引擎中提取有机结果、广告、新闻、图像。 |



|
网页到 PDF 转换器。 向 PDF API 发送包含网页地址和参数的请求,将网页转换为 PDF。 |
在线制作网页截图。 直接在您的应用程序中在线捕获网页屏幕截图。 |
|


Dataflow 网站数据提取的核心优势是什么?
|
全球代理网络。 IP轮换。 有时网站会限制其他国家/地区的用户访问。 我们提供数据流套件代理服务,以绕过特定网站的内容下载限制或通过代理发送请求以获取目标网站的特定国家/地区版本。 只需从 100 多个支持的全球位置中指定目标国家/地区即可发送您的网络/SERP 抓取 API 请求。或者选择“任意国家/地区”以使用随机地理目标。
|
Headless Chrome 即服务。 如今最流行的方法是使用 Headless Chrome 浏览器,它以与真实浏览器相同的方式呈现网站。 此外,Chrome 还配备了将 HTML 保存为 PDF 以及从网页生成屏幕截图的工具。 我们提供将动态 JavaScript 驱动的网页渲染为云端静态 HTML 的服务。 |
行动。手动工作流程的自动化。 操作对于模拟现实世界中的人类与页面的交互非常有用。它们由抓取工具在访问网页时执行,帮助您更接近所需的数据。
|
|
数据流套件 API。 只需发送一个 API 请求,指定所需的网页和一些参数。
|
输出数据格式。 JSON、JSON Lines、Excel、CSV、XML。
|
云中的数据。
|






在哪些场景会用到Dataflow 网站数据提取?
电商网站的价格监控与比价企业可以利用Dataflow API从多个电商平台上提取产品价格、描述、评论等数据。这些数据可以用于实时监控竞争对手的价格变化,从而调整自己的定价策略。比价网站也可以通过这个API提取大量电商数据,汇总并展示给用户,帮助他们找到最低价的产品。 |
|
新闻聚合与舆情监控新闻机构或数据分析公司可以使用Dataflow API从各种新闻网站、博客和社交媒体平台上提取新闻文章、评论和其他相关数据。这些数据可以用于新闻聚合服务,提供最新的新闻资讯,或用于舆情监控,了解公众对某一事件或品牌的态度。 |
|
市场调研与趋势分析市场调研公司或营销团队可使用该API接口自动抓取社交媒体、新闻网站或行业博客上的数据。这些数据可用于分析当前的市场趋势、消费者的偏好或行业的最新动态。通过自动化的数据提取,团队可以更快速地获取关键信息,以制定准确的市场策略和预测。 |
|



Web/SERP 数据提取。
数据流套件 (DFK) 计算每个成功 (2xx) 请求的页面信用。因此,扣除的积分数量取决于您发送的请求数量。
| 没有代理 | 使用代理 | ||
|---|---|---|---|
| 1个常规页面请求成功 | 1 学分 | 2学分 | 使用基本 HTTP 请求“按原样”获取常规页面 |
| 1 javascript页面请求成功 | 2学分 | 3学分 | 真正的网络浏览器(无头浏览器)用于呈现动态 Javascript 驱动的网页。 |
| 1 个 SERP 页面成功请求 | - | 3学分 | Headless chrome 和代理始终用于搜索引擎数据请求。 |
笔记:
- 导致 DFK 错误响应的请求不会计费或计为积分。
- 如果使用 DFK 代理,则会扣除额外积分。
1.验证
Dataflow Kit API 要求您注册 API 密钥才能使用该 API。
免费注册后,可以在 DFK Dashboard 中找到 API 密钥。
将秘密 API 密钥作为 api_key 查询参数传递给服务器的所有 API 请求。
2.下载网页内容
使用 fetch 端点下载网页
- 基本获取器类型是获取服务器端呈现页面的正确选择。与使用 Chrome fetcher 渲染 HTML 相比,它需要更少的资源并且工作速度更快
- 但为了渲染 Angular、React 和 Vue.js 网站,您应该始终指定 Chrome fetcher 类型。在这种情况下,无头 Chrome 获取器以与真实 Web 浏览器相同的方式呈现动态 Javascript 内容。
在 https://dataflowkit.com/render-web 上为您最喜欢的语言生成可立即运行的代码
3.从搜索引擎收集搜索结果
要抓取搜索引擎结果页面,您可以使用 /serp 端点。 SERP 收集服务提取有机结果、新闻、图像等的列表。指定配置参数(例如国家/地区或语言)以自定义输出 SERP 数据。支持以下搜索引擎
- 谷歌
- 谷歌图片
- 谷歌新闻
- 谷歌购物
在 https://dataflowkit.com/serp 为您最喜欢的语言生成可立即运行的代码
详情参考:https://dataflowkit.com/doc-api#tag/serp/operation/serp
Web/SERP 数据提取。
数据流套件 (DFK) 计算每个成功 (2xx) 请求的页面信用。因此,扣除的积分数量取决于您发送的请求数量。
| 没有代理 | 使用代理 | ||
|---|---|---|---|
| 1个常规页面请求成功 | 1 学分 | 2学分 | 使用基本 HTTP 请求“按原样”获取常规页面 |
| 1 javascript页面请求成功 | 2学分 | 3学分 | 真正的网络浏览器(无头浏览器)用于呈现动态 Javascript 驱动的网页。 |
| 1 个 SERP 页面成功请求 | - | 3学分 | Headless chrome 和代理始终用于搜索引擎数据请求。 |
笔记:
- 导致 DFK 错误响应的请求不会计费或计为积分。
- 如果使用 DFK 代理,则会扣除额外积分。
1.验证
Dataflow Kit API 要求您注册 API 密钥才能使用该 API。
免费注册后,可以在 DFK Dashboard 中找到 API 密钥。
将秘密 API 密钥作为 api_key 查询参数传递给服务器的所有 API 请求。
2.下载网页内容
使用 fetch 端点下载网页
- 基本获取器类型是获取服务器端呈现页面的正确选择。与使用 Chrome fetcher 渲染 HTML 相比,它需要更少的资源并且工作速度更快
- 但为了渲染 Angular、React 和 Vue.js 网站,您应该始终指定 Chrome fetcher 类型。在这种情况下,无头 Chrome 获取器以与真实 Web 浏览器相同的方式呈现动态 Javascript 内容。
在 https://dataflowkit.com/render-web 上为您最喜欢的语言生成可立即运行的代码
3.从搜索引擎收集搜索结果
要抓取搜索引擎结果页面,您可以使用 /serp 端点。 SERP 收集服务提取有机结果、新闻、图像等的列表。指定配置参数(例如国家/地区或语言)以自定义输出 SERP 数据。支持以下搜索引擎
- 谷歌
- 谷歌图片
- 谷歌新闻
- 谷歌购物
在 https://dataflowkit.com/serp 为您最喜欢的语言生成可立即运行的代码
详情参考:https://dataflowkit.com/doc-api#tag/serp/operation/serp

