文件存储HDFS
通用API
【更新时间: 2024.03.29】
HDFS(Hadoop Distributed File System)是一种分布式文件系统,专为大规模数据存储与处理而设计。
|
浏览次数
74
采购人数
0
试用次数
0
 适用于个人&企业
适用于个人&企业
收藏
×
完成
取消
×
书签名称
确定
|


- 详情介绍
- 常见 FAQ
- 相关推荐


什么是文件存储HDFS?
"文件存储HDFS",即Hadoop分布式文件系统,是专为应对大数据挑战而设计的存储解决方案。它构成了Hadoop生态系统的核心,通过分布式架构和一系列优化技术,实现了对海量数据的高效、可靠、低成本存储。HDFS不仅能够支持PB级的数据量,还通过数据冗余机制确保了数据的高可用性和容错性,即使在硬件故障的情况下也能保证数据的完整性和可访问性。
该文件系统特别适合于处理大规模数据集上的批量操作,如MapReduce作业,它通过减少磁盘寻道时间、优化数据本地化等技术手段,提供了极高的数据吞吐率。这种特性使得HDFS成为大数据处理、数据湖分析以及机器学习等应用场景中不可或缺的一部分。
在大数据处理方面,HDFS作为底层存储系统,支持MapReduce、Spark等大数据处理框架对海量数据进行分布式处理,加速了数据处理的速度和效率。对于数据湖分析,HDFS提供了灵活的存储解决方案,允许企业以低成本存储各种类型的数据,并通过高级分析工具进行深入的洞察和决策支持。而在机器学习领域,HDFS则成为存储训练数据集、模型参数等关键数据的理想选择,支持分布式机器学习框架进行高效的模型训练和推理。

文件存储HDFS有哪些核心功能?
|
数据加速 |
多场景支持 |
|
数据管理 |
私有化部署 |




文件存储HDFS的技术原理是什么?
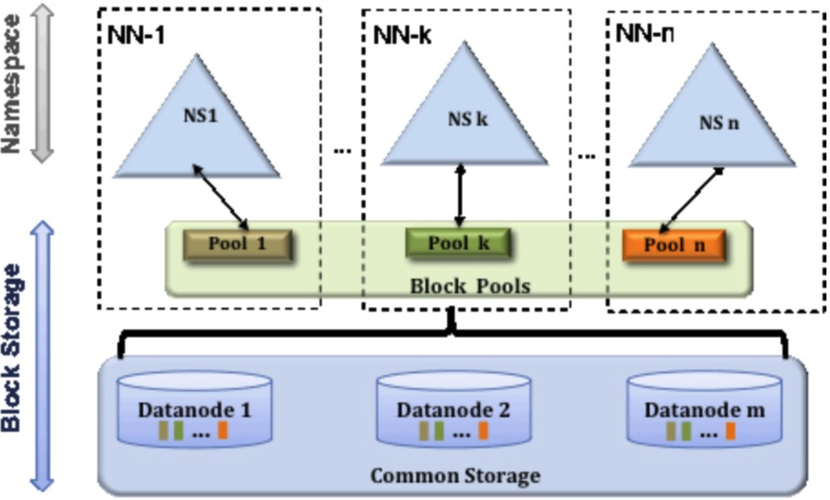
- 分布式存储:
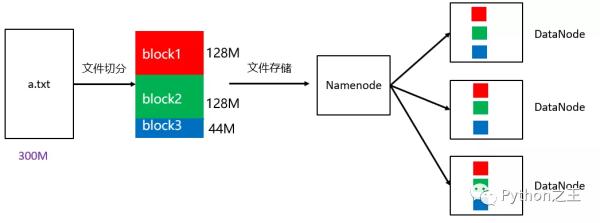
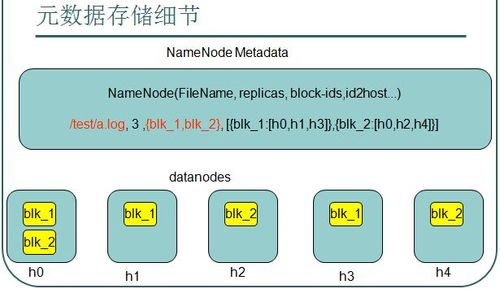
- HDFS将大文件分割成多个固定大小的块(通常为64MB或128MB),这些块是HDFS文件系统中的最小存储单元。
- 每个块都有多个副本(通常是3个),它们被存储在不同的数据节点上,以防止单点故障和数据丢失。
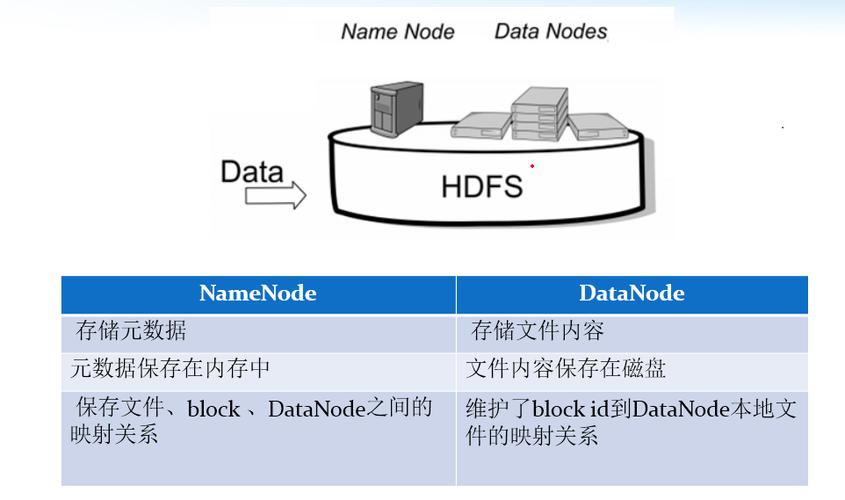
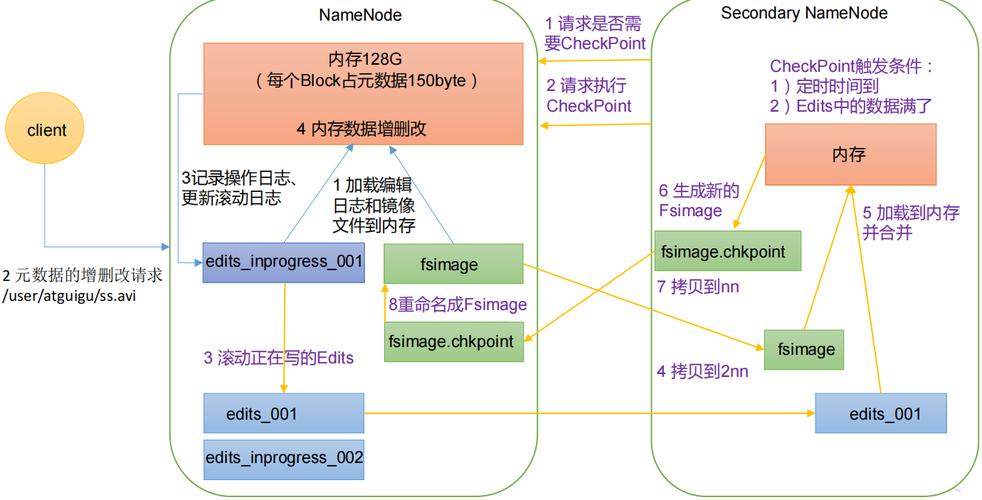
- 文件的元数据(包括文件名、文件大小、块列表等信息)存储在名称节点(NameNode)上,它维护了文件系统的目录树和文件到数据块的映射关系。
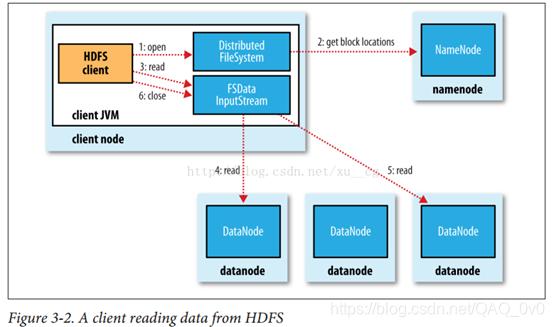
- 数据访问与处理:
- 当客户端需要读取或写入文件时,它会向NameNode发送请求,NameNode会返回包含文件块位置信息的列表。
- 客户端根据返回的位置信息,直接从相应的DataNode中读取或写入数据块。
- HDFS支持高吞吐量的数据访问,通过优化数据本地性和减少磁盘寻道时间来提高性能。
- 容错与可靠性:
- HDFS通过数据冗余和容错机制来保证数据的安全性和可靠性。当某个DataNode失效时,系统会自动将该DataNode上的块副本复制到其他DataNode上,以实现数据的自动故障恢复。
- HDFS还提供了数据校验和等机制来检测数据损坏,并在必要时进行修复。
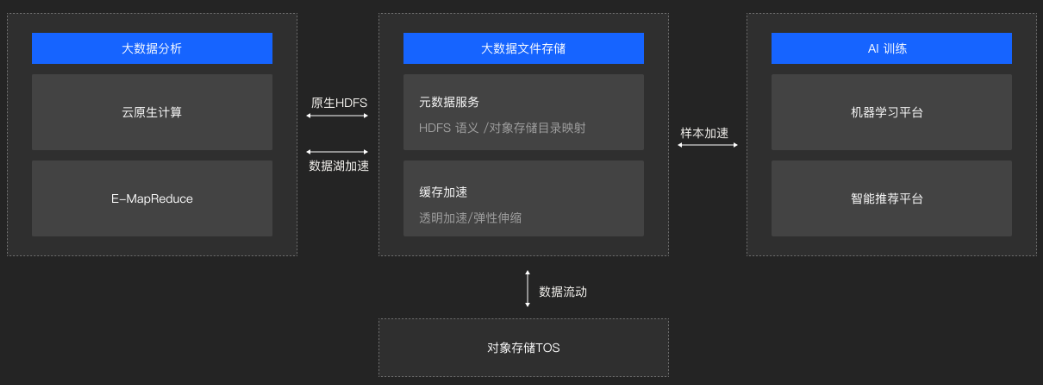
文件存储HDFS的核心优势是什么?
 |
 |
 |
|
标准API接口 |
服务商账号统一管理 |
零代码集成服务商 |
 |
 |
 |
|
智能路由
|
服务扩展 服务扩展不仅提供特性配置和归属地查询等增值服务,还能根据用户需求灵活定制解决方案,满足多样化的业务场景,进一步提升用户体验和满意度。
|
可视化监控 |
在哪些场景会用到文件存储HDFS?
1. 大数据存储
HDFS作为Hadoop生态系统的核心组件之一,主要用于存储大规模数据集。它能够支持PB级别的数据存储需求,满足大型企业和互联网公司对于海量数据存储的迫切需求。在这些场景中,HDFS的API接口被用于数据的上传、下载、查询和管理等操作,确保数据的安全性和可靠性。
2. 数据分析与挖掘
HDFS提供高可靠性和高性能的数据存储解决方案,非常适合用于数据分析、数据挖掘等大数据处理任务。许多企业通过HDFS存储数据,并使用Hadoop等框架进行数据分析。在这些场景中,HDFS的API接口被用于读取存储在HDFS上的数据,并将其提供给数据分析工具或算法进行处理。通过API接口,用户可以轻松地访问和管理存储在HDFS上的数据,从而支持复杂的数据分析任务。
3. 日志处理
许多应用程序会生成大量的日志数据,这些日志数据对于系统的监控、故障排查和性能优化至关重要。HDFS可以作为日志存储的解决方案,支持大规模、高并发的日志处理需求。通过HDFS的API接口,用户可以实时地将日志数据上传到HDFS中,并利用Hadoop等框架对日志数据进行分析和处理。这种方式不仅提高了日志处理的效率,还降低了存储成本。
4. 数据备份与恢复
HDFS提供数据冗余和容错机制,能够保证数据的安全性和可靠性。因此,许多企业会选择使用HDFS作为数据备份和恢复的解决方案。在这些场景中,HDFS的API接口被用于数据的备份和恢复操作。通过API接口,用户可以轻松地将数据从本地或远程存储系统备份到HDFS中,并在需要时从HDFS中恢复数据。这种方式不仅简化了数据备份和恢复的流程,还提高了数据的可靠性和可用性
5. 图像处理与视频分析
HDFS可以存储大量的图像和视频数据,适合用于图像处理、图像识别和视频分析等任务。在这些场景中,HDFS的API接口被用于读取存储在HDFS上的图像和视频数据,并将其提供给图像处理或视频分析算法进行处理。通过API接口,用户可以高效地访问和管理存储在HDFS上的图像和视频数据,从而支持复杂的图像处理和视频分析任务。
6. 实时数据处理
HDFS可以与其他组件(如Apache Kafka、Apache Storm等)结合使用,支持实时数据处理需求。在这些场景中,HDFS的API接口被用于实时数据的存储和查询。通过API接口,用户可以将实时数据流式传输到HDFS中,并利用Hadoop等框架对实时数据进行处理和分析。这种方式不仅提高了实时数据处理的效率,还降低了处理成本。
7. 机器学习与深度学习
在机器学习和深度学习领域,HDFS同样发挥着重要作用。许多机器学习和深度学习算法需要使用大量的训练数据来训练模型。通过HDFS的API接口,用户可以轻松地将训练数据上传到HDFS中,并利用分布式计算框架(如TensorFlow、PyTorch等)进行模型训练。这种方式不仅提高了模型训练的效率,还降低了训练成本。
一、硬件层面
- 使用高效稳定的硬件:
- 确保集群中的服务器、存储设备、网络设备等硬件组件具备高可靠性和稳定性。
- 考虑使用SSD(固态硬盘)替代传统的HDD(机械硬盘),以提高读写速度和降低延迟,从而提升整体性能。
- 冗余硬件配置:
- 部署冗余的电源、风扇、网络交换机等关键硬件组件,以防止单点故障导致整个系统不可用。
二、软件与配置层面
- 优化HDFS配置:
- 根据实际负载和数据特性调整HDFS的配置参数,如块大小、副本数量、心跳间隔等。
- 适当增加数据块的副本数量可以提高数据的可靠性和容错能力,但也要考虑存储成本和性能影响。
- 使用数据压缩:
- 在存储和传输数据时采用压缩算法(如LZO、Snappy等),以减少数据大小,提高存储效率和传输速度。
- 启用数据校验:
- HDFS支持CRC32等校验和机制,用于验证数据块的完整性。确保在文件创建时生成校验和,并在读取时验证校验和,以发现潜在的数据损坏。
三、数据备份与恢复
- 数据备份策略:
- 制定合理的数据备份策略,确保关键数据有多个副本存储在不同的节点或位置。
- 利用HDFS的冗余副本机制,确保数据在节点故障时能够自动恢复。
- 数据恢复能力:
- 引入纠删码(Erasure Coding)技术,如Reed-Solomon和Cauchy等算法,以在数据块丢失时从其他数据块中恢复数据。
- 定期验证数据备份的完整性和可用性,确保在需要时能够迅速恢复数据。
四、系统监控与管理
- 实时监控与告警:
- 部署监控系统,实时监控HDFS集群的状态、性能、负载等指标。
- 设置告警阈值,当集群状态异常或性能指标超出阈值时及时发出告警通知。
- 定期维护与升级:
- 定期对HDFS集群进行维护,包括清理垃圾数据、优化存储布局、更新软件版本等。
- 关注Hadoop社区和官方发布的更新和补丁,及时将集群升级到最新版本以修复已知的安全漏洞和性能问题。
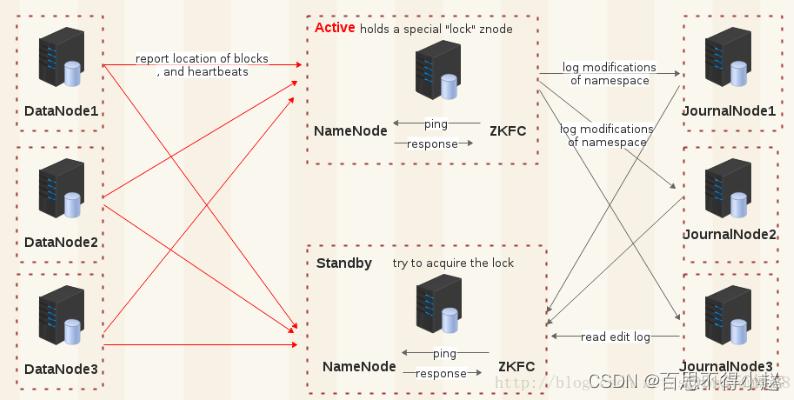
五、高可用性与容错性
- NameNode高可用:
- 部署NameNode高可用(HA)架构,使用两个或多个NameNode实例,一主一备或多主多备模式,确保在主NameNode故障时能够迅速切换到备用NameNode。
- 机架感知与数据布局:
- 利用HDFS的机架感知能力,优化数据块的存储布局,以提高数据访问的带宽利用率和容错能力。
- 快照与回收站:
- 使用HDFS的快照功能,定期为重要数据创建快照,以便在需要时恢复数据到特定时间点的状态。
- 启用回收站功能,为删除的文件提供临时存储空间,以便在误删除时能够迅速恢复数据。
