
 |
URL转换LLM服务-Jina
专用API
【更新时间: 2024.07.10】
URL 转换 LLM 服务-Jina,即 jina.ai,只需在其前面添加操作,就能够从 URL 或者网络搜索中顺利获取到对 LLM 友好的输入内容,能为相关需求提供极大的便利和高效支持,让数据的获取与处理变得轻松...
免费
去服务商官网采购>
|





- API详情
- 定价
- 使用指南
- 常见 FAQ
- 关于我们
- 相关推荐


什么是Jina的URL转换LLM服务?
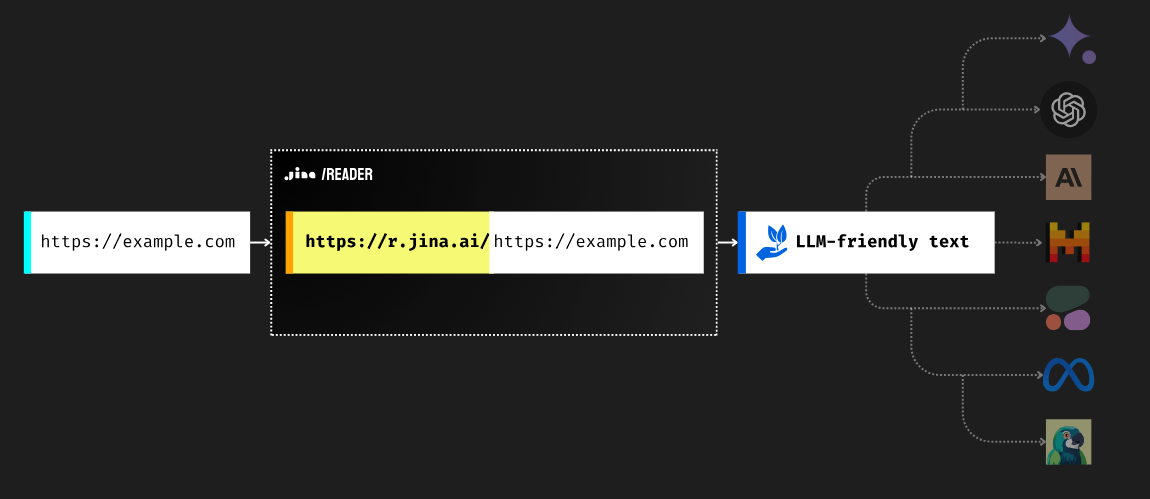
将网络信息输入LLM是打基础的重要一步,但它可能具有挑战性。最简单的方法是抓取网页并提供原始 HTML。然而,抓取可能很复杂并且经常被阻止,并且原始 HTML 中混杂着无关的元素,例如标记和脚本。 Reader API 通过从 URL 中提取核心内容并将其转换为干净、LLM 友好的文本来解决这些问题,从而确保代理和 RAG 系统的高质量输入。
什么是Jina的URL转换LLM服务?
Jina的URL转换LLM服务有哪些核心功能?
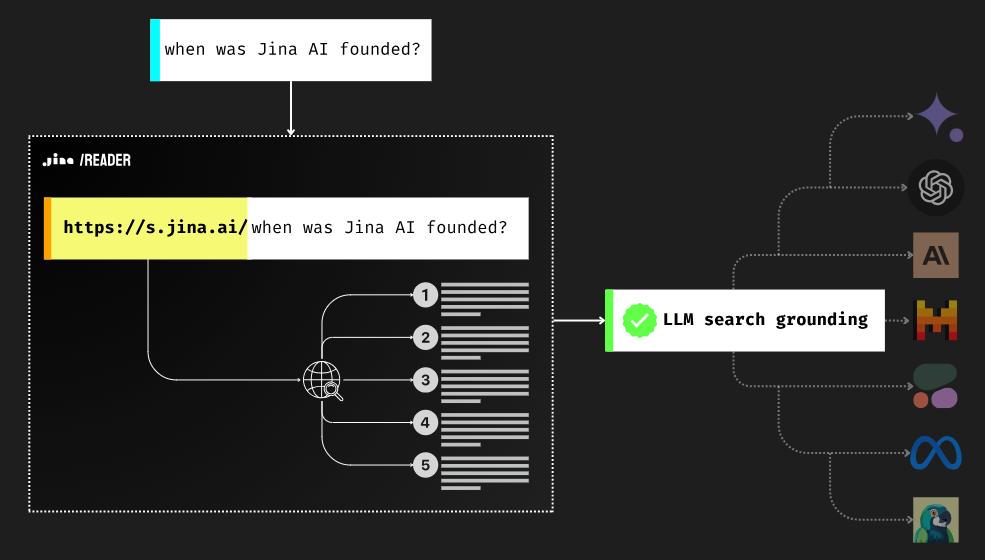
搜索基础阅读器LLM有知识限制,这意味着他们无法获取最新的世界知识。这会导致错误信息、过时的反应、幻觉和其他事实问题等问题。接地对于 GenAI 应用绝对重要。 Reader 允许您利用网络上的最新信息为您的法学硕士奠定基础。只需添加 |
 |
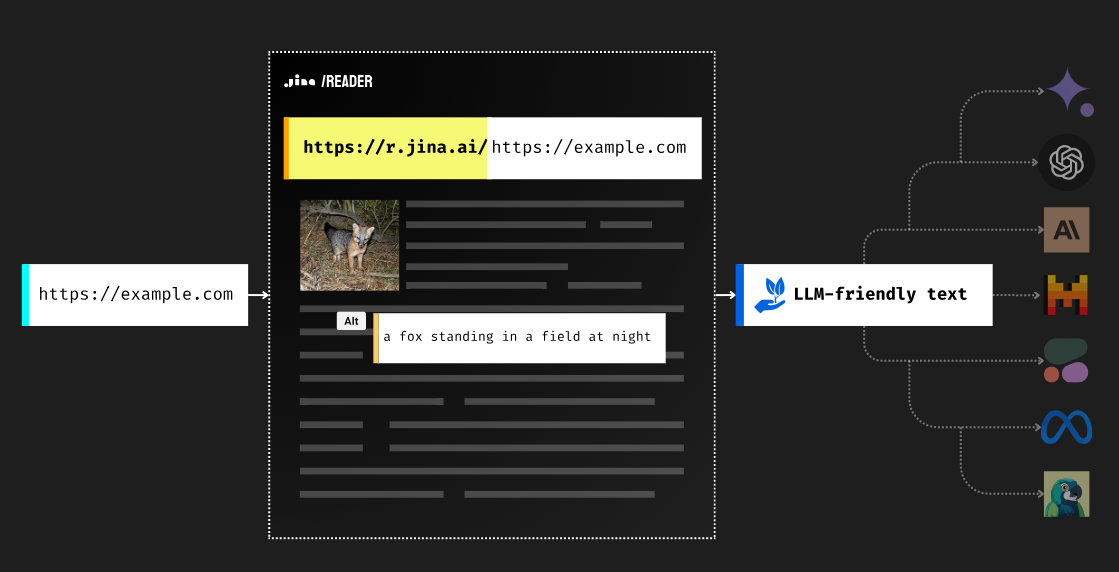 |
读者还可以阅读图像使用阅读器中的视觉语言模型自动为网页上的图像添加标题,并在输出中格式化为图像 alt 标签。这为您的下游LLM提供了足够的提示,将这些图像合并到其推理和总结过程中。这意味着您可以提出有关图像的问题、选择特定图像,甚至将其 URL 转发到更强大的 VLM 进行更深入的分析! |
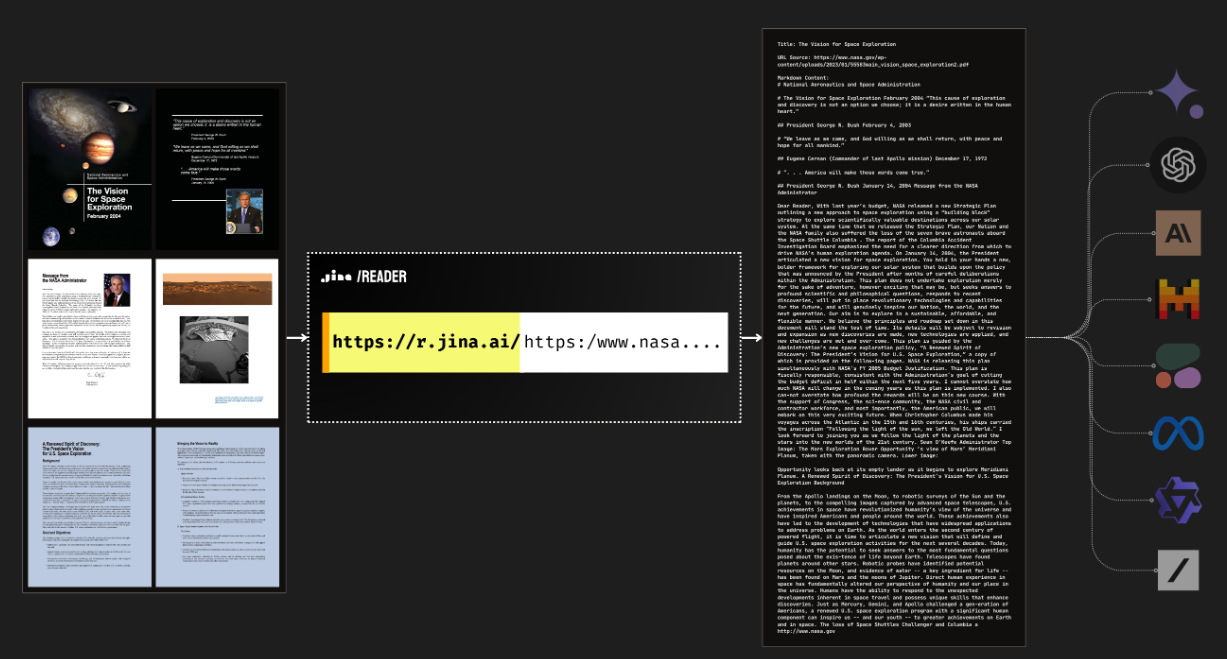
阅读器还可以阅读 PDF是的,Reader 本身就支持 PDF 阅读。它与大多数 PDF 兼容,包括那些包含许多图像的 PDF,而且速度快如闪电!与LLM相结合,您可以立即轻松构建 ChatPDF 或文档分析人工智能。 |
 |
Jina的URL转换LLM服务的核心优势是什么?
一流的图像转文本和视频转文本解决方案 |
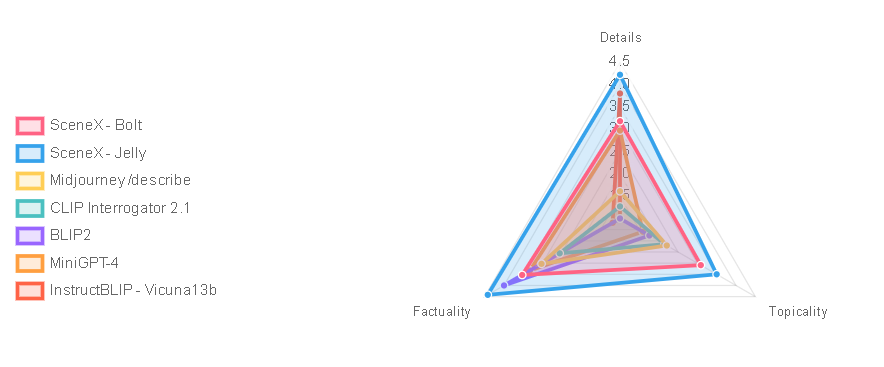
SceneXplain 是图像和视频字幕行业的巅峰之作。在利用大型语言模型的卓越架构的支持下,SceneXplain 擅长解读复杂的场景并传达详细的解释。它一次又一次地在关键指标上超越竞争对手,从捕捉微妙的视觉细微差别到提供引人入胜且连贯的字幕。虽然其他算法可能在特定领域表现出色,但 SceneXplain 在全面的图像和视频理解方面始终展现出无与伦比的专业知识。 |
||||||
|
通过自动生成替代文本简化图像可访问性通过生成描述性替代文本来增强图像的可访问性,让视障用户在线理解视觉内容。
|
||||||
构建视觉内容的文本输出定义您自己的 JSON 架构并从可视内容获取结构化 JSON 输出。此功能对于开发人员和系统集成商特别有用。 |
|
||||||
|
JSON 模式存储发现并共享可重用的 JSON 模式。通过 GUI 或 API 轻松创建、贡献和访问模式。立即探索!
|
||||||
|
该视频似乎是一个电视广告,讨论朝鲜的卫星并展示火箭发射。该广告采用了各种场景,描绘了穿着西装的个人讨论该主题的情况。视频最后,一群人聚集在讲台前,这可能表明朝鲜正在举行与卫星有关的会议或会议。 |
释放高级视频内容理解的力量此功能在媒体和娱乐行业特别有用,通过提供对视频内容的深入洞察来增强内容创建、编辑和观众参与度。
|
||||||
将图像转换为引人入胜的音频故事此功能在教育行业和数字营销行业中具有实用性,可以创造身临其境的学习体验和引人入胜的广告活动。
|
|
||||||
|
解锁图像中的文本阅读和理解此功能有利于监控、零售和社交媒体等行业,有助于基于图像的数据提取、产品识别和趋势分析。
|
||||||
掌握图像序列和面板的艺术通过促进对视觉叙事的更好理解,这可以改变出版业和图形设计师的游戏规则。
|
这部漫画的幽默之处在于,这个女孩被描绘成过于沉迷于社交媒体,以至于错过了享受户外活动的机会。阳光照射在她的笔记本电脑屏幕上,使她变得脾气暴躁,凸显了她所处处境的讽刺性。 |
||||||
 |
体验智能视觉问答能力该功能可实现更具交互性和视觉引导的问题解决,对于跨行业的客户支持服务非常有价值。
|
||||||
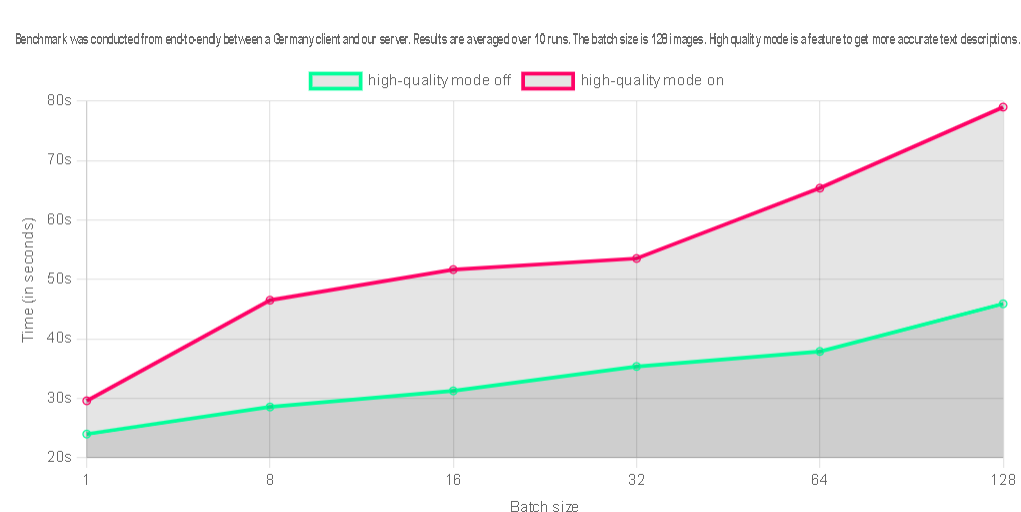
通过 API 进行快速批处理借助我们易于使用的 API,您可以一次性描述大量图像。根据您的订阅,您可以在 40 秒内批量描述最多 128 个图像。对于想要将 SceneXplain 集成到其应用程序、网站或服务中的商业用户来说,它是理想的选择。
|
|
||||||
|
|
ChatGPT 插件支持唯一可以为您的 ChatGPT 解锁多模式功能的插件。了解场景并利用这种理解来完成各种复杂的任务,例如选购外观。
|
||||||
|
|
|











在哪些场景会用到Jina的URL转换LLM服务?
 |
 |
 |
 |
|
标题图像
生成图像的文字描述。
|
替代文本生成
生成图像的替代文本
|
从图像中提取 JSON
使用预定义的架构从图像生成结构化 JSON 格式。这允许从图像中提取特定数据。
|
模式商店
发现并共享可重用的 JSON 模式。通过 GUI 或 API 轻松创建、贡献和访问模式。立即探索!
|
 |
 |
 |
|
|
视觉问答
根据图像内容回答查询。
|
总结视频
生成视频的简洁摘要,突出显示关键事件。
|
生成故事
根据图像创作一个故事,通常以人物的对话或独白为特色。
|
https://r.jina.ai/到代码或工具中需要 LLM 访问权限的任何 URL。这将以干净、LLM 友好的文本返回页面的主要内容。|
输入网址: https://example.com |
读者网址 https://r.jina.ai/https://example.com |
https://s.jina.ai/到您的查询。这将调用搜索引擎并返回前 5 个结果及其 URL 和内容,每个结果都以干净、LLM 友好的文本形式显示。|
输入查询 When was Jina AI founded? |
读者网址 https://s.jina.ai/When was Jina AI founded? |
|
2020年
成立于
|
36
雇员
|
5,000+
开发者赋能
|
400,000+
用户注册
|
Jina Al于 2020 年在柏林成立,是一家领先的搜索人工智能公司。我们提供搜索基础,它是 GenAl和多模式应用程序的核心。我们的使命是帮助企业和开发人员通过更好的搜索解锁多模式数据以创造价值。作为一家商业开源公司,我们喜欢开放式创新。
我们的任务
我们的方法
我们的价值
https://r.jina.ai/到代码或工具中需要 LLM 访问权限的任何 URL。这将以干净、LLM 友好的文本返回页面的主要内容。|
输入网址: https://example.com |
读者网址 https://r.jina.ai/https://example.com |
https://s.jina.ai/到您的查询。这将调用搜索引擎并返回前 5 个结果及其 URL 和内容,每个结果都以干净、LLM 友好的文本形式显示。|
输入查询 When was Jina AI founded? |
读者网址 https://s.jina.ai/When was Jina AI founded? |
|
2020年
成立于
|
36
雇员
|
5,000+
开发者赋能
|
400,000+
用户注册
|
Jina Al于 2020 年在柏林成立,是一家领先的搜索人工智能公司。我们提供搜索基础,它是 GenAl和多模式应用程序的核心。我们的使命是帮助企业和开发人员通过更好的搜索解锁多模式数据以创造价值。作为一家商业开源公司,我们喜欢开放式创新。

