
 |
Komprehend命名实体识别
专用API
【更新时间: 2024.07.19】
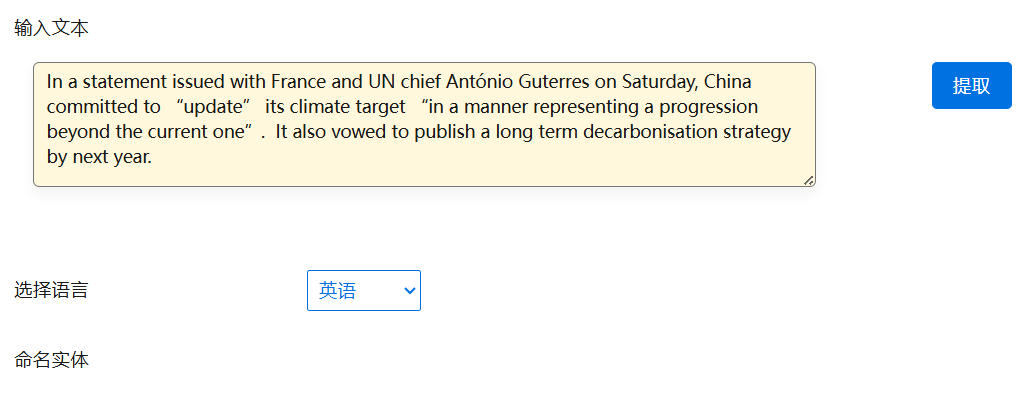
命名实体识别可以识别个人、公司、地点、组织、城市和 其他各类 的实体。API 可以从任何类型的文本、网页或社交媒体中提取此信息 网络。
咨询
去服务商官网采购>
|
浏览次数
33
采购人数
0
试用次数
0
 SLA: N/A
响应: N/A
适用于企业
SLA: N/A
响应: N/A
适用于企业
试用
收藏
×
完成
取消
×
书签名称
确定
|


- API详情
- 使用指南
- 关于我们
- 相关推荐


什么是Komprehend命名实体识别?
命名实体识别旨在将文本中的元素定位并分类为确定的 类别,例如 人名、组织、地点。它可以在任何类型的文本中提取此信息,它是一个网页, 新闻或社交媒体内容。
Komprehend命名实体识别有哪些核心功能?
1.实体识别技术概述
能够识别包括个人、公司、地点、组织、城市及其他多种类型的实体。这项技术通过分析文本内容,识别并分类文本中的关键信息,从而提取出具体
的实体名称。
2.数据来源与处理:
识别的API具备从各种文本、网页及社交媒体中提取信息的能力。这种API可以处理不同格式的数据,将输入的文本分解成更小的单元,以便进行深度
分析。
3.深度学习技术应用:
在命名实体识别中,深度学习技术用于确定字符分组的表示形式。这项技术将文本分解为词组,进一步将词分解为字符组,利用神经网络对这些数据
进行学习和模式识别。
4.算法原理与假设:
命名实体识别算法基于两个重要假设:一是单词的组成,即构成单词的音节和声音;二是单词的上下文环境,即与所考虑单词相邻的单词。这些因素
共同决定一个词是否被识别为专有名词。
Komprehend命名实体识别的核心优势是什么?
1.准确:Komprehend NER在CoNLL 2003测试数据集上取得了最先进的结果 0.9,召回率 0.92 和 F1 分数为 0.90。它使用字符和单词级嵌入,因
此不 回复 POS 标签 检测实体,这使得检测用户生成内容中的实体非常有用(尝试 “奥巴马是第三位 美国总统“在 Komprehend 和 Spacy)。
2.快:Komprehend NER不会查找像Freebase或DBPedia这样的词典来识别 实体和 因此,可以非常快速地满足各行业的需求。
3.定制:Komprehend NER可以用很少的训练示例进行定制,因此,它可以 适用于任何领域 数据。

在哪些场景会用到Komprehend命名实体识别?
 |
内容聚合和分类
一样, 组织和地点。了解每篇文章的相关实体有助于 自动分类 定义层次结构中的文章,并实现流畅的内容 发现。 |
|
客户支持服务
基于 其中提及的产品名称或位置名称。这样可以减少 支 持代理和他们 可以承担其他复杂的任务。 |
 |
安装
有关设置和安装说明,请访问我们的 Github 页面。具体来说,以下是我们每个客户端库的链接:
支持的语言及其语言代码列表
- 葡萄牙语(pt)
- 简体中文(在多语言关键字生成器 API 中不可用) (zh)
- 西班牙语
- 德语(de)
- 法语(fr)
- 荷兰语(nl)
- 意大利语(it)
- 日语(ja)
- 泰语(th)
- 丹麦语(da)
- 芬兰语(fi)
- 希腊语(el)
- 俄语(ru)
- 阿拉伯语(ar)
请确保替换为您的 API 密钥。
ParallelDots Text Analytics API 使用 API 密钥对 API 请求进行身份验证。请将您的 API 密钥作为参数 (api_key) 传递到我们的每个 API 中,以验证请求。
您可以通过注册 ParallelDots 帐户来注册新的 API 密钥。
/NER
发布
总结:命名为 Entitiy Extraction
描述:命名实体识别 (NER) 可以识别个人、公司、地点、组织、城市和其他 Stringious 类型的实体。API 接受 text、lang_code 和 api_key 作为三个参数,并返回包含实体、其类别(名称、地点或组织)和置信度分数的 json。 NER API 提供英语、西班牙语、荷兰语和德语版本。要在英语以外的滞后语言中使用 NER API,请以 lang_code 的形式传递一个额外的参数。
# For single sentence
curl -X POST -F 'text=Apple was founded by Steve Jobs.' -F 'lang_code=en' -F 'api_key=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' https://apis.paralleldots.com/v4/ner
# for multiple sentence as array
curl -X POST -F 'text=["Apple was founded by Steve Jobs.","Apple Inc. is an American multinational technology company headquartered in Cupertino, California"]' -F 'api_key=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' https://apis.paralleldots.com/v4/ner_batch
上面的命令返回结构如下的 JSON:
{
"entities": [
{
"category": "group",
"name": "Apple",
"confidence_score": 0.9758293629
},
{
"category": "name",
"name": "Steve Jobs",
"confidence_score": 0.8162289858
}
]
}
Batch Output -
{
"entities": [
[
{
"category": "group",
"name": "Apple",
"confidence_score": 0.9758293629
},
{
"category": "name",
"name": "Steve Jobs",
"confidence_score": 0.8162289858
}
],
[
{
"category": "group",
"name": "Apple Inc",
"confidence_score": 0.9203969538
},
{
"category": "place",
"name": "American",
"confidence_score": 0.9839514494
},
{
"category": "place",
"name": "Cupertino",
"confidence_score": 0.9463989735
},
{
"category": "place",
"name": "California",
"confidence_score": 0.8827401996
}
]
]
}
安装
有关设置和安装说明,请访问我们的 Github 页面。具体来说,以下是我们每个客户端库的链接:
支持的语言及其语言代码列表
- 葡萄牙语(pt)
- 简体中文(在多语言关键字生成器 API 中不可用) (zh)
- 西班牙语
- 德语(de)
- 法语(fr)
- 荷兰语(nl)
- 意大利语(it)
- 日语(ja)
- 泰语(th)
- 丹麦语(da)
- 芬兰语(fi)
- 希腊语(el)
- 俄语(ru)
- 阿拉伯语(ar)
请确保替换为您的 API 密钥。
ParallelDots Text Analytics API 使用 API 密钥对 API 请求进行身份验证。请将您的 API 密钥作为参数 (api_key) 传递到我们的每个 API 中,以验证请求。
您可以通过注册 ParallelDots 帐户来注册新的 API 密钥。
/NER
发布
总结:命名为 Entitiy Extraction
描述:命名实体识别 (NER) 可以识别个人、公司、地点、组织、城市和其他 Stringious 类型的实体。API 接受 text、lang_code 和 api_key 作为三个参数,并返回包含实体、其类别(名称、地点或组织)和置信度分数的 json。 NER API 提供英语、西班牙语、荷兰语和德语版本。要在英语以外的滞后语言中使用 NER API,请以 lang_code 的形式传递一个额外的参数。
# For single sentence
curl -X POST -F 'text=Apple was founded by Steve Jobs.' -F 'lang_code=en' -F 'api_key=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' https://apis.paralleldots.com/v4/ner
# for multiple sentence as array
curl -X POST -F 'text=["Apple was founded by Steve Jobs.","Apple Inc. is an American multinational technology company headquartered in Cupertino, California"]' -F 'api_key=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' https://apis.paralleldots.com/v4/ner_batch
上面的命令返回结构如下的 JSON:
{
"entities": [
{
"category": "group",
"name": "Apple",
"confidence_score": 0.9758293629
},
{
"category": "name",
"name": "Steve Jobs",
"confidence_score": 0.8162289858
}
]
}
Batch Output -
{
"entities": [
[
{
"category": "group",
"name": "Apple",
"confidence_score": 0.9758293629
},
{
"category": "name",
"name": "Steve Jobs",
"confidence_score": 0.8162289858
}
],
[
{
"category": "group",
"name": "Apple Inc",
"confidence_score": 0.9203969538
},
{
"category": "place",
"name": "American",
"confidence_score": 0.9839514494
},
{
"category": "place",
"name": "Cupertino",
"confidence_score": 0.9463989735
},
{
"category": "place",
"name": "California",
"confidence_score": 0.8827401996
}
]
]
}

