
 |
Crawlbase 网页内容提取
专用API
【更新时间: 2024.08.01】
Crawlbase 提供了一种强大的爬虫 API,旨在保护网络爬虫免受请求阻塞、代理故障和验证码等问题的影响。该服务支持无带宽限制的网页数据抓取,具有99%的成功率,并能够处理常规和动态生成的网页。
免费
去服务商官网采购>
|
浏览次数
190
采购人数
4
试用次数
0
 SLA: N/A
响应: N/A
适用于个人&企业
SLA: N/A
响应: N/A
适用于个人&企业
试用
收藏
×
完成
取消
×
书签名称
确定
|

- API详情
- 定价
- 使用指南
- 常见 FAQ
- 关于我们
- 相关推荐


什么是Crawlbase 网页内容提取?
Crawlbase 网页内容提取是一个功能强大的API服务,它允许用户通过简化的方式获取网页的HTML源代码。这个API服务特别注重隐私保护和数据安全,确保用户的爬取行为不被网站所有者追踪。Crawlbase 覆盖了全球范围内的众多网站,支持各种类型的数据提取需求,从简单的文本信息到复杂的网页结构数据均可应对。

Crawlbase 网页内容提取有哪些核心功能?
1.高性能网页爬取:在大规模的数据收集项目中,如价格监控、市场分析或竞品分析等,Crawlbase能够高速访问和下载网页内容,显著减少数据收集所需时间。
2.API集成:开发者可以将Crawlbase的API集成到自定义应用程序中,实现自动化的数据抓取和处理流程。使得外部应用能够直接利用Crawlbase的强大爬取功能,进一步扩展应用的功能和效率。
3.实时数据抓取:对于需要实时监控数据变化的场景(如股票价格监控、新闻更新等),Crawlbase能提供实时的数据抓取服务。确保用户能够获取最新的信息,做出及时的决策或调整策略。
Crawlbase 网页内容提取的核心优势是什么?
借助我们为打开互联网数据自由之门而创建的工具,您可以在几分钟内开始抓取和抓取网站。
 |
 |
 |
|
1.节省 60% 的人力 通过改用我们的无代理抓取解决方案,8 家公 司中有 10 家节省了超过 60% 的人力。从而 为企业带来了更高的运营效益和竞争力。
|
2.摆脱排队系统 将他们的队列移动到我们的 Crawler 云基础 设施的公司,完全摆脱了他们的队列系统 , 避免了不必要的瓶颈。
|
3.24 / 7客户支持 开发人员为开发人员构建的易于使用的爬虫 API。 绕过块和验证码并在不维护基础架构 的情况下抓取任何网站。
|
 |
 |
 |
|
4.节省多达 200 小时 使用我们的内置刮刀,每月可为您的团队节省 200 多个工作小时。 |
5.节省高达$ 8500 平均而言,我们的客户每月在代理上节省超过 8500 美元,这是您已经在代理上花费的资金 的 50%。 |
6.规避风险 在美国,每年 1 家公司中有 20 家因访问公 共数据而被起诉。 使用我们完全匿名避免风险。 |
在哪些场景会用到Crawlbase 网页内容提取?
|
1.定期收集 YouTube 数据 在数字营销和内容分析领域,持续监控和分析 YouTube 上的数据对 于业务成功至关重要 。Crawlbase 为 UpscaleMethod 提供了强大 的支持 ,确保其能够不间断地满足对评论和分析数据的需求,从而优 化内容策略并提升用户参与度。 |
 |
 |
2.扫描网站以测试问题 在网站性能和用户体验日益重要的今天,能够及时发现并解决网站问 题是提升用户满意度的关键 。Crawlbase 帮助 PageWatch 有效地 测试那些难以抓取的网站,确保了网站的稳定性和可靠性,进而增强 了用户对 PageWatch 服务结果的信心。 |
|
3.大规模抓取产品数据并快速发展您的业务 在电子商务和市场分析领域,快速获取大量的产品数据是企业扩大市 场份额和提升运营效率的关键 。Crawlbase 极大地简化了数据收集 过程,使企业能够轻松地获取所需的各种数据。 |
 |
4.抓取博客文章以创建摘要
在内容聚合和信息提炼方面,能够快速获取并处理大量文本数据是提供高质量服务的基础。Crawlbase 为内容平台提供了一种高效的方式来抓取博客文章并创建准确的摘要,这对于为用户提供相关且及时的内容至关重要。

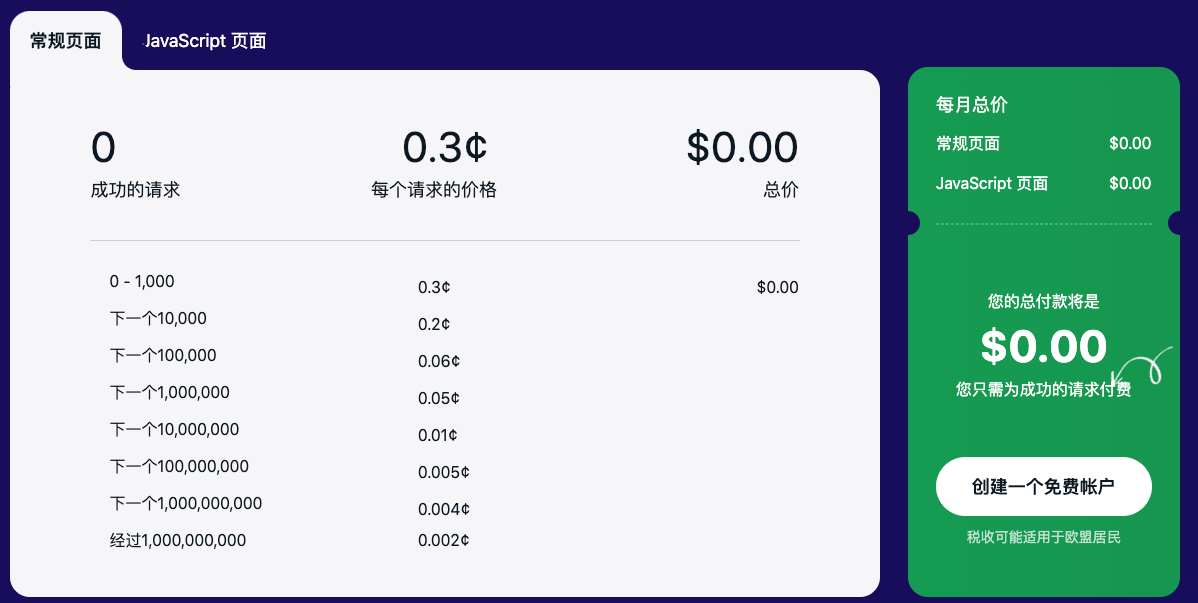

数分钟内的抓取 API
我们创建了一个 API,它可以让 Crawlbase 非常容易地集成到您的爬虫项目中。
#您的第一个 API 调用
所有 API URL 都以以下基本部分开头: https://api.crawlbase.com
因此,拨打您的第一个电话就像在终端中运行以下行一样简单。
继续尝试!
curl 'https://api.crawlbase.com/?token=USER_TOKEN&url=https%3A%2F%2Fgithub.com%2Fcrawlbase%3Ftab%3Drepositories'有时使用普通令牌是不够的,因为该站点仅在启用 JavaScript 浏览器时才能工作,或者因为您需要的内容是通过客户端的 JavaScript 呈现的,因此您需要使用 JavaScript 令牌。
来试试 JS 爬取吧!
curl 'https://api.crawlbase.com/?token=USER_TOKEN&url=https%3A%2F%2Fgithub.com%2Fcrawlbase%3Ftab%3Drepositories'#免费试用
前 1,000 个请求是免费的。
确保充分使用免费试用版!
#速率限制
API 的速率限制为最大值 每秒 20 个请求, 每个令牌(可根据要求增加速率限制)。
这意味着您可以发送 每秒最多 20 个请求,这意味着每月大约 51 万个请求,无论他们使用多少线程。
API 将响应 429 超过速率限制时的状态码。
请注意: 某些特定网站可能有较低的限制。 如果您需要更高的限制,请 联系支持 (打开新窗口) .
#API 响应时间
API 的平均响应时间在 4 到 10 秒之间,但 我们推荐 为至少 90 秒的调用设置超时。
#成功与失败
我们只对成功的请求收费(请参阅 原始状态 和 电脑状态 在下面的响应参数中)。
#其他说明
- 如果您更喜欢使用库来集成 Crawlbase,您可以查看可用的 API库在这里 (打开新窗口) .
- 建议使用 Accept-Encoding gzip 标头。
- 如果您使用 Scrapy for python,请确保 禁用 DNS 缓存 (打开新窗口) .
#
#

数分钟内的抓取 API
我们创建了一个 API,它可以让 Crawlbase 非常容易地集成到您的爬虫项目中。
#您的第一个 API 调用
所有 API URL 都以以下基本部分开头: https://api.crawlbase.com
因此,拨打您的第一个电话就像在终端中运行以下行一样简单。
继续尝试!
curl 'https://api.crawlbase.com/?token=USER_TOKEN&url=https%3A%2F%2Fgithub.com%2Fcrawlbase%3Ftab%3Drepositories'有时使用普通令牌是不够的,因为该站点仅在启用 JavaScript 浏览器时才能工作,或者因为您需要的内容是通过客户端的 JavaScript 呈现的,因此您需要使用 JavaScript 令牌。
来试试 JS 爬取吧!
curl 'https://api.crawlbase.com/?token=USER_TOKEN&url=https%3A%2F%2Fgithub.com%2Fcrawlbase%3Ftab%3Drepositories'#免费试用
前 1,000 个请求是免费的。
确保充分使用免费试用版!
#速率限制
API 的速率限制为最大值 每秒 20 个请求, 每个令牌(可根据要求增加速率限制)。
这意味着您可以发送 每秒最多 20 个请求,这意味着每月大约 51 万个请求,无论他们使用多少线程。
API 将响应 429 超过速率限制时的状态码。
请注意: 某些特定网站可能有较低的限制。 如果您需要更高的限制,请 联系支持 (打开新窗口) .
#API 响应时间
API 的平均响应时间在 4 到 10 秒之间,但 我们推荐 为至少 90 秒的调用设置超时。
#成功与失败
我们只对成功的请求收费(请参阅 原始状态 和 电脑状态 在下面的响应参数中)。
#其他说明
- 如果您更喜欢使用库来集成 Crawlbase,您可以查看可用的 API库在这里 (打开新窗口) .
- 建议使用 Accept-Encoding gzip 标头。
- 如果您使用 Scrapy for python,请确保 禁用 DNS 缓存 (打开新窗口) .
#
#

