








 该平台
该平台 云平台
云平台 自行部署
自行部署



Mistral AI 大型语言模型 (LLM )
我们发布开源和商业模型,为我们的开发者社区推动创新和便利。我们的模型具有最先进的多语言、代码生成、数学和高级推理功能。
开源
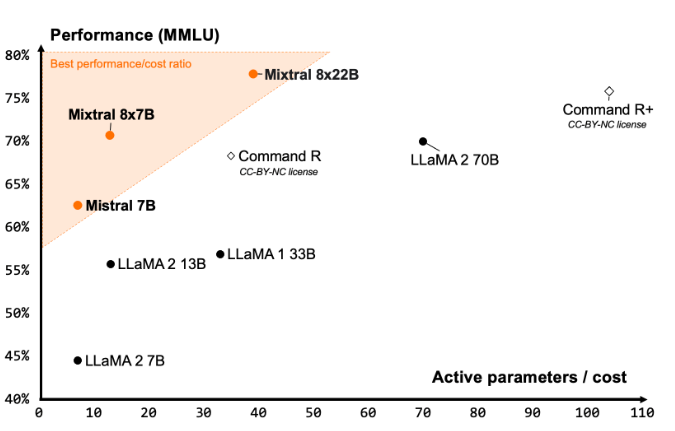
- Mistral 7b,我们的第一个密集模型,于2023 年 9 月发布
- Mixtral 8x7b,我们的第一个稀疏专家混合物,于2023 年 12 月发布
- Mixtral 8x22b,我们迄今为止最好的开源模型,于2024 年 4 月发布
商业
- Mistral Small,我们针对低延迟工作负载的经济高效的推理模型
- Mistral Medium,对于需要适度推理的中级任务很有用;请注意,该模型将在未来几个月内被弃用
- Mistral Large,我们用于高复杂性任务的顶级推理模型
- Mistral Embeddings,我们用于提取文本提取表示的最先进的语义
- Codestral,我们用于编码的尖端语言模型
对于我们的商业模式,我们一直在改进和迭代部署。在此处了解我们的模型版本控制的最新信息。
探索 Mistral AI API
Mistral AI API通过以下方式为 LLM 应用程序提供支持:
- 文本生成,支持流式传输并提供实时显示部分模型结果的能力
- 代码生成,支持代码生成任务,包括中间填充和代码完成
- Embeddings,对于 RAG 很有用,它将文本的含义表示为数字列表
- 函数调用,使 Mistral 模型能够连接到外部工具
- JSON模式,开发者可以将响应格式设置为json_object
- Guardrailing使开发人员能够在 Mistral 模型的系统级别实施策略

