
 |
网页内容提取-Scraperbox
专用API
【更新时间: 2024.07.24】
ScraperBox 是一个专业的网页数据抓取工具,它为用户提供了一种简单而高效的方式来从各种网站中提取数据。这个服务特别适合需要自动化数据收集和处理的用户,无论是进行市场研究、内容聚合还是数据分析。
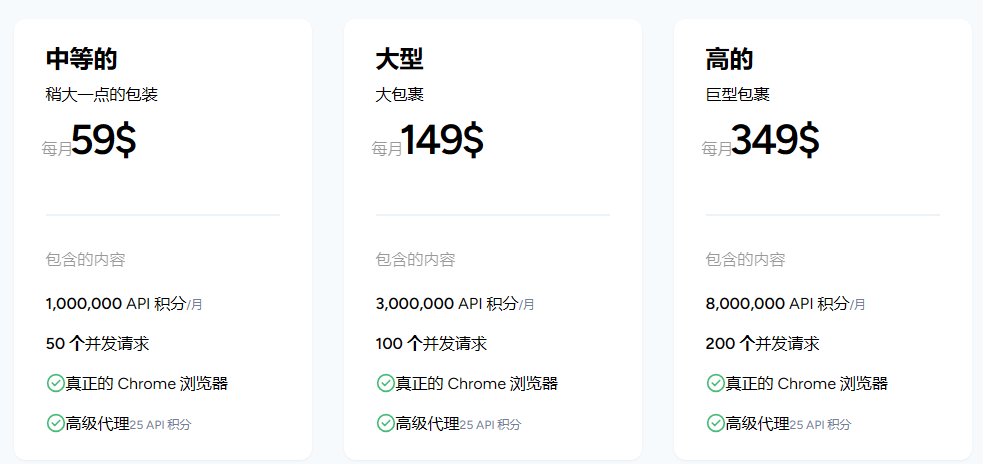
59$/月
去服务商官网采购>
|
浏览次数
396
采购人数
2
试用次数
0
 SLA: N/A
响应: N/A
适用于个人&企业
SLA: N/A
响应: N/A
适用于个人&企业
收藏
×
完成
取消
×
书签名称
确定
|

- API详情
- 定价
- 使用指南
- 常见 FAQ
- 关于我们
- 相关推荐


什么是Scraperbox的网页内容提取?
"Scraperbox 网页内容提取"是一种基于真实Chrome浏览器环境的网页抓取服务,它使用高端旋转代理网络和一个巨大的浏览器池来确保用户能够顺利、高效地抓取各种网页内容,包括那些由JavaScript渲染的页面和设置了反爬虫机制的网站。

Scraperbox的网页内容提取有哪些核心功能?
- 网页数据抓取:能够从网站中提取文本、图片、链接等数据。
- 自定义抓取规则:用户可以根据自己的需求设置抓取规则,获取特定的数据。
- 数据导出:支持将抓取的数据导出为多种格式,如CSV、Excel等。
Scraperbox的网页内容提取的核心优势是什么?
网页搜罗使用我们的API执行一般的Web抓取任务,例如:
从电子商务网站获取产品数据 从航班获取价格数据 刮取评审数据 |
JavaScript脚本有时你需要点击一个按钮,等待一个元素出现,在表单中输入一些细节,等等。JavaScript脚本您能够容易地控制Chrome浏览器做任何你想做的事。
|
结构化数据提取从网页中获取HTML很酷,但使用我们的结构化数据提取API,您可以接收结构化JSON数据的数据。
|
截图使用我们的API截取任何页面的屏幕截图。我们支持全页4K高清截图,或特定元素的截图。 |




在哪些场景会用到Scraperbox的网页内容提取?
电子商务与市场竞争分析在电子商务领域,"Scraperbox 网页内容提取"API接口扮演着至关重要的角色。商家可以利用该接口从多个电商平台(如亚马逊、淘宝、京东等)抓取产品数据,包括价格、库存、销售排名、用户评价等信息。这些数据不仅能帮助商家进行实时价格比较,优化定价策略,还能分析竞争对手的产品线、市场趋势以及消费者偏好,从而制定更加精准的市场营销计划。此外,通过抓取用户评价,商家还能及时了解产品反馈,优化产品设计和提升用户体验。 |
 |
 |
旅行与旅游行业在旅行和旅游行业,"Scraperbox 网页内容提取"API接口同样具有广泛应用。旅行社、OTA(在线旅游代理商)以及旅游信息聚合平台可以利用该接口从各大航空公司、酒店预订网站和旅游论坛抓取航班信息、酒店价格、旅游路线、景点评价等数据。这些数据不仅有助于用户快速比较不同产品和服务,做出更加明智的旅行决策,还能为旅行社提供市场洞察,优化旅游产品组合,提升服务质量。同时,通过抓取用户评价和游记,平台还能构建更加丰富的旅游社区,增强用户粘性。 |
舆情监测与品牌管理在品牌管理和舆情监测方面,"Scraperbox 网页内容提取"API接口同样不可或缺。企业可以利用该接口从社交媒体、新闻网站、论坛等多个渠道抓取关于自身品牌或产品的讨论内容,包括用户评价、媒体报道、舆论趋势等。通过对这些数据的分析,企业可以及时了解市场反馈,发现潜在危机,制定应对策略。同时,企业还能利用这些数据评估品牌知名度、美誉度和忠诚度,为品牌策略的调整和优化提供数据支持。 |
 |
 |
数据科学与机器学习在数据科学和机器学习领域,"Scraperbox 网页内容提取"API接口也发挥着重要作用。研究人员和开发者可以利用该接口从互联网上抓取大量结构化或半结构化数据,用于构建数据集、训练模型以及进行算法验证。这些数据可以来自各种领域和行业,如金融、医疗、教育等。通过对这些数据的分析和挖掘,研究人员可以发现新的规律和模式,推动数据科学和机器学习技术的不断发展。 |
内容聚合与分发平台对于内容聚合与分发平台而言,"Scraperbox 网页内容提取"API接口同样具有重要意义。这些平台可以利用该接口从多个网站抓取新闻、文章、视频等内容,经过筛选、整合后分发给用户。这种方式不仅丰富了平台的内容资源,提升了用户体验,还为平台带来了更多的流量和广告收入。同时,通过抓取和分析用户行为数据,平台还能不断优化内容推荐算法,提高内容分发的精准度和效率。 |
|


我们的用户搜索Scraperbox。
我们帮助100多家公司获得他们需要的数据。您不必担心无头的Chrome浏览器、验证码和代理。Scraperbox为您处理一切
我们的用户搜索Scraperbox。
我们帮助100多家公司获得他们需要的数据。您不必担心无头的Chrome浏览器、验证码和代理。Scraperbox为您处理一切

