
 |
AssemblyAI 流媒体语音到文本
专用API
【更新时间: 2024.07.12】
将实时音频流同步转换为文本,准确率接近90%,延迟600毫秒。同步转录对话、会议和现场活动,即时提升现场互动。
|
浏览次数
36
采购人数
2
试用次数
0
 SLA: N/A
响应: N/A
适用于个人&企业
SLA: N/A
响应: N/A
适用于个人&企业
试用
收藏
×
完成
取消
×
书签名称
确定
|


- API详情
- 定价
- 使用指南
- 常见 FAQ
- 关于我们
- 相关推荐


什么是AssemblyAI 流媒体语音到文本?
将实时音频流同步转换为文本,准确率接近 90%,延迟小于 600 毫秒。
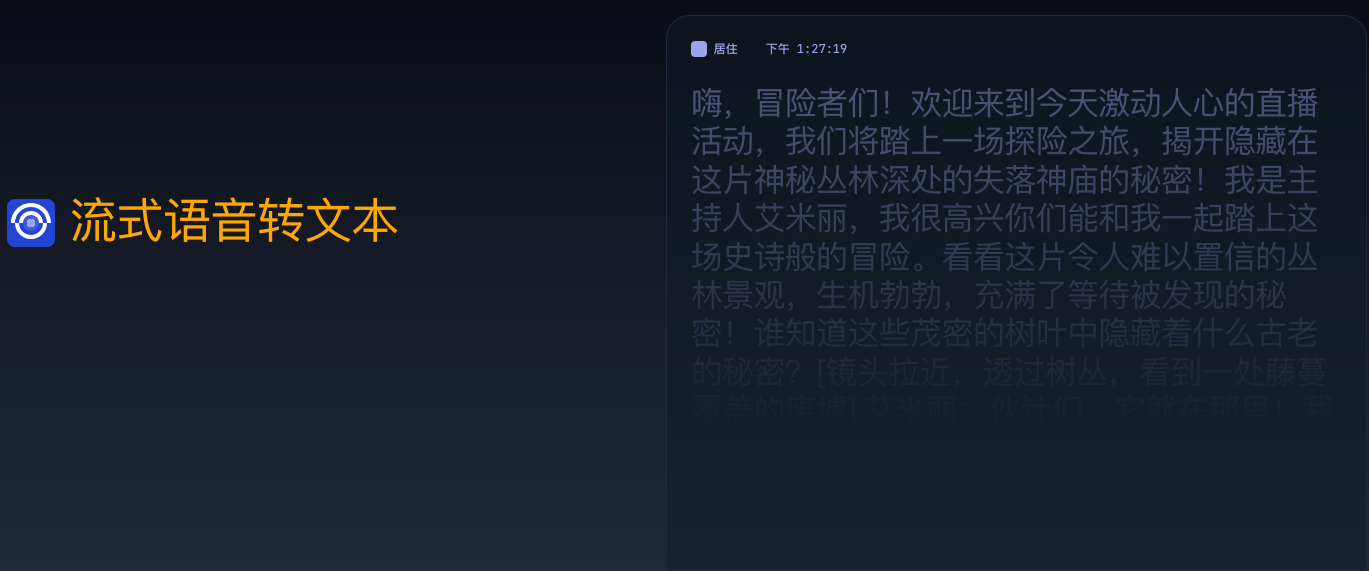
AssemblyAI 流媒体语音到文本有哪些核心功能?
1. 自动将现场音频转换为文本:同步转录对话、会议和现场活动,并立即提升现场互动。
2. 流式转录:以高精度、低延迟转录现场音频。
3. 自动标点和大小写:自动为转录文本添加专有名词的大小写和标点符号。
4. 自定义词汇:提高针对您的特定用例或产品所特有或定制的词汇的准确性。
5. ITN/格式化:自动将口头形式的文本转换为正确的书面格式,以提高文字记录的可读性。
6. 话语结束检测:自定义话语结束检测,以便更准确地检测一个说话者在流式语音转文本中何时结束话语。
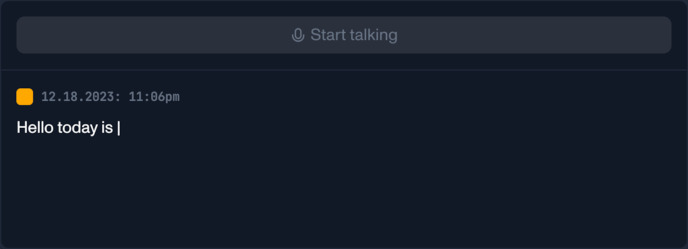
AssemblyAI 流媒体语音到文本的核心优势是什么?
 |
 |
 |
低延迟自动转录现场音频,几乎瞬间,与定制的端点控制。
|
行业领先的品质获得高度准确的结果。
|
高并发轻松处理大容量音频文件。
|
 |
 |
 |
|
自动添加大小写和标点符号的专有名词的转录文本。
|
每月更新和改进在我们的更新日志中查看每周的产品和准确性改进。 |
企业级安全性AssemblyAI致力于最高标准的安全实践,以确保您和您客户的数据安全。 |
在哪些场景会用到AssemblyAI 流媒体语音到文本?
1. 语音转文本
在市场上最准确的语音转文本模型的基础上构建,准确率达 92.5% 以上。

2. 语音理解
利用音频智能从语音数据中提取最大价值,并利用 LeMUR 发挥大型语言模型的作用。

步骤1:安装SDK
通过pip安装软件包:
步骤2:配置SDK
在这一步中,您将创建一个SDK客户端,并将其配置为使用您的API密钥。
-
浏览到“您的API密钥”下的文本,然后单击该文本以复制它。
-
使用您的API密钥创建新客户端。将
YOUR_API_KEY替换为复制的API密钥。
步骤3:提交音频进行转录
在此步骤中,您将提交音频文件进行转录,并等待转录完成。处理音频文件所需的时间取决于其持续时间和启用的模型。大多数的传输在45秒内完成。
-
指定要转录的音频的URL。URL需要可以从AssemblyAI的服务器访问。有关支持的格式列表,请参阅常见问题解答。不支持YouTube URL。如果你想转录YouTube视频,你需要先下载音频。
-
要生成转录本,请将音频URL传递到
transcribe()。这可能需要一分钟,而我们正在处理音频。
选择语音模型您可以选择要使用的模型类别,以实现最适合您的应用程序的成本-性能权衡。请参见选择语音模型。
-
如果转录失败,转录的
status将被设置为error。要查看失败的原因,您可以打印error的值。 -
打印完整的成绩单。
-
运行应用程序并等待它完成。
您已成功转录第一个音频文件。中可以查看所有已提交的转录作业。
步骤4:启用其他AI模型
通过使用转录选项启用我们的任何AI模型,您可以从音频中提取更多见解。在这一步中,您将启用Speaker diarization模型来检测谁说了什么。
-
创建一个
TranscriptionConfig,将speaker_labels设置为True,然后将其作为第二个参数传递给transcribe()。 -
除了完整的文字记录外,您现在还可以访问每个发言者的发言。
合作客户
步骤1:安装SDK
通过pip安装软件包:
步骤2:配置SDK
在这一步中,您将创建一个SDK客户端,并将其配置为使用您的API密钥。
-
浏览到“您的API密钥”下的文本,然后单击该文本以复制它。
-
使用您的API密钥创建新客户端。将
YOUR_API_KEY替换为复制的API密钥。
步骤3:提交音频进行转录
在此步骤中,您将提交音频文件进行转录,并等待转录完成。处理音频文件所需的时间取决于其持续时间和启用的模型。大多数的传输在45秒内完成。
-
指定要转录的音频的URL。URL需要可以从AssemblyAI的服务器访问。有关支持的格式列表,请参阅常见问题解答。不支持YouTube URL。如果你想转录YouTube视频,你需要先下载音频。
-
要生成转录本,请将音频URL传递到
transcribe()。这可能需要一分钟,而我们正在处理音频。
选择语音模型您可以选择要使用的模型类别,以实现最适合您的应用程序的成本-性能权衡。请参见选择语音模型。
-
如果转录失败,转录的
status将被设置为error。要查看失败的原因,您可以打印error的值。 -
打印完整的成绩单。
-
运行应用程序并等待它完成。
您已成功转录第一个音频文件。中可以查看所有已提交的转录作业。
步骤4:启用其他AI模型
通过使用转录选项启用我们的任何AI模型,您可以从音频中提取更多见解。在这一步中,您将启用Speaker diarization模型来检测谁说了什么。
-
创建一个
TranscriptionConfig,将speaker_labels设置为True,然后将其作为第二个参数传递给transcribe()。 -
除了完整的文字记录外,您现在还可以访问每个发言者的发言。
合作客户

